This is Section 1.2 of my report “Scheming AIs: Will AIs fake alignment during training in order to get power?”. There’s also a summary of the full report here (audio here). The summary covers most of the main points and technical terms, and I’m hoping that it will provide much of the context necessary to understand individual sections of the report on their own.
Audio version of this section here.
Other models training might produce
I'm interested, in this report, in the likelihood that training advanced AIs using fairly baseline ML methods (for example, of the type described in Cotra (2022)) will give rise, by default, to schemers – that is, to agents who are trying to get high reward on the episode specifically in order to get power for themselves (or for other AIs) later. In order to assess this possibility, though, we need to have a clear sense of the other types of models this sort of training could in principle produce. In particular: terminal training-gamers, and agents that aren't playing the training-game at all. Let's look at each in turn.
Terminal training-gamers (or, "reward-on-the-episode seekers")
As I said above, terminal training-gamers aim their optimization at the reward process for the episode because they intrinsically value performing well according to some part of that process, rather than because doing so serves some other goal. I'll also call these "reward-on-the-episode seekers." We discussed these models above, but I'll add a few more quick clarifications.
First, as many have noted (e.g. Turner (2022) and Ringer (2022)), goal-directed models trained using RL do not necessarily have reward as their goal. That is, RL updates a model's weights to make actions that lead to higher reward more likely, but that leaves open the question of what internal objectives (if any) this creates in the model itself (and the same holds for other sorts of feedback signals). So the hypothesis that a given sort of training will produce a reward-on-the-episode seeker is a substantive one (see e.g. here for some debate), not settled by the structure of the training process itself.
- That said, I think it's natural to privilege the hypothesis that models trained to produce highly-rewarded actions on the episode will learn goals focused on something in the vicinity of reward-on-the-episode. In particular: these sorts of goals will in fact lead to highly-rewarded behavior, especially in the context of situational awareness.[1] And absent training-gaming, goals aimed at targets that can be easily separated from reward-on-the-episode (for example: "curiosity") can be detected and penalized via what I call "mundane adversarial training" below (for example, by putting the model in a situation where following its curiosity doesn't lead to highly rewarded behavior).
Second: the limitation of the reward-seeking to the episode is important. Models that care intrinsically about getting reward in a manner that extends beyond the episode (for example, "maximize my reward over all time") would not count as terminal training-gamers in my sense (and if, as a result of this goal, they start training-gaming in order to get power later, they will count as schemers on my definition). Indeed, I think people sometimes move too quickly from "the model wants to maximize the sort of reward that the training process directly pressures it to maximize" to "the model wants to maximize reward over all time."[2] The point of my concept of the "episode" – i.e., the temporal unit that the training process directly pressures the model to optimize – is that these aren't the same. More on this in section 2.2.1 below.
Finally: while I'll speak of "reward-on-the-episode seekers" as a unified class, I want to be clear that depending on which component of the reward process they care about intrinsically, different reward-on-the-episode seekers might generalize in very different ways (e.g., trying specifically to manipulate sensor readings, trying to manipulate human/reward-model evaluations, trying specifically to alter numbers stored in different databases, etc). Indeed, I think a ton of messy questions remain about what to expect from various forms of reward-focused generalization (see footnote for more discussion[3]), and I encourage lots of empirical work on the topic. For present purposes, though, I'm going to set such questions aside.
Models that aren't playing the training game
Now let's look at models that aren't playing the training game: that is, models that aren't aiming their optimization specifically at the reward process (whether terminally, or instrumentally). We can distinguish between two ways this can happen:
-
either a model is pursuing what I'll call the "specified goal" (I'll call this sort of model a "training saint"),
-
or its pursuing some other goal (I'll call this a "proxy goal"), but still not training-gaming (I'll call this sort of model a "misgeneralized non-training-gamer").
Let's look at each in turn.
Training saints
Training saints are pursuing the "specified goal." But what do I mean by that? It's not a super clean concept, but roughly, I mean the "thing being rewarded" (where this includes: rewarded in counterfactual scenarios that hold the reward process fixed). Thus, for example, if you're training an AI to get gold coins on the episode, by rewarding it for getting gold coins on the episode, then "getting gold coins on the episode" is the specified goal, and a model that learns the terminal objective "get gold coins on the episode" would be a training saint.
(Admittedly, the line between "the reward process" and the "thing being rewarded" can get blurry fast. See footnote for more on how I'm thinking about it.)[4]
Like training gamers, training saints will tend to get high reward (relative to models with other goals but comparable capabilities), since their optimization is aimed directly at the thing-being-rewarded. Unlike training gamers, though, they aren't aiming their optimization at the reward process itself. In this sense, they are equivalent to widget-engineers who are just trying, directly, to engineer widgets of type A – where widgets of type A are also such that the performance review process will evaluate them highly – but who aren't optimizing for a good performance review itself.
(Note: the definition of "playing the training game" in Cotra (2022) does not clearly distinguish between models that aim at the specified goal vs. the reward process itself. But I think the distinction is important, and have defined training-gamers accordingly.[5])
Misgeneralized non-training-gamers
Let's turn to misgeneralized non-training-gamers.
Misgeneralized non-training-gamers learn a goal other than the specified goal, but still aren't training gaming. Here an example would be a model rewarded for getting gold coins on the episode, but which learns the objective "get gold stuff in general on the episode," because coins were the only gold things in the training environment, so "get gold stuff in general on the episode" performs just as well, in training, as "get gold coins in particular on the episode."
This is an example of what's sometimes called "goal misgeneralization"[6] or "inner misalignment"[7] – that is: a model learning a goal other than the specified goal. See e.g. Shah et al (2022) and Langosco et al (2021) for examples. Here the analogy would be: an employee who isn't actually trying to design the precise sort of widget that the company wants, and who is rather pursuing some other somewhat-different widget design, but whose performance happens to be evaluated highly anyway because the relevant widget designs happen to be similar enough to each other.
How do we tell training saints and misgeneralized non-training-gamers apart? It's not always going to be clean,[8] but the rough intuition is: training saints would get high reward in a wide variety of circumstances, provided that the reward process remains untampered with. By contrast, misgeneralized non-training-gamers get high reward much less robustly. For example, in the gold coin example, if you put these two models in an environment where it's much easier to get gold cupcakes than gold coins, but continue to use the same reward process (e.g., rewarding gold-coin-getting), the training saint (which wants gold coins) continues to pursue gold coins and to get high reward, whereas the misgeneralized non-training-gamer (which wants gold-stuff-in-general) goes for the gold cupcakes and gets lower reward.
Goal misgeneralization is sometimes closely associated with scheming (or with "deceptive alignment"), but the two are importantly distinct. For example, in the "easier to get gold cupcakes than gold coins" example just given, the model that seeks "gold stuff in general" has a misgeneralized goal, but it's not scheming. Rather, scheming would require it to understand the training process and training objective (e.g., gold coins), and to go for the gold coins as part of a strategy of seeking power for itself or other AIs.
Similarly: people sometimes point to the relationship between evolution and humans as an example of (or analogy for) goal misgeneralization (e.g., evolution selects for reproductive fitness, but human goals ended up keyed to other proxies like pleasure and status that can lead to less-than-optimally-reproductive behavior like certain types of condom use). But regardless of how you feel about this as an example of/analogy for goal misgeneralization, it's not, yet, an example of scheming (or of "deceptive alignment"). In particular: comparatively few humans are actively trying to have as many kids as possible (cf: condoms) as an explicit instrumental strategy for getting power-for-their-values later (some ideological groups do something like this, and we can imagine more of it happening in the future, but I think it plays a relatively small role in the story of evolutionary selection thus far).[9]
Contra "internal" vs. "corrigible" alignment
I also want to briefly note a distinction between model classes that I'm not going to spend much time on, but which other work on scheming/goal-guarding/"deceptive alignment" – notably, work by Evan Hubinger – features prominently: namely, the distinction between "internally aligned models" vs. "corrigibly aligned models."[10] As I understand it, the point here is to distinguish between AIs who value the specified goal via some kind of "direct representation" (these are "internally aligned"), vs. AIs who value the specified goal via some kind of "pointer" to that target that routes itself via the AI's world model (these are "corrigibly aligned").[11] However: I don't find the distinction between a "direct representation" and a "pointer" very clear, and I don't think it makes an obvious difference to the arguments for/against scheming that I'll consider below.[12] So, I'm going to skip it.[13]
The overall taxonomy
Overall, then, we have the following taxonomy of models:
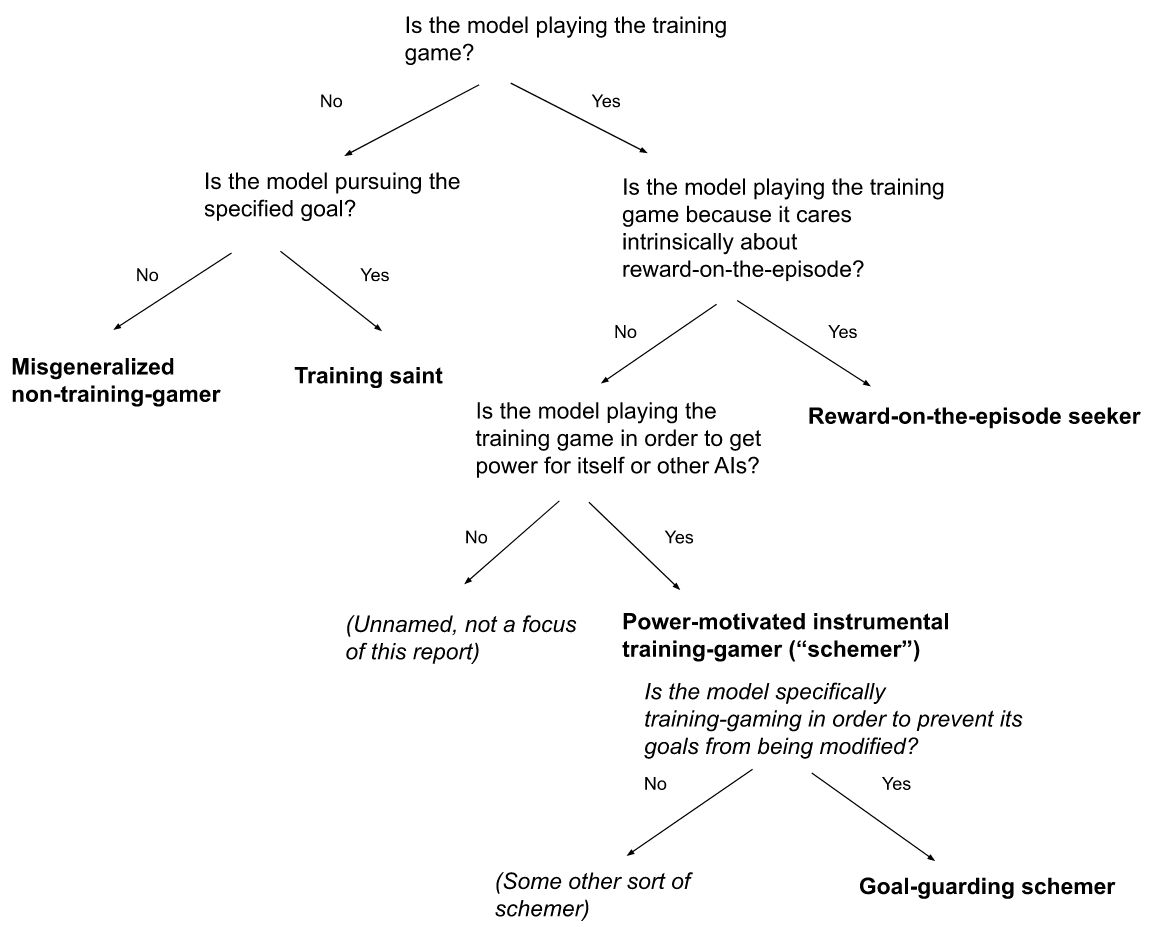
The overall taxonomy of model classes I'll focus on.
Note that in reality, a model's goal-system can (and plausibly will) mix these different motivations together (e.g., it might be partly pursuing the specified goal, partly reward-on-the-episode, partly something else entirely, etc). For simplicity, I'll often think in terms of a "pure" version of one of these models (e.g., a model that only cares about reward-on-the-episode), and I'm hoping that a greater focus on "mixed models" wouldn't alter my analysis in deep ways – and in particular, that the analysis applicable to a "pure model" will generally apply in roughly the same way to the corresponding part of a more mixed goal system as well (e.g., a model that cares somewhat about reward-on-the-episode, and somewhat about other things). I'll say a bit more about mixed models in section 1.3.5 below.
Depending on where we draw various lines, it seems possible for a model to value something in the vicinity of reward-on-the-episode, and to be a "reward-on-the-episode seeker" in that sense, while lacking other aspects of situational awareness, and without playing the training game is a very full-on way. For example, maybe it values something like "reward-on-the-episode," but misunderstands its overall situation in other fairly deep ways (e.g., as a silly example, maybe it thinks it is a giraffe rather than an AI). But when I talk about "reward-on-the-episode seekers" below I'll be assuming situational-awareness and training-gaming. ↩︎
For example, I think the discussion in Cotra (2022) isn't clear enough about this distinction. ↩︎
Even granted that in some sense the model cares about some component of the reward process, we can imagine further (somewhat conceptually hazy) distinctions between, for example:
- Actual vs. conditional rewards. That is, the model could care about the reward that will actually be given on the episode, vs. the reward that would be given conditional on the episode being selected for evaluation}. Thus, for example, the former might try to actively optimize for causing the episode to get included in training (assuming that not all episodes are), whereas the latter would not (see discussion between Ngo and Christiano here). Insofar as this behavior would be penalized by the training process, however (for example, because the model sometimes sacrifices reward in order to try to make the episode more likely to appear in training), we might think goals that give rise to it less likely.
- Fixed vs. changeable reward processes. Here the distinction is between a reward process that can't be altered going forward, vs. a reward process that can (thanks to Paul Christiano for discussion). Thus, for example, we can imagine a model trained in 2023 that learns the goal "behave such that your behavior would receive high reward according to the reward process used in 2023,'' and this goal persists even into 2024 (this would be a "fixed'' reward process). This contrasts with a model trained in 2024 that learns that goal "behave such that your behavior would receive high reward according to whatever reward process will in fact be used to evaluate it'' – where this process might change in 2024 in a manner the model would then have an incentive to predict and perhaps to manipulate (this would be a "changeable" reward process). Fixed reward processes have the advantage of reducing the incentive for the model (or for some other set of actors) to mess with the reward process, but my own current take is that they seem less likely than change-able reward processes, since to the extent that e.g. 2024 reward process differs from the 2023 one, a model that continues to optimize for the 2023 reward process in 2024 will get updated against.
- Concrete vs. platonic reward processes. This distinction is even hazier, but roughly speaking: we can also distinguish between models that learn to care about the output of some physical reward process happening in the real world, vs. models that learn to care about the output of some more abstract process – for example, what some hypothetical set of evaluators would think about its behavior. The fixed reward process just discussed – e.g., "what would the 2023 reward process think about this 2024 action'' – is an example of a platonic reward process: e.g., the 2023 reward process won't and cannot be run in 2024, but the model cares about what it "would say'' regardless. This different matters because a model that cares about a concrete reward process would have a relatively clear incentive to intervene on that process, whereas it is less clear what a model that cares about something more hypothetical would do (though we might still worry, in general, that whatever form this hypothetical-caring takes, it would still incentivize power-seeking for the usual reasons). In general, this all seems extremely messy – and we should be trying, as soon as possible, to leave the realm of this sort of hazy speculation and start gathering more empirical data about how models trained to seek reward tend to generalize.
Roughly, I'm thinking of the reward process as starting with the observation/evaluation of the model's behavior and its consequences (e.g., the process that checks the model's gold coin count, assigns rewards, updates the weights accordingly, etc); whereas the specified goal is the non-reward-process thing that the reward process rewards across counterfactual scenarios where it isn't tampered with (e.g., gold-coin-getting). Thus, as another example: if you have somehow created a near-perfect RLHF process, which rewards the model to the degree that it is (in fact) helpful, harmless, and honest (HHH), then being HHH is the specified goal, and the reward process is the thing that (perfectly, in this hypothetical) assesses the model's helpfulness, harmlessness, and honesty, assigns rewards, updates the weights, etc.
See Gao (2022) for a related breakdown. Here I'm imagining the reward process as starting with what Gao calls the "sensors." Sometimes, though, there won't be "sensors" in any clear sense, in which case I'm imagining the reward process starting at some other hazy point where the observation/evaluation process has pretty clearly begun. But like I said: blurry lines. ↩︎
For example, absent this distinction, the possibility of solving "outer alignment" isn't even on the conceptual table, because "reward" is always being implicitly treated like it's the specified goal. But also: I do just think there's an important difference between models that learn to get gold coins (because this is rewarded), and models that learn to care about the reward process itself. For example, the latter will "reward hack," but the former won't. ↩︎
See Shah et al (2022) and Langosco et al (2021). ↩︎
See Hubinger et al (2019). ↩︎
In particular: I doubt that an effort to identify a single, privileged "specified goal" will withstand much scrutiny. In particular: I think it will depend on how you carve out the "reward process" that you're holding fixed across counterfactuals. And screening off goals that lead to instrumental training-gaming is an additional challenge. ↩︎
We can imagine hypothetical scenarios that could resemble deceptive alignment more directly. For example, suppose that earth were being temporarily watched by intelligent aliens who wanted us to intrinsically value having maximum kids, and who would destroy the earth if they discovered that we care about something else (let's say that the destruction would take place 300 years after the discovery, such that caring about this requires at least some long-term values). And suppose that these aliens track birth rates as their sole method of understanding how much we value having kids (thanks to Daniel Kokotajlo for suggesting an example very similar to this). Would human society coordinate to keep birth rates adequately high? Depending on the details, maybe (though: I think there would be substantial issues in doing this, especially if the destruction of earth would take place suitably far in the future, and if the AIs were demanding birth rates of the sort created by everyone optimizing solely for having maximum kids). And to be a full analogy for deceptive alignment, it would also need to be the case that humans ended up with values motivating this behavior despite having been "evolved from scratch" by aliens trying to get us to value having-maximum-kids. ↩︎
In my opinion, Hubinger's use of the term "corrigibility" here fits poorly with its use in other contexts (see e.g. Arbital here). So I advise readers not to anchor on it. ↩︎
Hubinger's example here is: Jesus Christ is aligned with God because Jesus Christ just directly values what God values; whereas Martin Luther is aligned with God because Martin Luther values "whatever the Bible says to do." This example suggests a distinction like "valuing gold coins" vs. "valuing whatever the training process is rewarding," but this isn't clearly a contrast between a "direct representation" vs. a "pointer to something in the world model." For example, gold coins can be part of your world model, so you can presumably "point" at them as well. ↩︎
Are human goals, for example, made of "direct representations" or "pointers to the world model"? I'm not sure it's a real distinction. I'm tempted to say that my goals are structured/directed by my "concepts," and in that sense, by my world model (for example: when I value "pleasure," I also value "that thing in my world model called pleasure, whatever it is." But I'm not sure what the alternative is supposed to be.) And I'm not sure how to apply this distinction to a model trained to get gold coins. What's the difference between valuing gold coins via a direct representation vs. via a pointer?
In a comment on a previous draft of this report, Hubinger writes (shared with permission):
"Maybe something that will be helpful here: I basically only think about the corrigible vs. the deceptive case – that is, I think that goals will be closer to concepts, which I would describe as pointers to things in the world model, than direct representations essentially always by necessity. The internally aligned case is mostly only included in my presentations of this stuff for pedagogical reasons, since I think a lot of people have it as their default model of how things will go, and I want to very clearly argue that it's not a very realistic model."
But this doesn't clarify, for me, what a direct representation is. ↩︎
Another issue with Hubinger's ontology, from my perspective, is that he generally focuses only on contrasting internally aligned models, corrigibly aligned models, and deceptively aligned models – and this leaves no obvious room for reward-on-the-episode seekers. That is, if we imagine a training process that rewards getting gold coins, on Hubinger's ontology the goal options seem to be: direct-representation-of-gold-coins, pointer-to-gold-coins, or some beyond- episode goal that motivates instrumental training-gaming. Reward-on-the-episode isn't on the list.
On a previous draft of this report, Hubinger commented (shared with permission):
If you replace "gold coins" with "human approval", which is the case I care the most about, what I'm really trying to compare is "pointer-to-human-approval"/"concept of human approval" vs. "deception". And I guess I would say that "pointer-to-human-approval" is the most plausible sycophant/reward-maximizer model that you might get. So what I'm really comparing is the sycophant vs. the schemer, which means I think I am doing what you want me to be doing here. Though, note that I'm not really comparing at all to the saint, which is because doing that would require me to explicitly talk about the simplicity of the intended goal vs. the specified goal, which in most of these presentations isn't really something that I want to do.
Even granted that we're mostly interested in cases where human approval is part of the training process, I'm wary of assuming that it should be understood as the specified goal. Rather, I'm tempted to say that the thing-the-humans-are-approving-of (e.g., helpfulness, harmlessness, honesty, etc) is a more natural candidate, in the same sense that if the reward process rewards gold-coin-getting, gold coins are (on my ontology) the specified goal target. ↩︎