aogara
Bio
DPhil student in AI at Oxford, and grantmaking on AI safety at Longview Philanthropy.
Posts 39
Comments386
I think this kind of research will help inform people about the economic impacts of AI, but I don't think the primary benefits will be for forecasters per se. Instead, I'd expect policymakers, academics, journalists, investors, and other groups of people who value academic prestige and working within established disciplines to be the main groups that would learn from research like this.
I don't think most expert AI forecasters would really value this paper. They're generally already highly informed about AI progress, and might have read relatively niche research on the topic, like Ajeya Cotra and Tom Davidson's work at OpenPhil. The methodology in this paper might seem obvious to them ("of course firms will automate when it's cost effective!"), and its conclusions wouldn't be strong or comprehensive enough to change their views.
It's more plausible that future work building on this paper would inform forecasters. As you mentioned above, this work is only about computer vision systems, so it would be useful to see the methodology applied to LLMs and other kinds of AI. This paper has a relatively limited dataset, so it'd be good to see this methodology applied to more empirical evidence. Right now, I think most AI forecasters rely on either macro-level models like Davidson or simple intuitions like "we'll get explosive growth when we have automated remote workers." This line of research could eventually lead to a much more detailed economic model of AI automation, which I could imagine becoming a key source of information for forecasters.
But expert forecasters are only one group of people whose expectations about the future matter. I'd expect this research to be more valuable for other kinds of people whose opinions about AI development also matter, such as:
- Economists (Korinek, Trammell, Brynjolfsson, Chad Jones, Daniel Rock)
- Policymakers (Researchers at policy think tanks and staffers in political institutions who spend a large share of their time thinking about AI)
- Other educated people who influence public debates, such as journalists or investors
Media coverage of this paper suggests it may be influential among those audiences.
Mainly I think this paper will help inform people about the potential economic implications of AI development. These implications are important for people to understand because they contribute to AI x-risks. For example, explosive economic growth could lead to many new scientific innovations in a short period of time, with incredible upside but also serious risks, and perhaps warranting more centralized control over AI during that critical period. Another example would be automation: if most economic productivity comes from AI systems rather than human labor or other forms of capital, this will dramatically change the global balance of power and contribute to many existential risks.
I really liked MIT FutureTech's recent paper, "Beyond AI Exposure: Which Tasks are Cost-Effective to Automate with Computer Vision?" I think it's among the 10 best economics of AI papers I've read from the last few years. It proposes an economic model of the circumstances under which companies would automate human labor with AI.
Previously, some of the most cited papers on the potential impacts of AI automation used an almost embarrassingly simple methodology: surveys. They take a list of jobs or tasks, and survey people about whether they think AI could someday automate that job or task. That's it. For validation, they might cross reference different people's estimates. Their conclusion would be something like "according to our survey, people think AI could automate X% of jobs." This methodology has been employed by some of the highest profile papers on the potential economic impact of AI, including this paper in Science and this paper with >10K citations.
(Other papers ignore the micro-level of individuals tasks and firms, and instead model the macroeconomic adoption of AI. For example, Tom Davidson, Epoch, Phil Trammell, Anton Korinek, William Nordhaus, and Chad Jones have done research where they suppose that it's cost-effective for AI to automate a certain fraction of tasks. This macro-level modeling is also valuable, but by ignoring the choices of individual firms to automate individual tasks, they assume away a lot of real world complexity.)
The MIT FutureTech paper significantly improves upon the survey method by creating a mathematical model of what it would cost for a firm to automate a task with AI. The basic premise is that a firm will automate human labor with AI if the human labor is more expensive than AI automation would be. To estimate the cost of AI automation, they break down the costs of automation into the following parts:
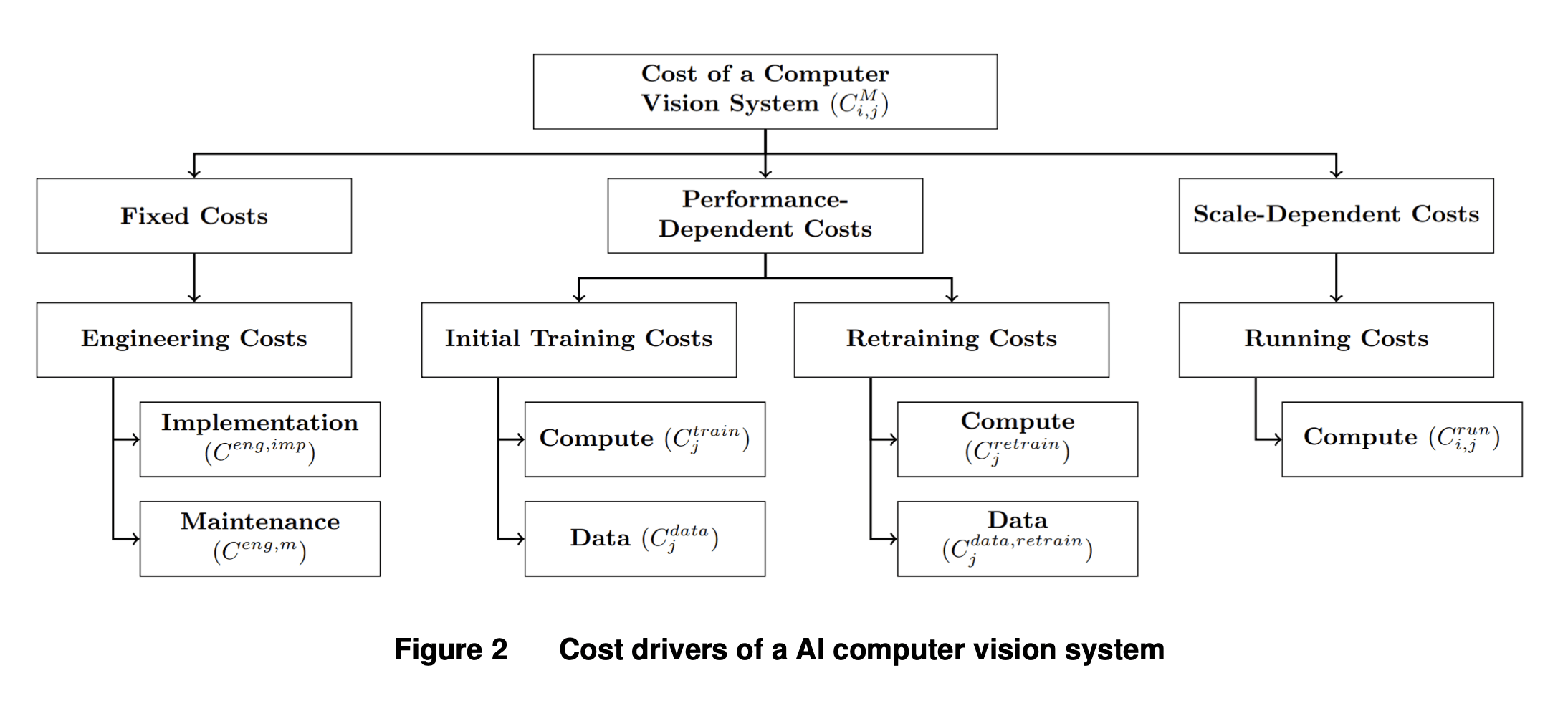
Then they estimate distributions for each of these parameters, and come up with an overall distribution for the cost of AI automation. They compare the distribution of AI automation costs to the distribution of human wages in tasks that could be automated, and thereby estimate which tasks it would be cost-effective to automate. This allows them to make conclusions like "X% of tasks would be cost-effective to automate."
There's a lot of detail to the paper, and there are plenty of reasonable critiques one could make of it. I don't mean to endorse the other sections or the bottom-line conclusions. But I think this is clearly the state of the art methodology for estimating firm-level adoption of AI automation, and I would be excited to see future work that refines this model or applies it to other domains.
More broadly, I've found lots of Neil Thompson's research informative, and I think FutureTech is one of the best groups working on the economics of AI. I am surprised at the size of the grant, as I'd tend to think economics research is pretty cheap to fund, but I don't know the circumstances here.
(Disclosure: Last summer I applied for an internship at MIT FutureTech.)
I agree there's a surprising lack of published details about this, but it does seem very likely that labs made some kind of commitment to pre-deployment testing by governments. However, the details of this commitment were never published, and might never have been clear.
Here's my understanding of the evidence:
First, Rishi Sunak said in a speech at the UK AI Safety Summit: “Like-minded governments and AI companies have today reached a landmark agreement. We will work together on testing the safety of new AI models before they are released." An article about the speech said: "Sunak said the eight companies — Amazon Web Services, Anthropic, Google, Google DeepMind, Inflection AI, Meta, Microsoft, Mistral AI and Open AI — had agreed to “deepen” the access already given to his Frontier AI Taskforce, which is the forerunner to the new institute." I cannot find the full text of the speech, and these are the most specific details I've seen from the speech.
Second, an official press release from the UK government said:
In a statement on testing, governments and AI companies have recognised that both parties have a crucial role to play in testing the next generation of AI models, to ensure AI safety – both before and after models are deployed.
This includes collaborating on testing the next generation of AI models against a range of potentially harmful capabilities, including critical national security, safety and societal harms.
Based on the quotes from Sunak and the UK press release, it seems very unlikely that the named labs did not verbally agree to "work together on testing the safety of new AI models before they are released." But given that the text of an agreement was never released, it's also possible that the details were never hashed out, and the labs could argue that their actions did not violate any agreements that had been made. But if that were the case, then I would expect the labs to have said so. Instead, their quotes did not dispute the nature of the agreement.
Overall, it seems likely that there was some kind of verbal or handshake agreement, and that the labs violated the spirit of that agreement. But it would be incorrect to say that they violated specific concrete commitments released in writing.
This seems to underrate the arguments for Malthusian competition in the long run.
If we develop the technical capability to align AI systems with any conceivable goal, we'll start by aligning them with our own preferences. Some people are saints, and they'll make omnibenevolent AIs. Other people might have more sinister plans for their AIs. The world will remain full of human values, with all the good and bad that entails.
But current human values are do not maximize our reproductive fitness. Maybe one human will start a cult devoted to sending self-replicating AI probes to the stars at almost light speed. That person's values will influence far-reaching corners of the universe that later humans will struggle to reach. Another human might use their AI to persuade others to join together and fight a war of conquest against a smaller, weaker group of enemies. If they win, their prize will be hardware, software, energy, and more power that they can use to continue to spread their values.
Even if most humans are not interested in maximizing the number and power of their descendants, those who are will have the most numerous and most powerful descendants. This selection pressure exists even if the humans involved are ignorant of it; even if they actively try to avoid it.
I think it's worth splitting the alignment problem into two quite distinct problems:
- The technical problem of intent alignment. Solving this does not solve coordination problems. There will still be private information and coordination problems after intent alignment is solved, therefore we'll still face coordination problems, fitter strategies will proliferate, and the world will be governed by values that maximize fitness.
- "Civilizational alignment"? Much harder problem to solve. The traditional answer is a Leviathan, or Singleton as the cool kids have been saying. It solves coordination problems, allowing society to coherently pursue a long-run objective such as flourishing rather than fitness maximization. Unfortunately, there are coordination problems and competitive pressures within Leviathans. The person who ends up in charge is usually quite ruthless and focused on preserving their power, rather than the stated long-run goal of the organization. And if you solve all the coordination problems, you have another problem in choosing a good long-run objective. Nothing here looks particularly promising to me, and I expect competition to continue.
You may have seen this already, but Tony Barrett is hiring an AI Standards Development Researcher. https://existence.org/jobs/AI-standards-dev
Nice! This is a different question, but I'd be curious if you have any thoughts on how to evaluate risks from BDTs. There's a new NIST RFI on bio/chem models asking about this, and while I've seen some answers to the question, most of them say they have a ton of uncertainty and no great solutions. Maybe reliable evaluations aren't possible today, but what would we need to build them?