
JWS 🔸
Bio
"EA-Adjacent" now I guess.
🔸 10% Pledger.
Likes pluralist conceptions of the good.
Dislikes Bay Culture being in control of the future.
Posts 11
Comments366
I responded well to Richard's call for More Co-operative AI Safety Strategies, and I like the call toward more sociopolitical thinking, since the Alignment problem really is a sociological one at heart (always has been). Things which help the community think along these lines are good imo, and I hope to share some of my own writing on this topic in the future.
Whether or not I agree with Richard's personal politics or not is kinda beside the point to this as a message. Richard's allowed to have his own views on things and other people are allowed to criticse this (I think David Mathers' comment is directionally where I lean too). I will say that not appreciating arguments from open-source advocates, who are very concerned about the concentration of power from powerful AI, has lead to a completely unnecessary polarisation against the AI Safety community from it. I think, while some tensions do exist, it wasn't inevitable that it'd get as bad as it is now, and in the end it was a particularly self-defeating one. Again, by doing the kind of thinking Richard is advocating for (you don't have to co-sign with his solutions, he's even calling for criticism in the post!), we can hopefully avoid these failures in the future.
On the bounties, the one that really interests me is the OpenAI board one. I feel like I've been living in a bizarro-world with EAs/AI Safety People ever since it happened because it seemed such a collosal failure, either of legitimacy or strategy (most likely both), and it's a key example of the "un-cooperative strategy" that Richard is concerned about imo. The combination of extreme action and ~0 justification either externally or internally remains completely bemusing to me and was big wake-up call for my own perception of 'AI Safety' as a brand. I don't think people can underestimate the second-impact effect this bad on both 'AI Safety' and EA, coming about a year after FTX.
Piggybacking on this comment because I feel like the points have been well-covered already:
Given that the podcast is going to have a tigher focus on AGI, I wonder if the team is giving any considering to featuring more guests who present well-reasoned skepticism toward 80k's current perspective (broadly understood). While some skeptics might be so sceptical of AGI or hostile to EA they wouldn't make good guests, I think there are many thoughtful experts who could present a counter-case that would make for a useful episode(s).
To me, this comes from a case for epistemic hygiene, especially given the prominence that the 80k podcast has. To outside observers, 80k's recent pivot might appear less as "evidence-based updating" and more as "surprising and suspicious convergence" without credible demonstrations that the team actually understands opposing perspectives and can respond to the obvious criticisms. I don't remember the podcast featuring many guests who present a counter-case to 80ks AGI-bullishness as opposed to marginal critiques, and I don't particularly remember those arguments/perspectives being given much time or care.
Even if the 80k team is convinced by the evidence, I believe that many in both the EA community and 80k's broader audience are not. From a strategic persuasion standpoint, even if you believe the evidence for transformative AI and x-risk is overwhelming, interviewing primarily those already also convinced within the AI Safety community will likely fail to persuade those who don't already find that community credible. Finally, there's also significant value in "pressure testing" your position through engagement with thoughtful critics, especially if your theory of change involves persuading people who are either sceptical themselves or just unconvinced.
Some potential guests who could provide this perspective (note, I don't these 100% endorse the people below, but just that they point the direction of guests that might do a good job at the above):
- Melanie Mitchell
- François Chollet
- Kenneth Stanley
- Tan Zhi-Xuan
- Nora Belrose
- Nathan Lambert
- Sarah Hooker
- Timothy B. Lee
- Krishnan Rohit
I don't really get the framing of this question.
I suspect, for any increment of time one could take through EAs existence, then there would have been more 'harm' done in the total rest of world during that time. EA simply isn't big enough to counteract the moral actions of the rest of the world. Wild animals suffer horribly, people die of preventable diseases etc constantly, formal wars and violent struggles occur affecting the lives of millions. There sheer scale of the world outweighs EA many, many times over.
So I suspect you're making a more direct comparison to Musk/DOGE/PEPFAR? But again, I feel like anyone wielding using the awesome executive power of the United States Government should expect to have larger impacts on the world than EA.
I think this is downstream of a lot of confusion about what 'Effective Altruism' really means, and I realise I don't have a good definition any more. In fact, because all of the below can be criticised, it sort of explains why EA gets seemingly infinite criticism from all directions.
- Is it explicit self-identification?
- Is it explicit membership in a community?
- Is it implicit membership in a community?
- Is it if you get funded by OpenPhilanthropy?
- Is it if you are interested or working in some particular field that is deemed "effective"?
- Is it if you believe in totalising utilitarianism with no limits?
- To always justify your actions with quantitative cost-effectiveness analyses where you're chosen course of actions is the top ranked one?
- Is it if you behave a certain way?
Because in many ways I don't count as EA based off the above. I certainly feel less like one than I have in a long time.
For example:
I think a lot of EAs assume that OP shares a lot of the same beliefs they do.
I don't know if this refers to some gestalt 'belief' than OP might have, or Dustin's beliefs, or some kind of 'intentional stance' regarding OP's actions. While many EAs shared some beliefs (I guess) there's also a whole range of variance within EA itself, and the fundamental issue is that I don't know if there's something which can bind it all together.
I guess I think the question should be less "public clarification on the relationship between effective altruism and Open Philanthropy" and more "what does 'Effective Altruism' mean in 2025?"
I mean I just don't take Ben to be a reasonable actor regarding his opinions on EA? I doubt you'll see him open up and fully explain a) who the people he's arguing with are or b) what the explicit change in EA to an "NGO patronage network" was with names, details, public evidence of the above, and being willing to change his mind to counter-evidence.
He seems to have been related to Leverage Research, maybe in the original days?[1] And there was a big falling out there, any many people linked to original Leverage hate "EA" with the fire of a thousand burning suns. Then he linked up with Samo Burja at Bismarck Analysis and also with Palladium, which definitely links him the emerging Thielian tech-right, kinda what I talk about here. (Ozzie also had a good LW comment about this here).
In the original tweet Emmett Shear replies, and then it's spiralled into loads of fractal discussions, and I'm still not really clear what Ben means. Maybe you can get more clarification in Twitter DMs rather than having an argument where he'll want to dig into his position publicly?
- ^
For the record, a double Leverage & Vassar connection seems pretty disqualifying to me - especially as i'm very Bay sceptical anyway
I think the theory of change here is that the Abundance Agenda taking off in the US would provide an ideological frame for the Democratic Party to both a) get competitive in the races in needs to win power in the Executive & Legislature and b) have a framing that allows it to pursue good policies when in power, which then unlocks a lot of positive value elsewhere
It also answers the 'why just the US?' question, though that seemed kind of obvious to me
And as for no cost-effectiveness calculation, it seems that this is the kind of systemic change many people in EA want to see![1] And it's very hard to get accurate cost-effectiveness-analyses from those. But again, I don't know if that's also being too harsh to OP, as many longtermist organisations don't seem to publicly publish their CEAs apart from general reasoning like about "the future could be very large and very good"
- ^
Maybe it's not the exact flavour/ideology they want to see, but it does seem 'systemic' to me
I think on crux here is around what to do in this face of uncertainty.
You say:
If you put a less unreasonable (from my perspective) number like 50% that we’ll have AGI in 30 years, and 50% we won’t, then again I think your vibes and mood are incongruent with that. Like, if I think it’s 50-50 whether there will be a full-blown alien invasion in my lifetime, then I would not describe myself as an “alien invasion risk skeptic”, right?
But I think sceptics like titotal aren't anywhere near 5% - in fact they deliberately do not have a number. And when they have low credences in the likelihood of rapid, near-term, transformative AI progress, they aren't saying "I've looked at the evidence for AI Progress and am confident at putting it at less than 1%" or whatever, they're saying something more like "I've look at the arguments for rapid, transformative AI Progress and it seems so unfounded/hype-based to me that I'm not even giving it table stakes"
I think this is a much more realistic form of bounded-rationality. Sure, in some perfect Bayesian sense you'd want to assign every hypothesis a probability and make sure they all sum to 1 etc etc. But in practice that's not what people do. I think titotal's experience (though obviously this is my interpretation, get it from the source!) is that they seem a bunch of wild claims X, they do a spot check on their field of material science and come away so unimpressed that they relegate the "transformative near-term llm-based agi" hypothesis to 'not a reasonable hypothesis'
To them I feel it's less someone asking "don't put the space heater next to the curtains because it might cause a fire" and more "don't keep the space heater in the house because it might summon the fire demon Asmodeus who will burn the house down". To titotal and other sceptics, they believe the evidence presented is not commensurate with the claims made.
(For reference, while previously also sceptical I actually have become a lot more concerned about transformative AI over the last year based on some of the results, but that is from a much lower baseline, and my risks are more based around politics/concentration of power than loss-of-control to autonomous systems)
I appreciate the concern that you (and clearly many other Forum users) have, and I do empathise. Still, I'd like to present a somewhat different perspective to others here.
EA seems far too friendly toward AGI labs and feels completely uncalibrated to the actual existential risk (from an EA perspective)
I think that this implicitly assumes that there is such a things as "an EA perspective", but I don't think this is a useful abstraction. EA has many different strands, and in general seems a lot more fractured post-FTX.
e.g. You ask "Why aren’t we publicly shaming AI researchers every day?", but if you're an AI-sceptical EA working in GH&D that seems entirely useless to your goals! If you take 'we' to mean all EAs already convinced of AI doom then that's assuming the conclusion, whether there is a action-significant amount of doom is the question here.
Why are we friendly with Anthropic? Anthropic actively accelerates the frontier, currently holds the best coding model, and explicitly aims to build AGI—yet somehow, EAs rally behind them? I’m sure almost everyone agrees that Anthropic could contribute to existential risk, so why do they get a pass? Do we think their AGI is less likely to kill everyone than that of other companies?
Anthropic's alignment strategy, at least publicly facing, is found here.[1] I think Chris Olah's tweets about it found here include one particularly useful chart:
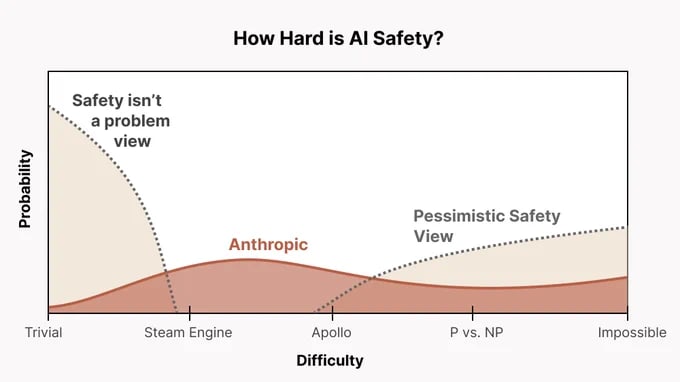
The probable cruxes here are that 'Anthropic', or various employees there, are much more optimistic about the difficulty of AI safety than you are. They also likely believe that empirical feedback from actual Frontier models is crucial to a successful science of AI Safety. I think if you hold these two beliefs, then working at Anthropic makes a lot more sense from an AI Safety perspective.
For the record, the more technical work I've done, and the more understanding I have about AI systems as they exist today, the more 'alignment optimistic' I've got, and I get increasingly skeptical of OG-MIRI-style alignment work, or AI Safety work done in the absence of actual models. We must have contact with reality to make progress,[2] and I think the AI Safety field cannot update on this point strongly enough. Beren Millidge has really influenced my thinking here, and I'd recommend reading Alignment Needs Empirical Evidence and other blog posts of his to get this perspective (which I suspect many people at anthropic share).
Finally, pushing the frontier of model performance isn't apriori bad, especially if you don't accept MIRI-style arguments. Like, I don't see Sonnet 3.7 as increasing the risk of extinction from AI. In fact, it seems to be both a highly capable model that's also very-well aligned according to Anthropic's HHH criteria. All of my experience using Claude and engaging with the research literature about the model has pushed my distribution of AI Safety towards the 'Steam Engine' level in the chart above, instead of the P vs NP/Impossible level.
Spending time in the EA community does not calibrate me to the urgency of AI doomerism or the necessary actions that should follow
Finally, on the 'necessary actions' point, even if we had a clear empirical understanding of what the current p(doom) is, there are no clear necessary actions. There's still lots of arguments to be had here! See Matthew Barnett has argued in these comments that one can make utilitarian arguments for AI acceleration even in the presence of AI risk,[3] or Nora Belrose arguing that pause-style policies will likely be net-negative. You don't have to agree with either of these, but they do mean that there aren't clear 'necessary actions', at least from my PoV.
- ^
Of course, if one has completely lost trust with Anthropic as an actor, then this isn't useful information to you at all. But I think that's conceptually a separate problem, because I think have given information to answer the questions you raise, perhaps not to your satisfaction.
- ^
Theory will only take you so far
- ^
Though this isn't what motivates Anthropic's thinking afaik
- ^
To the extent that word captures the classic 'single superintelligent model' form of risk
I have some initial data on the popularity and public/elite perception of EA that I wanted to write into a full post, something along the lines of What is EA's reputation, 2.5 years after FTX? I might combine my old idea of a Forum data analytics update into this one to save time.
My initial data/investigation into this question ended being a lot more negative than other surveys of EA. The main takeaways are:
- Declining use of the Forum, both in total and amongst influential EAs
- EA has a very poor reputation in the public intellectual sphere, especially on Twitter
- Many previously highly engaged/talented users quietly leaving the movement
- An increasing philosophical pushback to the tenets of EA, especially from the New/Alt/Tech Right, instead of the more common 'the ideas are right, but the movement is wrong in practice'[1]
- An increasing rift between Rationalism/LW and EA
- Lack of a compelling 'fightback' from EA leaders or institutions
Doing this research did contribute to me being a lot more gloomy about the state of EA, but I think I do want to write this one up to make the knowledge more public, and allow people to poke flaws in it if possible.
- ^
To me this signals more values-based conflict, which makes it harder to find pareto-improving ways to co-operate with other groups
Hey Cullen, thanks for responding! So I think there are object-level and meta-level thoughts here, and I was just using Jeremy as a stand-in for the polarisation of Open Source vs AI Safety more generally.
Object Level - I don't want to spend too long here as it's not the direct focus of Richard's OP. Some points:
Meta Level -
Again, not saying that this is referring to you in particular