This project was carried out as part of the “Carreras con Impacto” program during the 14-week mentorship phase. You can find more information about the program in this entry.
Epistemic Status
This article begins from a place of having little to no experience with AI compute and only a minimal background in AI governance. I've dedicated only some hundreds of hours to this work, so I do not claim to be an expert in the field. My background is in Political Science with a focus on Economics and Public Policy, and my research experience is limited. My initial knowledge of AI compute was insufficient to clearly understand the correct steps to take, so I had to learn everything from scratch.
This piece represents a research trial to test my prioritization, interest, and fit for this topic. While I'm not completely satisfied with the work, I've learned a great deal and have solidified my commitment to continue learning. Feedback on this piece would be invaluable for my continued development and would be greatly appreciated.
Any mistakes made are entirely my own.
Summary
The cost of training large models continues to rise annually, posing significant challenges for academia, which lacks the financial resources to keep pace with these developments. As a result, academic contributions to frontier AI research have diminished. Partly in response, the National Artificial Intelligence Research Resource (NAIRR) was proposed in the United States to provide academia with access to these costly resources, with the goal of democratizing AI development. Despite the allocation of a 2.6 billion USD budget for this initiative, its potential effectiveness in positioning academia at the forefront of cutting-edge AI development remains uncertain. This article aims to evaluate the NAIRR's potential through two approaches. First, by estimating the performance it could acquire with its budget versus some large industry players. Second, by estimating the raw computing power it could provide and the number of current AI models it could train. The findings suggest that while NAIRR would significantly advance academic institutions, it would still fall short in enabling them to compete directly with industry.
Introduction
Compute is increasingly recognized as the primary engine driving AI development, even surpassing other critical factors like algorithms and data (Ho et al., 2024). However, accessing high-level compute necessitates substantial investments. Academia often lacks the financial resources required to secure such technology, effectively sidelining them from significant AI research and development (R&D). Consequently, this scenario favors large technology firms, which possess the necessary financial means (Ahmed and Wahed, 2020).
In response to this growing "compute divide", the National Artificial Intelligence Research Resource (NAIRR) was proposed to “democratize the AI R&D landscape in the United States for the benefit of all”. Based on this premise, the US government will provide American researchers and educators from communities, institutions, and regions traditionally underserved with access to computing resources, data, testbeds, algorithms, software, services, networks and expertise.
To realize this vision, a proposed budget of $2.6 billion will be allocated to fund crucial resources over an initial six-year period. Given the escalating costs associated with training cutting-edge AI models, sustaining progress in AI R&D without competitive investment will become increasingly challenging (Cottier, 2023). The purpose of this project is then to evaluate NAIRR's potential to foster the development of frontier AI models and thus compete with large technology firms in AI R&D. To achieve this, as a first method, I will estimate the performance (FLOP/s) that NAIRR could acquire with its proposed budget over its operational period (2026-2032), comparing it to the performance that major industry players like Meta, Microsoft, Google, Amazon, Oracle and Tencent could obtain during the same timeframe. Second, I will estimate the total computational capacity in FLOP that NAIRR could acquire and compare it with the industry's capabilities over the same timeframe. Based on this analysis, I will determine how many Gemini 1.0 Ultra models—currently the most compute-intensive—NAIRR could train with its available resources, relative to the industry's capacity.
The Compute Divide in ML
Compute has become a key predictor of deep learning system performance (Thompson et al., 2022). Since the start of the deep learning era, as scaling laws predict, more parameters and training data, driven by increases in the amount of compute, leads to greater capabilities (Ho et al., 2024). Consequently, significant investments in this technology are almost mandatory to create the most powerful models. This has led to a substantial surge in compute usage. Sevilla et al. (2022) highlight that during the pre-deep learning era, the compute required to train machine learning systems doubled approximately every 18 months. However, with the rise of deep learning, this trend has accelerated dramatically, with compute requirements now doubling every six months for regular-scale models and every 1.8 months for notable and frontier models (Sevilla & Roldán, 2024). Figure 1 represents the compute usage train before and during the deep learning era for regular-scale models.
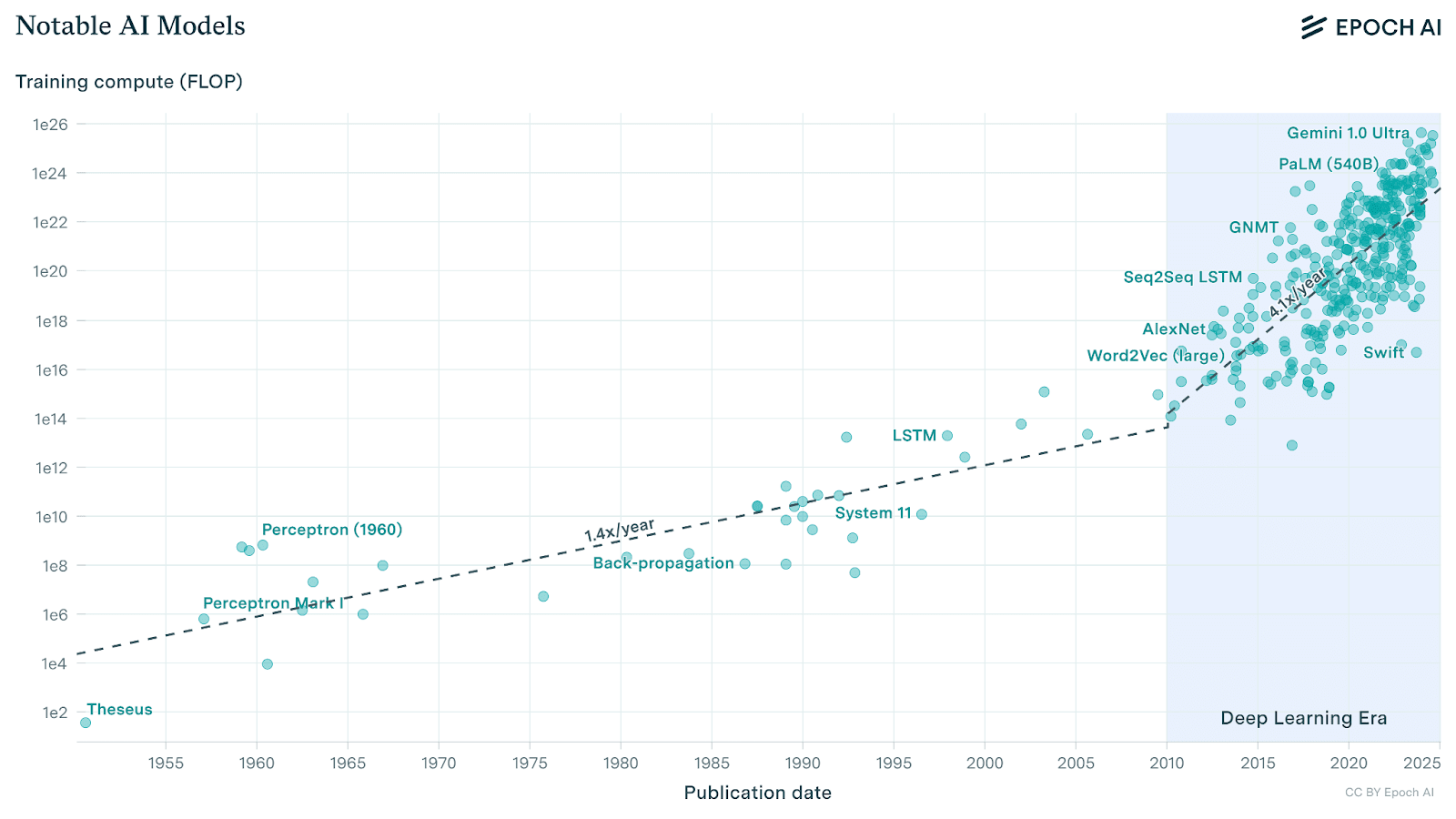
Figure 1: Trends in training compute of Notable AI Models between 1952 and 2025 (Epoch, 2024).
This shift has displaced academia as the dominant actor in creating the largest AI models. Besiroglu et al. (2024) report that in the early 2010s, about 65% of these models originated from academic labs. However, by the early 2020s, this figure had dropped to approximately 10%. This trend is particularly evident in the development of large self-supervised models, where the largest academic model uses less than 1% of the compute required to train the largest industry-developed machine learning model.
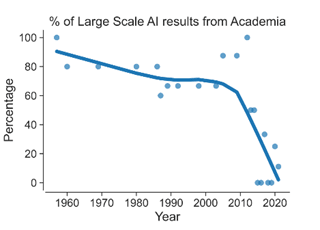
Figure 2: The proportion of computationally intensive AI from academia (Ganguli et al., 2022).
A key reason for the compute divide between academia and industry is the limited funding available to academic researchers. For example, in 2021, the U.S. government allocated US$1.5 billion to non-defense academic research into AI; Google spent that much on DeepMind alone in 2019 (Chesterman, 2023). This significant disparity in funding means that only industry labs can afford the costly AI accelerators (like GPUs) necessary for large-scale, compute-intensive machine learning research. Consequently, academia has been forced to focus more on lower-compute intensity research (Besiroglu et al., 2024).
While the industry's increasing investment in AI offers significant societal benefits through technology commercialization, it also raises concerns. Klinger et al. (2022) observe that the private sector's emphasis on computationally intensive deep learning has narrowed the scope of AI research. This focus has led to the neglect of studies into societal and ethical implications of AI, and in crucial sectors such as health. Besiroglu et al. (2024) argue that the dominance of industry in the development of large, compute-intensive machine learning models, impedes academic institutions from independently evaluating and scrutinizing these models. This shift is particularly concerning since frontier models are often associated with higher levels of risk (Heim & Koessler, 2024).
The Democratization of AI
There is a growing awareness of the compute gap in AI research within academia and its negative consequences. One proposed solution is to provide more computing resources to academics. By doing so, it is expected to help a wider range of people contribute to AI design and development processes, thereby increasing the democratization of AI development (Seger et al., 2023).
Major countries around the world recognize the potential of AI and are now developing their own national computing infrastructures to enhance their position in the AI race. Although not all these initiatives are aimed at reducing the compute divide between industry and academic institutions, they all indirectly support academia by providing the necessary resources to contribute to AI research and development that might otherwise be inaccessible. The following table summarizes these efforts.
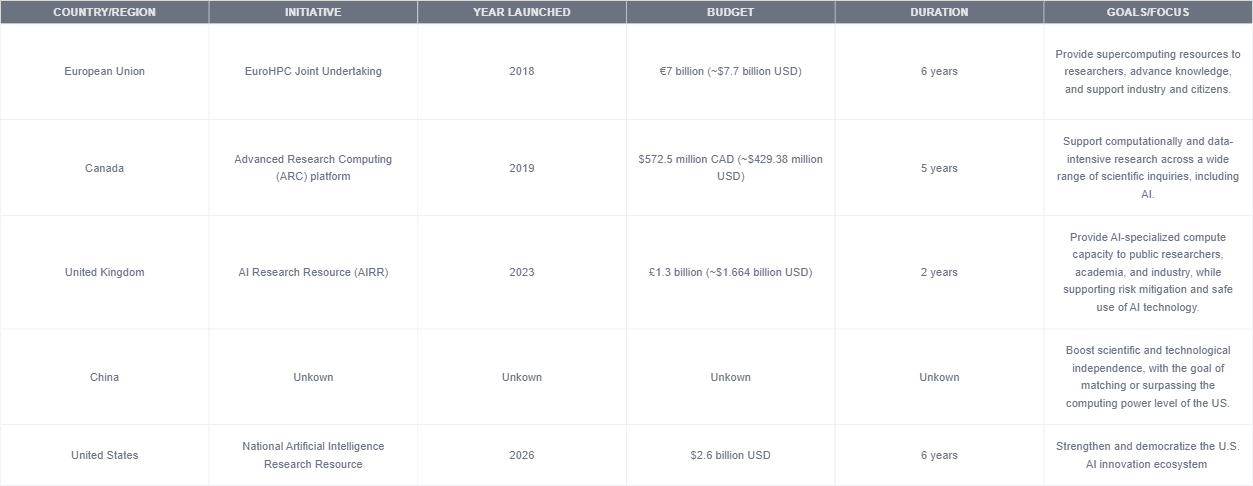
Figure 3: Global Initiatives in National Computing Infrastructures for AI Development.
In 2018, the European Union launched the EuroHPC Joint Undertaking (EuroHPC JU) to support research and innovation activities. With a budget of €7 billion (~$7.7 billion USD) for the period 2021-2027, its goal is to provide researchers with supercomputing resources to advance scientific knowledge, benefit citizens, and support industry (European Commission, 2024).
In 2019, Canada established its national Advanced Research Computing (ARC) platform to support computationally and data-intensive research. With a budget of $572.5 million CAD (~$429.38 million USD) over five years, the ARC has only been able to meet 20% of the recent demand for GPUs, as it provides resources not only for AI research but for a wide range of scientific inquiries (Digital Research Alliance of Canada, 2023).
In 2023, the UK initiated the AI Research Resource (AIRR) with a budget of £1.3 billion (~$1.664 billion USD) for a period of two years (Kleinman, 2024). The AIRR aims to provide world-leading AI-specialized compute capacity to public researchers, academia, and industry. Its goal is to maximize the benefits of AI while supporting critical work on frontier risk mitigation and the safe and potential use of the technology (UK Research and Innovation, 2023).
In 2023, China unveiled an action plan for developing high-quality computing power infrastructure. This initiative is part of China's efforts to boost its scientific and technological independence amid the China-US tech competition. If this goal is achieved, China's computing power level is expected to reach or even surpass that of the US (Global Times, 2023).
This year, the United States launched the pilot program for the National Artificial Intelligence Research Resource (NAIRR). Unlike previous initiatives, NAIRR is the first explicitly designed not only to address the compute divide between industry and academia but also to strengthen the US's position as a global leader in AI. The following section of this article will delve into this initiative, assessing its potential to narrow the compute divide and democratize AI development.
The National Artificial Intelligence Research Resource
President Joe Biden, through Executive Order 14110, mandated the launch of the NAIRR pilot. This initiative is designed to act as a proof-of-concept for the eventual full-scale NAIRR. Over the course of two years, the pilot will focus on supporting research, particularly in the areas of safe, secure, and trustworthy AI. The resources provided aim to bridge the access gap and support aspects of AI research that might be deprioritized in the private sector (National Science Foundation, 2024).
A key element of the NAIRR is the provision of computational resources. For the pilot phase, it will provide a total of 3.77 x 1018 FLOP/s of compute power (Miller & Gelles, 2024). The full-scale operational NAIRR is expected to generate even greater computational power. This section of the article will explore the potential computational capacity of a fully operational NAIRR and compare it to industry standards. I posit that NAIRR's ability to democratize AI research on large models is intrinsically tied to the total computing power it can provide. As the availability of resources increases, so does the opportunity for under-resourced researchers to develop large AI models, thereby narrowing the compute divide that currently hinders equitable progress in the development of such models.
Methodology
For my analysis of both NAIRR and the industry, I rely on three important assumptions. First, I assume that both entities will allocate their entire budget exclusively to computational power, rather than distributing it among data, software, or salaries for highly skilled researchers. Second, I assume that all compute resources will be used exclusively for developing large models. Third, I assume both actors will be continuously training AI models from the beginning of NAIRR's full operations until its conclusion, spanning six years in total. While these assumptions are unrealistic, they provide a framework to compare the potential of NAIRR and the industry if they were to compete in the development of frontier AI models.
In the first method, I estimated the compute performance that could be acquired by applying the current price-performance trend for ML GPUs. Hobbhahn and Besiroglu (2022) report that the FLOP/s per dollar for these GPUs doubles approximately every 2.07 years. Using this trend, I projected the performance achievable with an annual budget allocated to H100 GPUs. For NAIRR, the analysis assumes exclusive H100 GPU purchases every two years, with a budget of $750 million USD. For industry players, I also assumed H100 GPU acquisitions at 2023 levels, biennially from 2026 to 2032. The H100 shipment data was sourced from Statista (2024). The total compute performance was calculated by multiplying the price-performance ratio by the biannual budgets of NAIRR and industry (the latter based on shipment quantities multiplied by the H100 GPU cost of $30,000). Detailed calculations are provided here.
In the second method, to estimate how many FLOP NAIRR and industry could acquire, I rely on the computational price-capacity trend, which illustrates how many FLOP can be purchased with a dollar over time. Hobbhahn et al. (2023) calculated that for FP32 precision, the doubling time is 2.1 years. However, since lower precision formats are increasingly being used, using their data, I calculated the doubling time for the price-performance trend for FP16, which is 0.8 years (95% CI: 0.7 to 1.3). With these trends in hand, it is possible to estimate the computation price-capacity trend for the years NAIRR becomes operational (2026-2032).
To perform this calculation, I followed the methodology of Hobbhahn et al. (2023), as detailed by Cotra (2020). I used the hardware's release price, adjusted for inflation, and assumed a two-year amortization period. When a release price was unavailable, I utilized cloud computing prices from Google Cloud, adjusting for inflation to ensure comparability with the amortized prices and assuming a 40% profit margin for the cloud provider. Figure 3 illustrates the historical trends for both FP32 and FP16. Important caveats to these estimates were highlighted by Hobbhahn et al. (2023).
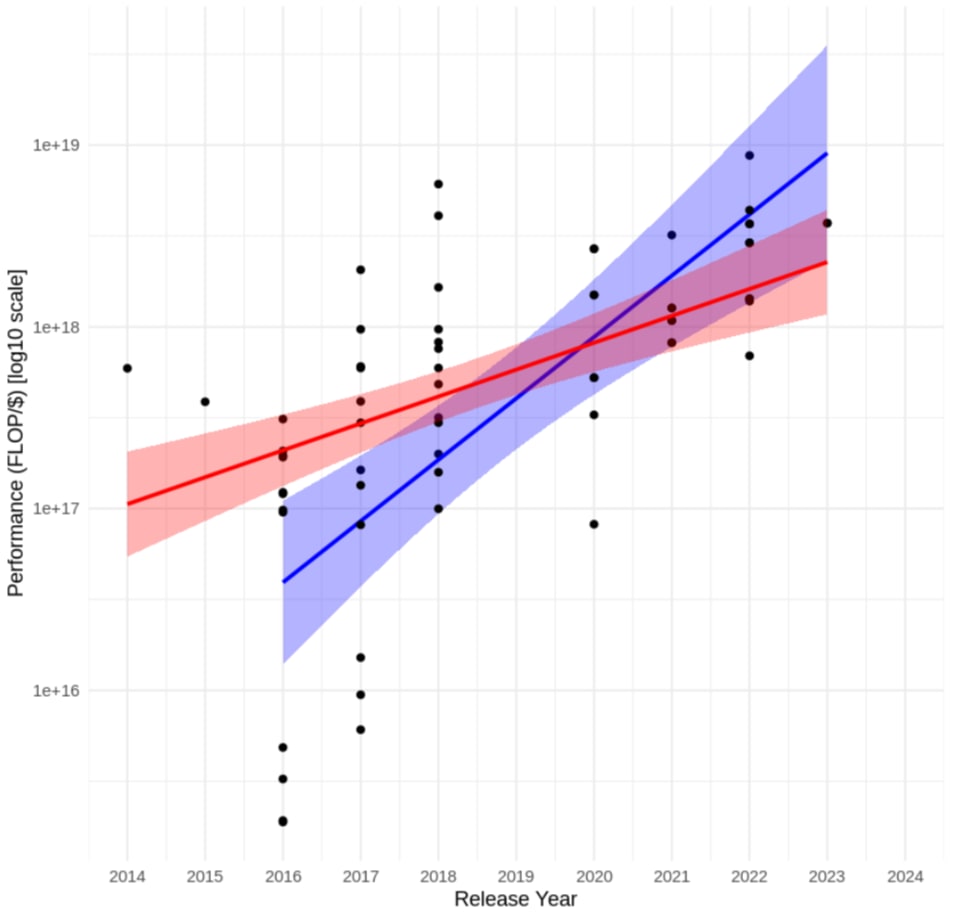
Figure 4: FP16 (in blue) and FP32 (in red) price-performance (FLOP/$) trends over time.
Following Cotra (2020), I can use the computational price-capacity rate to estimate how many FLOP can be purchased with a defined budget. The total budget for the full-scale NAIRR is $2.6 billion USD, with $2.25 billion USD allocated specifically for funding resources. For comparison with industry, I utilize the annual private investment in AI, as reported by the AI Index (Stanford University, 2024). Assuming a linear growth in the industry AI budget, I can project its potential size during NAIRR's operational years by applying a linear regression. Figure 4 illustrates the cumulative investment made by both NAIRR and the industry throughout the period of interest. Detailed calculations are provided here.
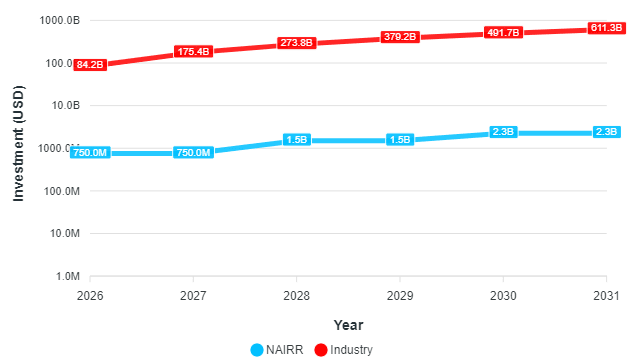
Figure 5: Cumulative investment by NAIRR and Industry (2026-2031).
Results
Based on these calculations, using the first method, it was determined that NAIRR could acquire 3.07 x 10²⁰ FLOP/s, compared to 6.13 x 10²¹ FLOP/s for the industry—representing a difference of an entire order of magnitude. For the second method, NAIRR could secure 1.96 x 10³⁶ FLOP for FP16 precision and 3.26 x 10³⁴ FLOP for FP32 precision during the 2026-2030 period. In contrast, the industry could obtain 4.05 x 10³⁸ FLOP for FP16 precision and 7.19 x 10³⁶ FLOP for FP32 precision in the same period. This reveals that the industry can achieve approximately two orders of magnitude more FLOP for both FP16 and FP32 precision compared to NAIRR. Figures 5 and 6 illustrate this disparity.
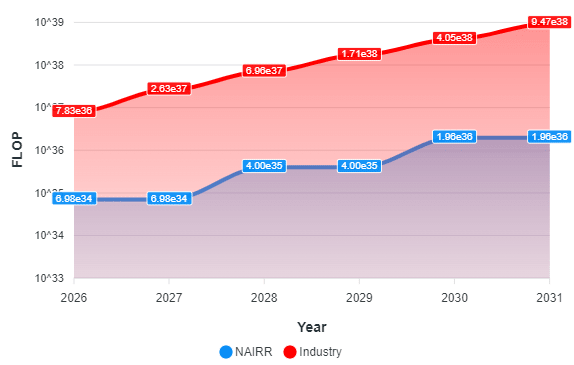
Figure 6: Cumulative FLOP in FP12 (2026-2031).
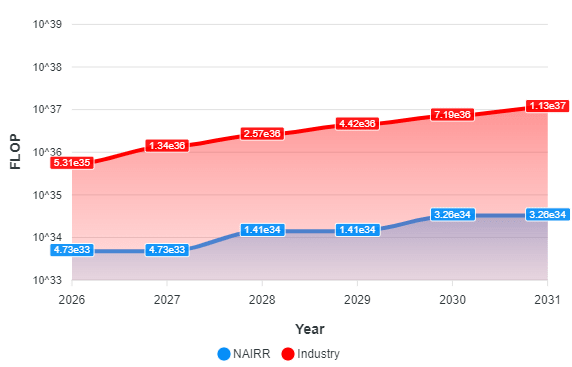
Figure 7: Cumulative FLOP in FP32 (2026-2031).
Based on these results, NAIRR's computing power could theoretically support the training of 3.92 x 1010 Gemini 1.0 Ultra models using FP16 precision or 6.52 x 108 models using FP32 precision, which is the most compute-intensive model to date. In contrast, the industry could train 1.89 x 1013 models with FP16 precision or 2.27 x 1011 models with FP32 precision, highlighting the significant disparity in computational capacity between NAIRR and the broader industry. These results indicate a difference of three orders of magnitude. However, the notion that NAIRR or the industry could theoretically support the training of billions or tens of billions of such models is unrealistic, even with significant computational resources. This limitation is discussed in the next section.
Limitations of Results
My model has several limitations. Firstly, the notion that NAIRR or the industry could theoretically support the training of billions or tens of billions of models is unrealistic, even with substantial computational resources. This result may stem from the fact that this is my first attempt at calculations of this nature, and there are numerous ways errors could have occurred. Additionally, there are several sources of overestimation in this analysis. First, by assuming that NAIRR and the industry will operate non-stop for six years, the results significantly overestimate what could realistically be achieved. Second, substantial hardware costs were not accounted for, as I only considered GPU prices, neglecting other critical expenses such as intra-server, inter-server networking and salaries. Third, I assumed peak performance levels, while in practice, only 20% to 70% of this performance is typically utilized in ML training (Leland et al., 2016).
Secondly, there is uncertainty regarding the AI industry investment data provided by the AI Index (Stanford, 2024). It is unclear whether this data includes investments made in publicly traded companies. If such investments are excluded, the industry's total investment might be underestimated, particularly as "Big Tech" firms, which are major AI developers, may not be fully represented. This suggests that the gap between industry and NAIRR could be wider than what is presented here. Additionally, I assumed that private investment in AI would behave linearly over time. This was an oversimplified assumption, as budgets have been growing exponentially.
Conclusion
Numerous voices are increasingly advocating for greater investments to address the compute divide in ML training. As training advanced AI models becomes more expensive, competing with the substantial investments of private entities is increasingly difficult. This article finds that even with significant funding, such as that allocated to NAIRR, matching industry capabilities remains a formidable challenge. Therefore, it is essential to strategically allocate resources where they can have the greatest impact, particularly in fostering diversity and supporting research with significant societal value that the industry may overlook due to a lack of commercial appeal. NAIRR's focus on funding such research is a potential approach toward achieving this important goal.
In this article, I explored the potential of NAIRR’s computing power to democratize the development of large AI models. However, this analysis did not consider the primary intent behind this resource: diversifying the types of research that are often overlooked by industry. Further investigation into this aspect could offer a clearer understanding of how effectively NAIRR could democratize AI development. Additionally, NAIRR is pursuing other significant initiatives to promote AI democratization, such as offering educational and upskilling opportunities. While this article focused on just one facet of AI democratization, further research is necessary to assess the impact of these broader efforts and to understand how they collectively contribute to a more inclusive and equitable AI landscape.
Acknowledgments
I would like to extend my sincere thanks to those who provided valuable feedback and insights on the ideas presented in this article at various stages, including Alejandro Acelas, Jaime Sevilla, Guillem Bas, Michelle Bruno, and Sandra Malagón.
I used OpenAI's ChatGPT and Google's Gemini Advanced for editing assistance throughout the writing process.
Executive summary: The National AI Research Resource (NAIRR) initiative aims to democratize AI development, but analysis suggests it will still fall short of enabling academia to compete directly with industry in frontier AI research due to the vast compute gap.
Key points:
This comment was auto-generated by the EA Forum Team. Feel free to point out issues with this summary by replying to the comment, and contact us if you have feedback.