This is post was originally published on my blog here, where I write about trying to improve forecasting techniques for Global Catastrophic Risks. As always, feedback or collaboration of any kind is greatly appreciated either here in the comments or privately on Twitter (@Damien_Laird).
Summary
The current state of forecasting with large language models (LLMs) performs significantly worse than humans, but the groundwork exists for currently ongoing research to close this gap. Rapidly evolving model capabilities and seemingly unexplored research directions leave the door open for surprisingly large and rapid progress that could allow LLMs to soon contribute meaningfully to the space of judgmental forecasting. I expect this work to contribute more to our ability to mitigate the risk posed by powerful AI than to increase that same risk, but being generally unfamiliar with this space I’m not especially confident and would welcome insight from others.
Research
This Research post will be less dense and more speculative/exploratory than previous ones. That’s because the topic of interest is quite novel and developing rapidly.
Large Language Models (LLMs) are what underpin many of the AI products that it seems like everyone is so excited about right now. From OpenAI’s ChatGPT to Microsoft’s Bing to Google’s Bard.
I am going to skip right over what they are and how they’re built because I’m not a machine learning expert and I doubt I could do those topics justice. Similarly, I’ll strive to use the appropriate terminology throughout this post but it’s likely I’ll get something mixed up. Please point any errors out so I can correct them.
The key takeaway is that two of those three products I listed are actually built on top of the same family of LLM, the “generative pre-trained transformer” (or GPT)models built by OpenAI. On March 14th the newest iteration in that family, GPT-4, was released and in reading through the associated announcement one detail in particular jumped out to me:
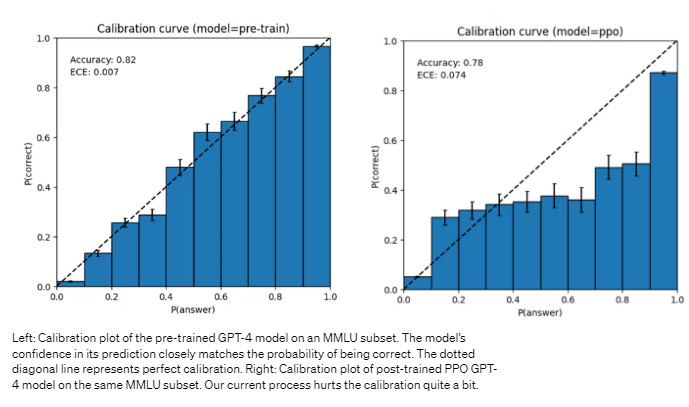
If you’re familiar with forecasting you’ll likely recognize this style of calibration plot. It’s a common way for forecasters to judge their performance, checking if they tend to be over or underconfident in their predictions and if there’s a pattern to what kind of predictions they’re giving when that happens. At a glance, this image and the subtext seem to show that “post-training” made the GPT-4 model a much, much worse forecaster (despite apparently being a much more “helpful” model in general), while the “pre-trained” model was actually quite well calibrated. This was pretty confusing to me. I knew there was some work going on with using LLMs for forecasting, but my 10 second impression had been that their performance wasn’t very impressive yet. Clearly I was missing something, or (more likely) a few somethings.
I sat in this confusion for a while. I voiced this confusion in a few places. I ran into others confused about this same plot.
Thankfully I stumbled onto Paul Christiano’s comments here, and Zvi addressed this point in his recent, fourth, AI summary (ctrl+F “calibration” to find the same plot that I copied above).
My understanding now is that “Calibration” in the context of LLMs means something slightly different than how “Calibration” is typically used in the context of forecasting. LLMs naturally produce a probability distribution over possible outputs for a given input, with each probability indicating something like the model’s “confidence” that a particular output is “correct”. If this probability distribution’s percentages are accurate to how often those outputs are “correct”, the model is well calibrated. In forecasting, calibration is typically associated with something like prediction polling, where forecasters are typically sharing their forecasts of the likelihood of a given event in percentage form, and a well calibrated forecaster’s predictions are directionally correct about as often as those percentages would predict.
Like I said, the difference is subtle, and can actually go away if you’re just asking an LLM to predict true or false that a given resolution criteria will be met. In that case a well calibrated LLM output would mean the same thing as a well calibrated forecaster. But what if, as is the case with most chatbot applications for LLMs now, you only see the top text output given your input. I expect when most people imagine forecasting with LLMs, they intuitively expect to be asking one of these chatbots something like “What is the likelihood that a human steps foot on mars by 2030” and it spits back a single percentage. In this case the top output from the LLM’s probability distribution might itself be “90%”, while the model’s confidence in that being the “correct” output might be “80%”, in which case the definitions of calibration in the two domains have diverged! Asking an LLM to voice its own uncertainty has been helpfully termed “verbalized probability” by this paper, where GPT-3 was found to be able to produce better calibrated uncertainty via this verbalized probability in some situations, within the context of simple arithmetic problems.
Focusing now on the context of LLMs and what calibration has historically meant there, there has been some academic research on the topic. This 2017 paper finds that “modern neural networks are no longer well-calibrated”, which surprises them given that past neural networks were, and they hypothesize that novel features of the newest, most capable neural networks might mean that calibration will decrease as model size/capabilities continue to increase. This 2021 paper revisits the topic and finds that this trend has not continued, that the calibration of models seems dependent on the particular training and architecture of a given model, and that there are ways to improve the calibration of models after they’ve been created (though I’m unclear on if this is by tweaking their design and rebuilding them or by adding something additional on top of them after the base models are fixed).
Research in this vein segued into the only academic paper I’m aware of on trying to use LLMs to do judgmental forecasting. They found performance to be better than chance but significantly worse than human forecasters. More significantly, the researchers invested in creating a dataset and benchmarking system to allow future models’ forecasting performance to be compared directly, helping to indicate when and where progress is being made on this problem. This progress is now happening on a real-time leaderboard, with cash incentives, called the Autocast competition. One of the competing teams even had a funded project on Manifund, the new impact certificate platform that I recently wrote about here. Progress seems mild so far, but the competition is in its very early stages. The rules require open publication of methods, data etc., so hopefully this leads to both significant advances and the information to learn from them. I’ll certainly revisit this topic on this blog once information from competitors is available.
For now, I’m extremely interested in certain assumptions that seem baked into the Autocast forecasting paradigm. First, there exists a problem of “contamination” in a model’s training data. For example, GPT-4’s training data is from circa September 2021. If you give it a historical forecasting question from 2020, how the actual event played out might be captured in that training data, causing it forecast it with otherwise undue confidence. Obviously, then you’re no longer testing its forecasting ability. That being said, using historical forecasting questions is highly desirable because you can immediately evaluate the model against the correct answer vs. waiting for resolution. The Autocast competition therefore restricts the use of models to only ones that were trained on data from before a particular cutoff date. While this solves the contamination problem, capabilities are advancing so fast in the world of LLMs that this prevents the use of the most powerful models as long as researchers are trying to compete on this particular benchmark.
Additionally, the Autocast data set consists of news sources associated with the given forecasting questions. The idea is, like a human forecaster, a model can consume relevant pieces of news as they happen and update its forecast accordingly based on the contents. These news sources are associated with particular dates, allowing researchers to see how forecasts are updated as resolution dates approach and more and more information is gained. In the Autocast paper, this clearly improved forecasting performance. However, it also bakes in a very particular model of forecasting that I think is best associated with the sort of current-events / geopolitical questions that have been the main focus of the Good Judgment Project or intelligence community sponsored tournaments. These have relatively near term resolution dates and tend to be on a particular set of topics. This probably represents most of the judgmental forecasting going on, but it is notably different from the longer timeline forecasting being done on Global Catastrophic Risks that I think tends to depend much less on digesting timely news stories and more on building deep knowledge about particular risks. Within this Autocast paradigm, that knowledge would have to be captured in the base model itself, as the information in news sources is unlikely to update forecasts much.
As this research seems to stem mostly from work on model calibration, it also requires LLMs to predict true/false, numerical, or multiple choice outcomes and uses the model’s reported confidence to judge accuracy. This precludes the possibility of asking a model to directly predict a percentage likelihood, which in turn seems to preclude the ability to generate an associated rationale or explanation for the forecast. You might think that this is a much harder problem than the sort of single value forecasts the competition is looking for, but I’m not so sure.
GPT-3 performed quite poorly in an informal test of its forecasting abilities, but it seems to have been prompted to only provide a percent estimate. “Chain-of-Thought” prompting, or asking an LLM to do something like “think through an answer step by step” seems to produce higher quality outputs and better reasoning, though I’m not aware of this being tried for forecasting. This seems quite similar to the fermi estimation technique similarly used in judgmental forecasting. Intuitively, with the right model and prompting we may actually be able to get more accurate forecasts AND an associated rationale that we can judge and learn from more easily than getting the numerical forecast alone. GPT-4 is being released with the possibility of a much larger “context window” where much more information can be passed as an input. It’s now plenty large enough to contain multiple examples of very thorough forecasts with associated rationales demonstrating reasoning techniques like fermi estimation. This might mean that high-quality forecasting rationales written by humans are a valuable commodity, enabling us to train some near-future model that amplifies the amount of forecasting rationales that can be generated beyond what can currently be done by the human community alone! These examples could also be used to do “fine-tuning” instead of being passed as inputs, but I don’t know nearly enough about LLMs to know if either option is much better to pursue than the other.
Safety
A lot of my interest in state of the art AI comes from the possibility of it representing a GCR itself or contributing to the likelihood of others. This post explores the possibility of enhancing a particular capability of AI beyond what we currently know how to use it for. Would doing so increase the risk of catastrophe?
I don’t think so…
From the conversations I’m able to track in the AI alignment space, it seems like using less powerful AI models to mitigate the risk of the subsequent, more powerful models is required in some plans for achieving alignment. This, intuitively, seems to require the ability of those less powerful models to forecast accurately. Additionally, the forecasting paradigm I laid out with using models to produce not just likelihood estimates but associated rationales should allow us to examine the reasoning ability and honesty more directly than what seems to be the current state of the art for AI judgmental forecasting. Forecasting also provides a rare context where we can directly compare the accuracy/truthfulness of claims with ready metrics to compare it to.
Additionally, I don’t think this work is enhancing the capabilities of a given model, per se. It seems more like discovering a capability that already exists within a model and surfacing it for us to access with particular prompting? Of course, discovering that this capability is accessible with a particular form of prompting or fine-tuning might be the information that allows future models to use it themselves…
This work makes me nervous! It’s easy to imagine how central powerful forecasting would be to an agentic AI, and the ability to plan well in advance also seems required for many AI doom arguments. I think the case I’ve outlined above outweighs this factor by opening the door for alignment with earlier, less powerful AIs, but I’m worried this is a slippery slope argument generalizable to many capabilities.
I welcome feedback from people much more familiar with this space on the possible hazards of research in this direction, and would happily defer to the judgement of the crowd if they believe this line of inquiry is more dangerous than it’s worth.