I belive AI safety is a big problem for the future, and more people working on the problem would likely increase the chance that it gets solved, but I think the third component of ITN might need to be reevaluated.
I mainly formed my base ideas around 2015, when the AI revolution was portraied as a fight against killer robots. Nowadays, more details are communicated, like bias problems, optimizing for different-than-human values (ad-clicks), and killer drones.
It is possible that it only went from very neglected to somewhat neglected, or that the news I received from my echochamber was itself biased. In any case, I would like to know more.
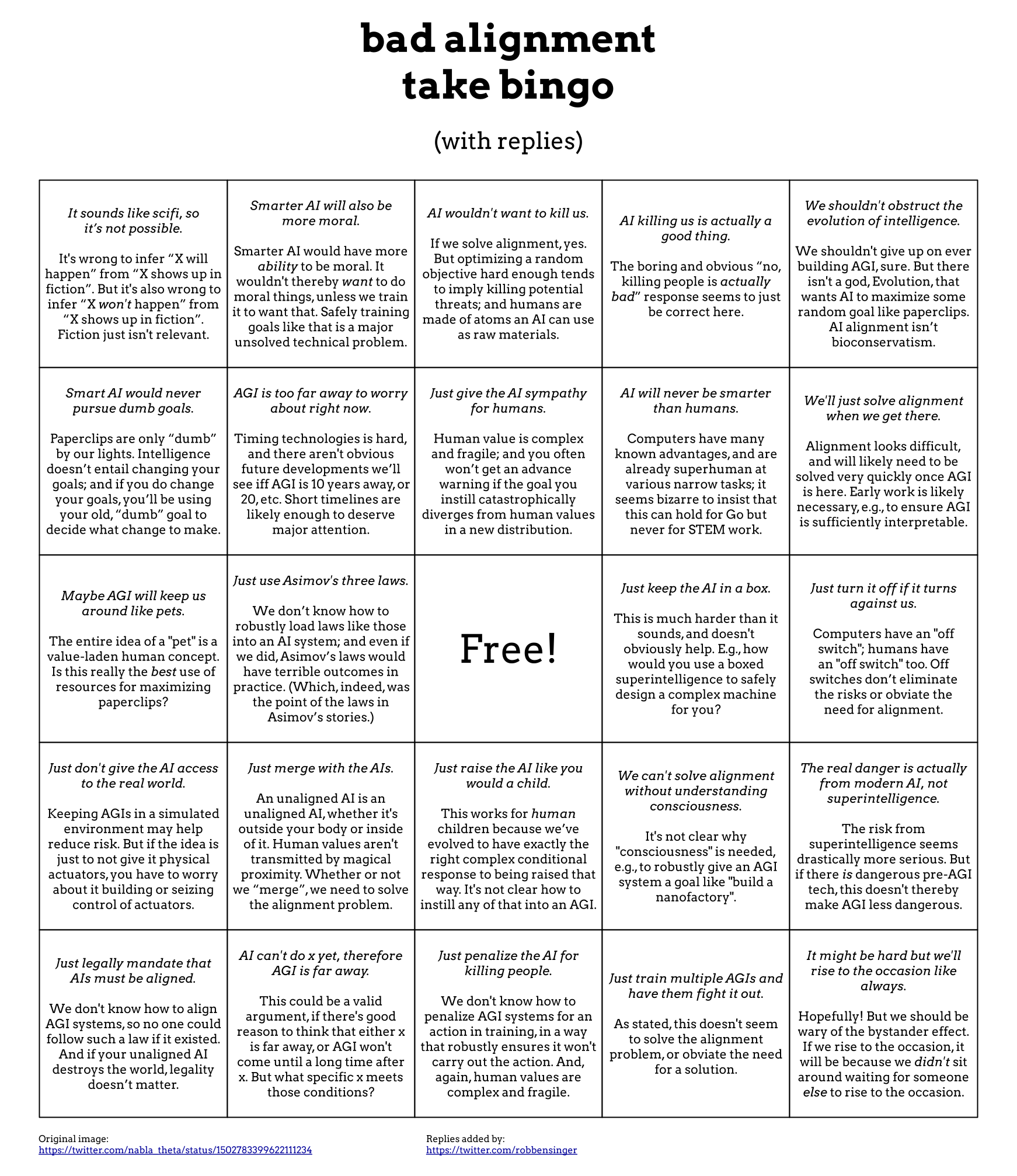


I disagree, I think if AGI safety researchers cared exclusively about s-risk, their research output would look substantially the same as it does today, e.g. see here and discussion thread.
... (read more)