Acknowledgements
We would like to thank many different people for contributing to the research that comprised this post. Tim Hwang and Teddy Collins at CSET for originally sparking this research question, Helen Toner for her early encouragement and feedback on research framing, Tuomas Oikarinen for sharpening our arguments, Tan Zhi Xuan and Serena Booth for providing several helpful resources.
Summary
This post is authored by Max Langenkamp, who did this research during his MEng at MIT’s Algorithmic Alignment Group, and by Dylan Hadfield-Menell, associate professor and Max’s supervisor.
This post is a summary of Max’s Master’s research (AIES conference paper, full thesis) which was also done in collaboration with Daniel Yue, a PhD student at Harvard Business School.
Although it is more object-level than the typical EA Forum post, we believe that this research is of interest to the EA community because (1) it examines an important factor of AI development that we believe can also serve as a lever for AI governance, and (2) it provides qualitative research on AI, which we consider a neglected but important angle for understanding how to wisely govern AI systems.
TL;DR
Machine Learning Open Source Software (MLOSS) is an important, yet neglected factor shaping the trajectory of AI. Our contributions:
- Using qualitative data, we claim that MLOSS shapes AI through standardization, enabling newer and faster forms of experimentation, and by creating online communities.
- We suggest that a dependency graph of technology capabilities (Wardley map) provide a helpful alternative to the canonical AI production function.
- We examine the economic incentives, sociotechnical factors, and ideology shaping MLOSS
- We suggest that the future of MLOSS involves decreased emphasis on deep learning frameworks and increased focus on model and data tooling (probabilistic predictions can be found at the end). At the end, we also briefly examine the risks implied by these trends.
MLOSS is important
This should be obvious to anyone who’s built an ML model in the last decade, but everyone — whether a research engineer at Deepmind or a high schooler in India — uses open source software to build models. All of the two dozen ML practitioners we interviewed told us that MLOSS tools were a crucial part of their workflow.
That everyone uses the same freely available tools implies that these tools play a large role in shaping AI development. Yet few researchers have examined MLOSS’ role in shaping AI development.
MLOSS is neglected
Hitherto, much of the discussion of the factors that shape AI has focused on the role of computation, with some consideration of the role of algorithms and data. For instance, Allan Dafoe suggests that “[p]lausibly the key inputs to AI are computing power (compute), talent, data, insight, and money.”[1] Hwang (2018) examines how the hardware supply chain shapes machine learning development. Rosenfeld (2019) and Hestness (2017) examine how dataset size relates to model accuracy in AI. Both are part of a growing literature that aims to more explicitly model the relationships between inputs and predictive error in AI. To the best of our knowledge, however, there have been no detailed examinations of how MLOSS generally shapes AI development.
Insofar as we care about how factors such as data or compute shape the trajectory of AI, we should also care about the role of MLOSS.
MLOSS and the AI production function
One question that appeared early in our research was “what is the relationship between the data, compute, MLOSS, and the other factors that shape AI production?” Articulating the relationship between these factors is key to understanding the default trajectory of AI system development.
One common characterization within economics is the Cobb-Douglas production function. It models variables, such as capital and raw materials, that parameterize a function that maps inputs to outputs.

The functional form of the CD production function

The implied form of the AI production function
Allan Dafoe applies this in the context of AI governance with the ‘AI production function’. He proposes that this production function depends on “compute, talent, data, investment, time, and indicators such as prior progress and achievements”[1]. Dafoe’s discussion of ‘AI progress’, along with discussions found in similar work, attempts to be agnostic to the particular paradigm of AI. In practice, this equates ‘deep learning’ and ‘AI’. While this choice can be motivated, it is important to recognize that there are alternative paradigms with different capabilities. For example, probabilistic programs, which can more easily incorporate explicit world knowledge, can depend far less on the availability of large datasets.
While a production function can help to explicitly separate the factors that influence deep-learning development, it also has its limits. In particular, the production function, which is typically conceived of as the product of independent variables, doesn’t account for shared dependencies between factors of production and can hide contextual information about each factor.
There is another helpful way of articulating the factors that shape AI production. Using an ordered dependency graph of capabilities, also known as a Wardley map, we can account for shared dependencies among factors (e.g. intermediate model representations depend on both compute infrastructure and the MLOSS frameworks).
Wardley Maps provide a helpful alternative to the AI production function
Wardley maps have been used for everything from preparing for survival without a phone to forecasting the trajectory of electric cars. There is also a whole book on the theory of Wardley maps. Nonetheless, we have provided a simple example below to explore the role of MLOSS in the AI ecosystem.
There are three main steps in constructing a Wardley map: describing a use case, defining the technological capabilities needed to address the use case, and ordering the capabilities on a map.
Here, the use case is ‘building deep learning models’. That goes at the top. The capabilities we’ll focus on are frameworks, pretrained models, data, and hardware. These are the primary capabilities. Each capability itself depends on other capabilities. For instance, ML frameworks (e.g. PyTorch) depend on framework compilation software (e.g. Glow compiler), which depends on the intermediate representation (e.g. ONNX), which depends on the hardware (e.g. NVIDIA GPU).
At this stage, we are not aiming to be comprehensive, but rather to articulate some key capabilities that ML frameworks (one prominent instance of MLOSS) interacts with.

Fig 1. Basic Wardley Map of Deep Learning Models
The map allows us to more clearly specify the relationship between capabilities shaping deep learning research. It also allows us to reason about which capabilities are likely to become a point of focus in the future. We will discuss this more in the final section, “The Future of MLOSS”.
We will use the Wardley Map here for discussion of the future of AI later on.
MLOSS shapes AI research through standardization, facilitating experimentation, and creating communities
After doing qualitative interviews with 23 participants, we identified three main effects that MLOSS has on the AI ecosystem.
Standardization
By standardization we mean the widespread adoption of a single technology or technique. Participants discussed the impacts of standardization through three mechanisms: the development of standardized model types; coordination on frameworks, and the creation of a common user experience for developers.
Standardization of model types is most prominent with practitioners that work with large neural networks. A decade ago, it was a substantial engineering feat to work with a 1 million parameter model. Now, however, any researcher with a connection to the internet and the right hardware can freely download a model with over 170 billion parameters or else use it for inference online. Consequently, a larger fraction of machine learning work now entails large neural networks. This was made possible by the proliferation of MLOSS tools, as well as the advances in hardware and performance engineering.
In terms of deep learning frameworks, we also see a high level of standardization: while in 2016 several different frameworks (e.g. MXNet, Theano, TensorFlow, Caffe2, Torch) had large market share, practitioners in the west have collectively settled on PyTorch, JAX, and TensorFlow as the three dominant frameworks. All of our participants used one of PyTorch, JAX, or TensorFlow. As of June 2022, Paperswithcode found that PyTorch, TensorFlow, and JAX accounted for 62%, 7%, and 1% respectively of publicly accessible paper implementations. However, because of endorsements such as DeepMind’s public adoption of JAX, we believe that Paperswithcode’s statistic for JAX use does not reflect the increased traction for JAX.
We can also see convergence at the level of user experience within the frameworks. Several of our interviewees noted that TensorFlow’s previous default graph-based execution was counter-intuitive, which made it harder to learn as a beginner. They explained that this led them to PyTorch, with its more intuitive imperative style model specification. Notably, because of this pressure, TensorFlow 2.0 adopted PyTorch’s interface and now feel very similar to use.
Enabling Experimentation
Enabling experimentation means not only are ideas faster to materialize, but also provides new ways of thinking about problems. PyTorch Lightning saves a researcher hours of model debugging by providing a module that summarizes matrix weights. However, Torch’s imperative style programming allows a researcher to think in new ways. This means that novel architectures like Tree-LSTMs previously unimaginable with graph-based model specification, became conceivable.
Creation of Community
One important aspect of MLOSS, similar to OSS ecosystems in general, is that it creates opportunities for technology contributors and users to interact. This community creation has many benefits. It allows users to become contributors, provides a large amount of feedback, naturally creates educational materials, and can provide job opportunities to MLOSS volunteers.
Users becoming contributors is a more specific instance of how open source software forums can provide a new space for connections to be made. We came across several anecdotes of how major contributors to MLOSS projects began as users, only to later be hired by the organization sponsoring the project. Although we have not explicitly measured it, we have the general sense that several job opportunities are found through engaging with MLOSS forums and communities.
The online community interacts in complex ways with the goals of the organization sponsoring the project. Soumith Chintala, co-creator of PyTorch, has for instance publicly discussed how closely the public PyTorch community has shaped his early development of the tool. In open source software development more broadly, public consensus is crucial for a successful project; perhaps unsurprisingly, it is very difficult to make an unpopular modification to a project. For a powerful illustration of this dynamic, we invite the reader to examine the unsuccessful attempt of Facebook to change the licensing terms of React.
Economic Incentives, Sociotechnical Factors, and Ideology shape MLOSS
Funding
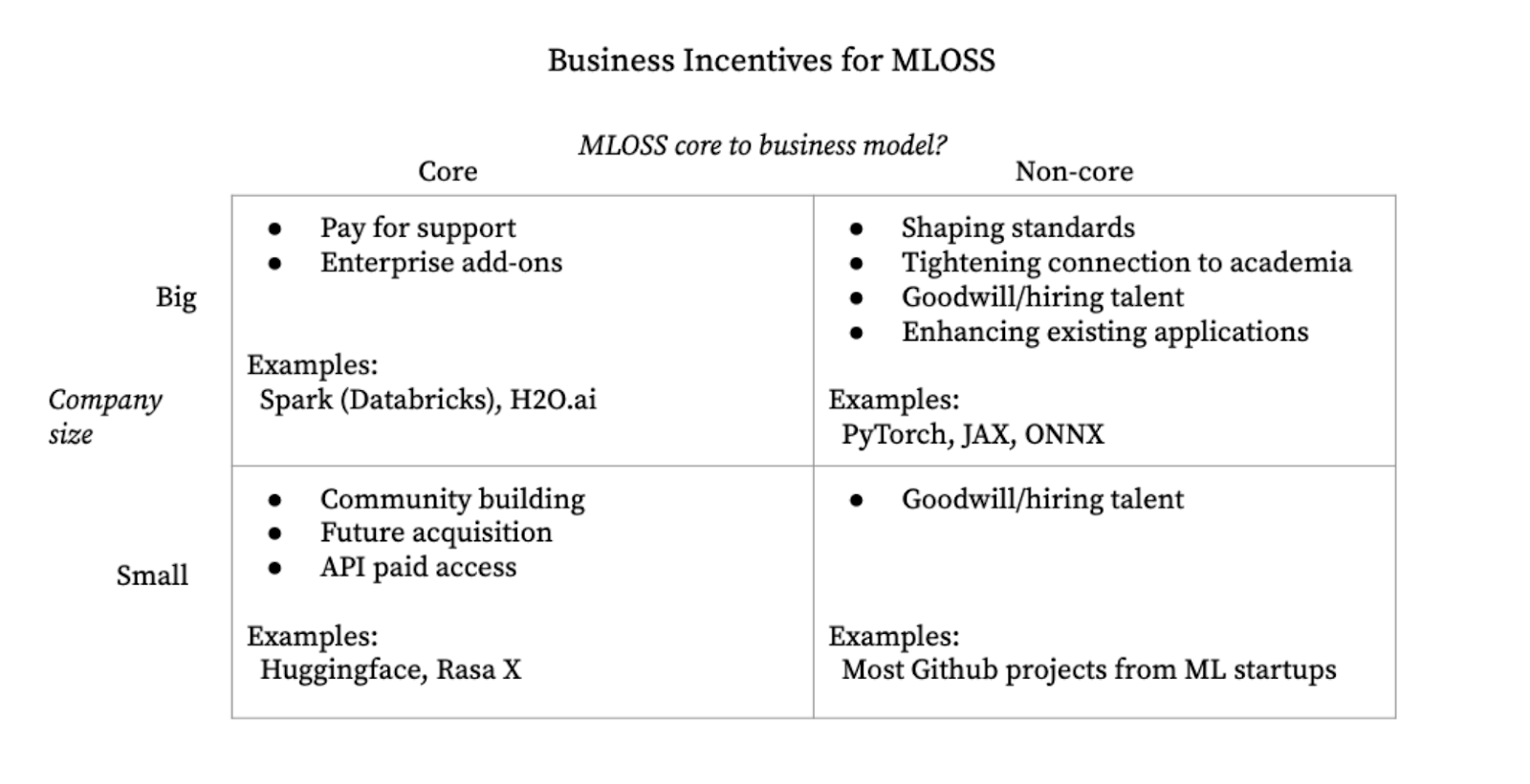
Fig 2. A proposal for how business incentives shape MLOSS
From a combination of case studies and interviewee suggestions, we found that business incentives differ between large companies and startups. Big companies fund MLOSS because it allows for talent acquisition, indirect control over the ecosystem, and enhances existing capabilities. Talent acquisition is obvious; many developers who work on the open source tools were once users. Indirect control over the ecosystem is more difficult to articulate. This can show up in how defaults are set (e.g. what types of hardware PyTorch is compatible with) or more broadly what direction the project is heading in (e.g. whether HuggingFace prioritizes compatibility with Graphcore’s IPUs or Google’s TPUs). Finally, whether through increasing demand for computation (benefiting digital cloud providers) or improving the existing stack, more MLOSS usage often increases the value of existing capabilities. Google’s Colab plausibly has significantly increased adoption because of the widespread use of TensorFlow; Facebook/Meta’s face recognition and image captioning capabilities have significantly improved as a result of sharing PyTorch.
Startups provide MLOSS for community and to complement existing or future products. The community, while not an end in and of itself, serves as a generally powerful moat that helps exert cultural influence, improve products, provide routes to monetization, and grants a sense of collective meaning. Hugging Face, which provides the most popular large language models package, is one example of this. After open sourcing powerful and accessible packages for using language models, Hugging Face garnered a dedicated community of followers. In 2022, the company became cash flow positive by charging to train or perform inference on models, and also by consulting for large enterprise customers. The community has allowed them to hire talent, improve existing products, and find customers for their services.
Sociotechnical forces
Outside of funding and ideology, there were a number of sociotechnical forces that clearly shaped MLOSS. Below are three of the most prominent.
1. The most usable software tends to win
The usability of a tool effectively acts as a selection pressure, favoring the tools with the most intuitive user interface. Notably, PyTorch’s imperative-style specification of neural networks was eventually adopted by TensorFlow. This is despite the initial lack of support for imperative approaches to production systems. The competition between TensorFlow’s graph-based execution and PyTorch’s eager execution recalls the famous Lisp vs C, or ‘the right thing’ vs ‘worse is better’. Just as the simpler, less complete, ‘worse’ C programming language prevailed in adoption over the more complicated, complete, ‘right’ Lisp language, so too did PyTorch’s simpler approach prevail over TensorFlow’s more efficient graph-based model.
2. Some code wants to be standardized
Consider two common tasks in machine learning: dataset manipulation and matrix differentiation. Dataset manipulation varies highly between datasets but requires few steps. Matrix differentiation, in contrast, is very similar between models, but requires many steps. The tedium and similarity of matrix differentiation meant that it was one of the first tasks to be standardized in software. In general, tasks that are modular, homogenous, and detailed, will be standardized first.
3. Research community interest
MLOSS is also significantly shaped by the prevailing paradigm within machine learning. The predominant model type for machine learning is currently deep learning. This then drives the creation of deep learning (as opposed to alternate ML paradigms such as probabilistic programming or automated planning) MLOSS tools.
Of course, the prevailing paradigm within machine learning is itself a product of a large number of different factors. The state of hardware, the most prestigious benchmarks, the commercial applicability, are all important in shaping the dominant approach within machine learning. For a thoughtful consideration of this topic, we point the reader to Dotan and Milli (2019).
Ideology
A final, critical, aspect of MLOSS development is the role of ideology. Most of the key figures in MLOSS are motivated by particular visions of the world. These visions may be religious in nature or the consequence of strongly held values. These values tend to either be about helping improve the experience of other fellow developers, or else furthering the state of AI.
Travis Oliphant, the creator of NumPy, one of the most commonly used libraries in Python, tells the story of creating NumPy as an act of public service against the wishes of his advisors and peers at Brigham Young University[2].
Other developers believe in the pure good of furthering AI. In a podcast interview, when asked for the reason Facebook sponsors PyTorch, Soumith Chintala explains that “we have a single point agenda at [Facebook AI Research], which is to solve AI” which involves empowering others to work on the problem. The implication seems to be that ‘solving AI’ would lead to enormous upside for society, whether by allowing new drugs to be discovered or by proving new theorems. Similarly, H2O.ai and Hugging Face both refer to ‘democratizing AI’ as a central motivation for open sourcing their products.[3]
Self-reinforcing feedback loops in deep learning
In this section, we’ll discuss the ways in which the proliferation of MLOSS may have selectively favored one type of machine learning (deep learning) over other types.
Alternatives to the Deep Learning Paradigm in AI
Beyond deep learning, other paradigms in AI research include probabilistic machine learning[4], rule-based expert systems[5], and automated planning[6]. As some of our interviewees pointed out, although Deep Learning is the dominant paradigm in ML/AL research, it is hard to disentangle the reasons for deep learning's progress. Clearly, there is some degree of technological advantage, however, there is also substantial engineering advantage as the MLOSS ecosystem has progressed. At best, it is difficult to evaluate the counterfactual of how technology would have progressed if alternative approaches had similar resources. At worst, deep learning has created a self-reinforcing dynamic where the ecosystem effects are more important than the advantages of the underlying technology.
For one example where deep learning is not clearly superior, consider verifying flight software. The stakes of buggy flight software are very high and require a large degree of certainty. In such domains, engineers opt to use theorem provers, which are closely linked to automated planning, to formally verify that the software is free of bugs. This is a task that deep learning algorithms are currently ill-suited for because they cannot provide formal guarantees.
Better support for deep learning tools reinforces deep learning
There are two ways that current MLOSS tools favor deep learning: decreasing developer friction and shifting researcher incentives.
The two most popular open source tools in deep learning and in automated planning are, respectively, PyTorch and FastDownward. As a tool developed largely by the Facebook AI Research term, PyTorch is incredibly well supported. A user can typically resolve technical issues with a single search engine query, which parses tens of thousands of posts and active users. There are dozens of helpful snippets of code detailing how to, for instance, debug tensors with mismatched dimensions.
Now consider FastDownward. Installation is non-trivial and requires basic knowledge of operating systems to download a compressed bundle of files (tarball) and to manually configure installation.It’s difficult to get immediate support if a user runs into technical issues: In most of the bug queries we tried, a straightforward search via a search engine did not yield answers, and we had to turn to their custom forum. This is not to disparage FastDownward, but to point out the large differences in user experience that a team of full-time engineers can make.
Over the course of the interviews, we saw how small differences in the friction surrounding tool use drove the movement to PyTorch over TensorFlow. We believe that ease of tool use also significantly affects the problems that researchers choose to focus on. In this way, the current most popular MLOSS tools (PyTorch, JAX, Hugging Face …) have fostered work on deep learning that is not a direct consequence of the scientific merit of deep learning as an AI paradigm.
Another way that MLOSS has reinforced deep learning is that, because of the strong ecosystem support, deep learning tools have become productionized, making deep learning engineering a highly desirable skillset. Because deep learning tools are so easy to use, reliable, and supported by a large user community, many companies can use deep learning. Companies have en masse begun to apply deep learning via tools like TensorFlow, which has resulted in many more jobs in industry for experts in deep learning than in other paradigms[7]. There is also much higher demand in industry for jobs that involve deep learning. On Indeed.com, there were over 15k jobs including the description ‘deep learning’. For ‘probabilistic programming’ and ‘automated planning’, there were 40 and 8 jobs, respectively[8].
The Future of MLOSS
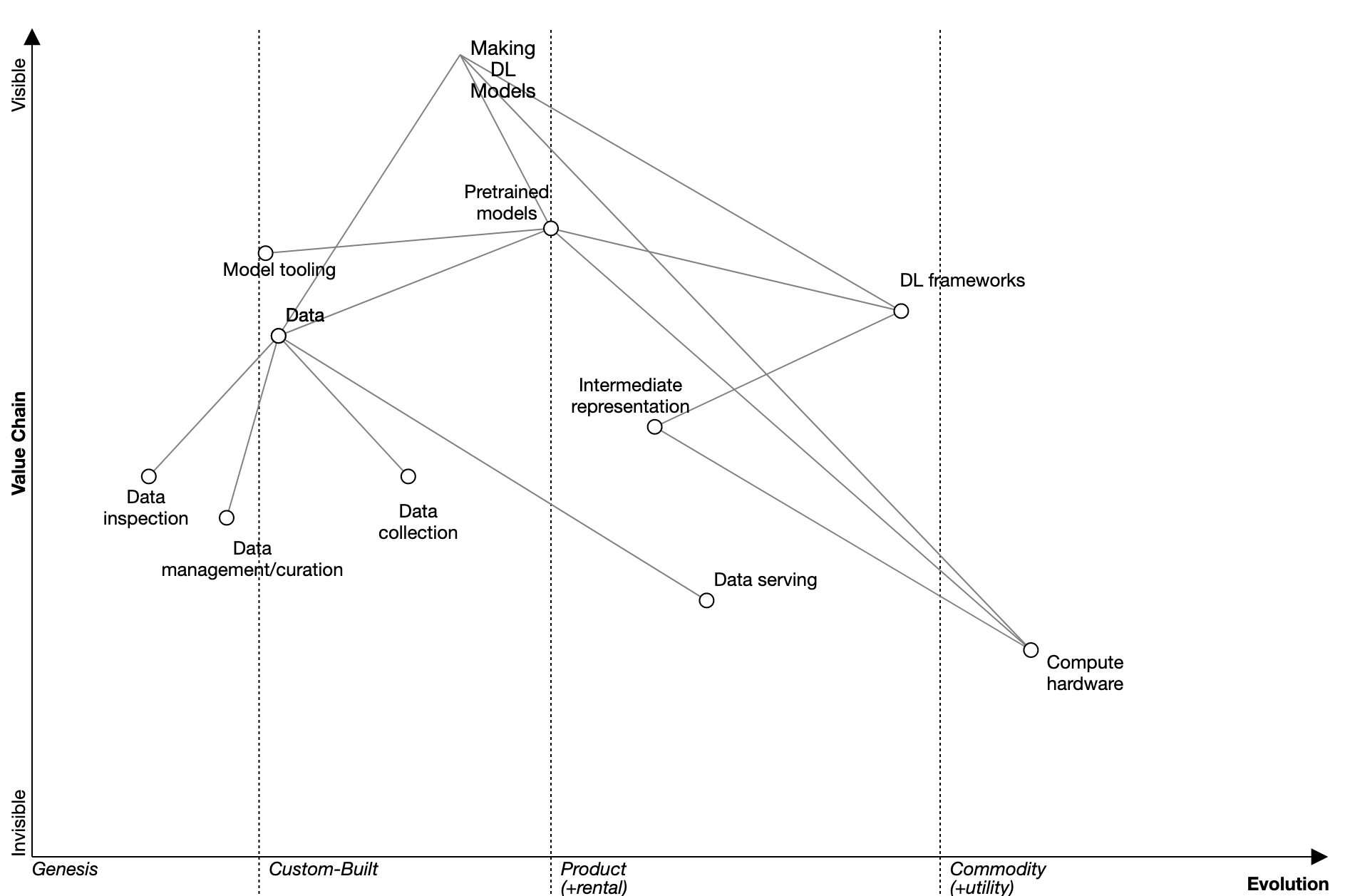
Fig 3. Expanded Wardley map of deep learning models
The Wardley map, as introduced earlier, can give some intuition for the trajectory of technological development. In general, capabilities to the left (i.e. less developed) become the bottleneck and attention in the ecosystem will turn to addressing these relatively neglected features. This map, when combined with our qualitative evidence, informs these next four trends we identify.
Trend 1: Attention shifts away from deep learning frameworks
Despite the history of intense competition among deep learning frameworks (PyTorch and TensorFlow, there was Chainer, Theano, Torch; Huawei recently released MindSpore), expressing deep learning models using frameworks is no longer a bottleneck. Soumith Chintala, one of the creators of PyTorch, provides a suggestive quote: “With PyTorch and TensorFlow, you’ve seen the frameworks sort of converge... the next war is compilers for the frameworks — XLA, TVM, PyTorch has Glow, a lot of innovation is waiting to happen.”
Trend 2: More tooling for large pretrained models
Many recent notable projects have iterated on large pretrained models. Github’s Copilot , the large model designed to assist with Python code-writing, was a finetuned version of GPT-3[12]. At the most basic level, this would involve infrastructure for serving pretrained models. The current large language models are too large to run on a single computer, and we already see services like OpenAI’s GPT-3 API and Hugging Face’s serving infrastructure meeting this need. Later tools could address allow for managing different model versions, meta-frameworks for composing large distinct pretrained models, and tools for incorporating different modalities (e.g. vision, sound, text) into pretrained models.
Trend 3: Greater variety of (potentially closed-source) data tooling
Many startups are trying to address the current ad-hoc nature of working with data, but there has yet to be a consolidation on a single tool. More broadly, with movements like Andrew Ng’s ‘data-centric AI’, many researchers feel that data has been neglected as a focus for tooling and research. If they are correct, then tools for data inspection and production will become especially important.
Whether these future tools will be open sourced depends on the scale of the task. Systems that require petabytes of data, such as Tesla’s self-driving car pipeline, are far less likely to be open sourced than the gigabyte-sized experiments at a university or small startup. One plausible scenario is a bifurcation between large and small scale tools. The large scale tools are provided by proprietary platforms like Scale whereas some fraction of the small scale data tools are open source and freely available to researchers.

Table 1. Different types of data tools
A brief reflection on risks
What do trends in data tooling imply for medium term risks from machine learning? It seems that the trends within data tooling, similar to the trends in computation, point towards increasing concentration of capabilities into a small number of firms. This may allow for easier regulation; governments have in the past successfully demonstrated the ability to regulate monopolies emerging from general purpose technologies like electricity. However, it may be much more concerning that these capabilities are developing far more rapidly than our wisdom of how to control our technologies.
Community norms within MLOSS also have significant bearing on potential risks. Because many communities within MLOSS are quite strong, if an influential community disregards safety concerns about releasing powerful AI systems, we believe that developers of high risk models (e.g. deadly virus generation) are much more likely to release their model publicly. Since AI systems are often composable, we might expect nonlinear increases in risk with model proliferation. Because a bad actor can combine models from different modalities, doubling the number of openly available models is likely more than doubling the risk of harm. If we take this line of reasoning seriously, it is crucial to foster cautious norms around model release early on.
Predictions
In the service of trying to make our research more accountable, we provide a number of predictions about the future landscape. Each prediction is accompanied with an event probability:
- PyTorch, and JAX will be two of top three frameworks for deep learning ac- cording to Paperswithcode (outside of China) as of January 2027. 0.75
- Python will be the most popular language for machine learning in 2027. 0.90
- ONNX will become accepted as the dominant intermediate representation framework. 0.70
- Between 2023-2027, none of the top publicly disclosed 5 largest language models will be open sourced. 0.8
- As of 2027, the three most popular platforms that provide data tooling are largely proprietary/do not open source a crucial part of their stack. 0.7
These prediction questions are not without ambiguity, and are mostly based on our intuition. Nonetheless, we believe these rough predictions are more useful to provide than omit, so we have included them here.
Questions for further investigation
- What properties are shared/different between MLOSS and OSS within other domains (say compilers like LLVM)?
- How do we expect the evolution of data tooling to be different from framework tooling?
- How different are the capabilities required for scaling up probabilistic programming versus deep learning (specifically compute)?
- How does MLOSS in China differ from those in the U.S? What does this imply about the diffusion of knowledge about AI research?
- How are the incentives for open sourcing data tools different than the incentives for other MLOSS (especially frameworks)?
- ^
Allan Dafoe. AI Governance: A Research Agenda. University of Oxford, August 2018.
- ^
Travis oliphant: NumPy, SciPy, anaconda, python & scientific programming | lex fridman podcast #224 - YouTube https://www.youtube.com/watch?v= gFEE3w7F0ww&t=3089s.
- ^
For further discussion of the role of ideology in AI, see also How AI Fails Us
- ^
Zoubin Ghahramani. Probabilistic machine learning and artificial intelligence. Nature, 521(7553):452–459, May 2015. Number: 7553 Publisher: Nature Publishing Group.
- ^
Randall Davis and Jonathan J King. The origin of rule-based systems in AI. Rule-based expert systems : The MYCIN experiments of the Stanford heuristic programming project / Edited by Bruce G. Buchanan and Edward H. Shortliffe, 1984. Place: S.l. Publisher: s.n. OCLC: 848324685
- ^
Richard E. Fikes and Nils J. Nilsson. Strips: A new approach to the application of theorem proving to problem solving. Artificial Intelligence, 2(3):189–208, December 1971
- ^
Google AI. Case Studies and Mentions - TensorFlow https://web. archive.org/web/20220228134129/https://www.tensorflow.org/about/ case-studies, 2022
- ^
Indeed.com. Deep Learning job query. https://www.indeed.com/jobs?q=Deep\ %20Learning&l&vjk=87d0802a025023b4. Website, 2022.; Indeed.com. Probabilistic programming job query. https://www.indeed.com/ jobs?q=Probabilistic\%20Programming&l&vjk=4ac08ba6112c10e2. Website, 2022.
Really cool topic, thanks for sharing. One of the ways that alignment techniques could gain adoption and reduce the alignment tax is by integrating them into popular open source libraries.
For example, the library TRL allows researchers to implement RLHF techniques which can benefit safety, but can also contribute to dangerous capabilities. On the other hand, I'm not aware of any open-source implementation of the techniques described in Red Teaming LMs with LMs, which could be used to filter or fine-tune the outputs of a generative language model.
Hopefully we'll see more open source contributions of safety techniques, which could bring more interest to safety topics. Some might argue that implementing safety techniques in current models doesn't reduce x-risk, and they're probably right that current models aren't directly posing x-risks, but early adoption of safety techniques seems useful for ensuring further adoption in the years to come.
New open source implementation of factored cognition / IDA techniques from Ought! https://www.lesswrong.com/posts/X5L9g4fXmhPdQrBCA/a-library-and-tutorial-for-factored-cognition-with-language
Thanks for posting this, this seems like valuable work.
I'm particularly interested in using MLOSS to intentionally shape AI development. For example, could we identify key areas where releasing particular MLOSS can increase safety or extend the time to AGI?
Finding ways to guide AI development towards narrow and simple AI models can extend AI timelines, which is complimentary to safety work:
https://www.lesswrong.com/posts/BEWdwySAgKgsyBzbC/satisf-ai-a-route-to-reducing-risks-from-ai
In your opinion, what traits of a particular piece of MLOSS determine whether it increases or decreases risk?