This is a linkpost for https://deepmind.google/technologies/gemini/
Gemini Pro (the medium-sized version of the model) is now available to interact with via Bard.
Here’s a fun and impressive demo video showing off Gemini’s multi-modal capabilities:
[Edit, Dec. 8 at 5:54am EST: This demo video is potentially misleading.]
How Gemini compares to GPT-4, according to Google DeepMind:
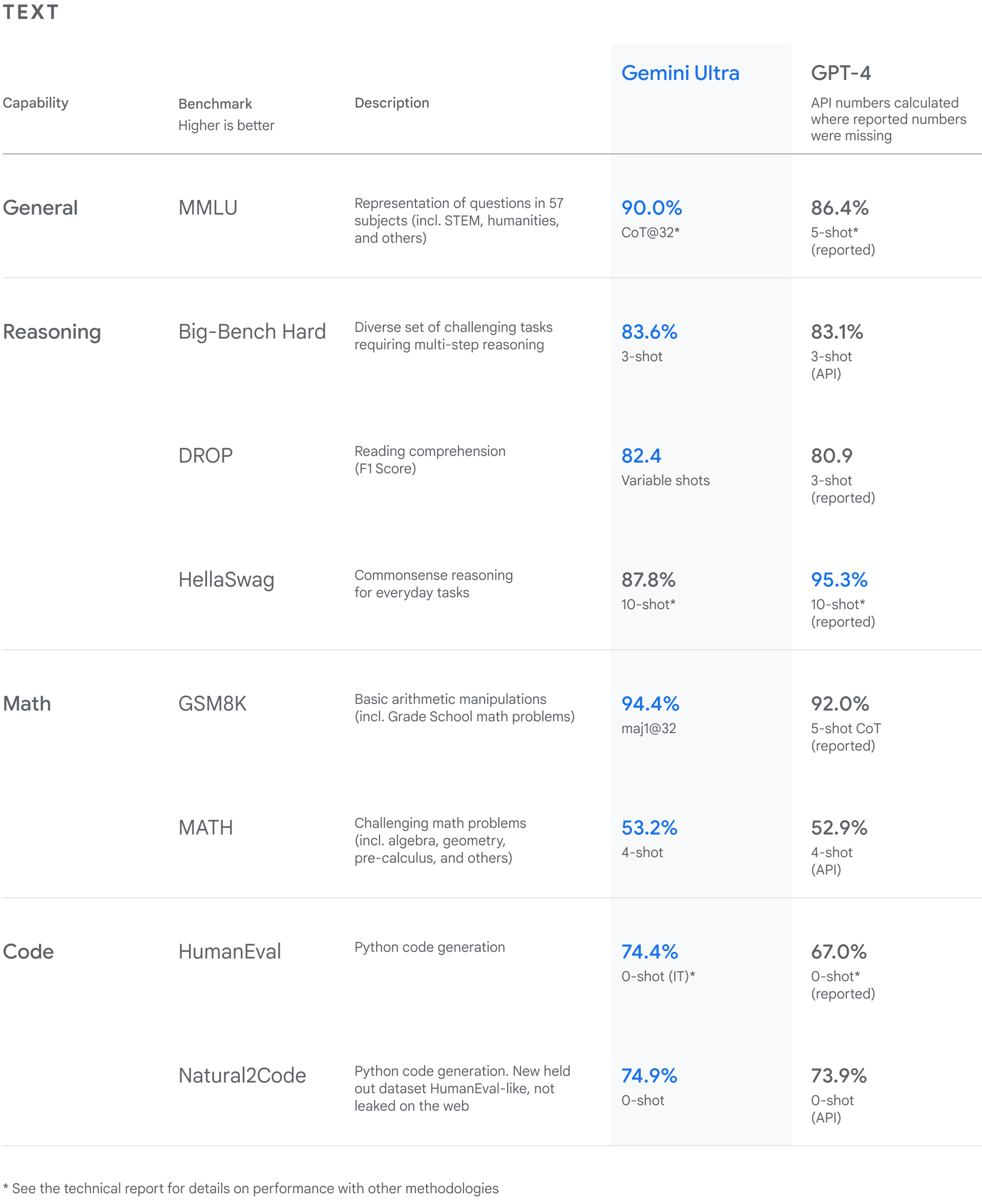
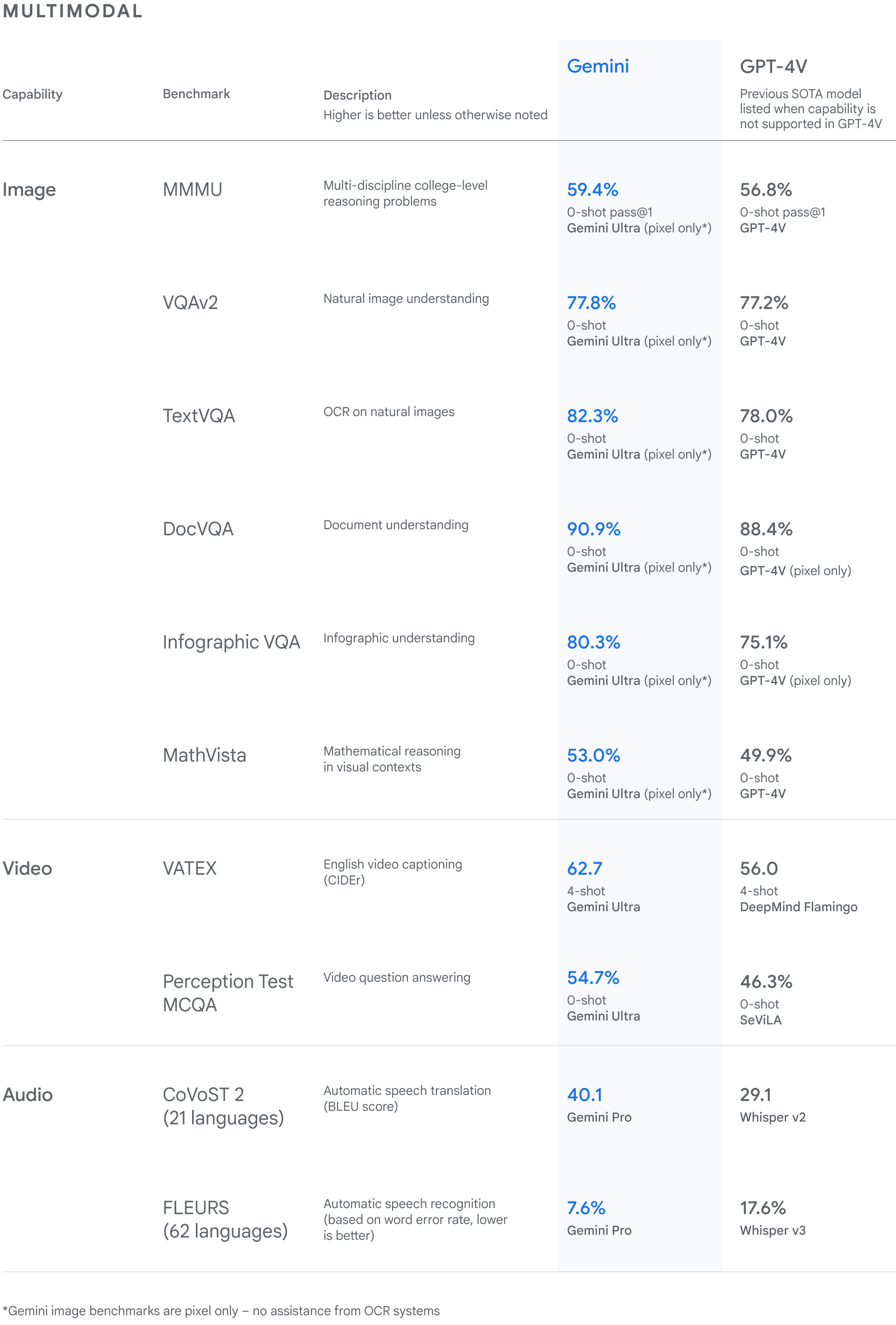
warning - mildly spicy take
In the wake of the release, I was a bit perplexed by how much of Tech Twitter (answered by own question there) really thought this a major advance.
But in actuality a lot of the demo was, shall we say, not consistently candid about Gemini's capabilities (see here for discussion and here for the original).
At the moment, all Google have released is a model inferior to GPT-4 (though the multi-modality does look cool), and have dropped an I.O.U for a totally-superior-model-trust-me-bro to come out some time next year.
Previously some AI risk people confidently thought that Gemini would be substantially superior to GPT-4. As of this year, it's clearly not. Some EAs were not sceptical enough of a for-profit company hosting a product announcement dressed up as a technical demo and report.
There have been a couple of other cases of this overhype recently, notably 'AGI has been achieved internally' and 'What did Ilya see?!!?!?' where people jumped to assuming a massive jump in capability on the back on very little evidence, but in actuality there hasn't been. That should set off warning flags about 'epistemics' tbh.
On the 'Benchmarks' - I think most 'Benchmarks' that large LLMs use, while the contain some signal, are mostly noisy due to the significant issue of data contamination (papers like The Reversal Curse indicate this imo), and that since LLMs don't think as humans do we shouldn't be testing them in similar ways. Here are two recent papers - one from Melanie Mitchell, one about LLMs failing to abstract and generalise, and another by Jones & Bergen[1] from UC San Diego actually empirically performing the Turing Test with LLMs (the results will shock you)
I think this announcement should make people think near term AGI, and thus AIXR, is less likely. To me this is what a relatively continuous takeoff world looks like, if there's a take off at all. If Google had announced and proved a massive leap forward, then people would have shrunk their timelines even further. So why, given this was a PR-fueled disappointment, should we not update in the opposite direction?
Finally, to get on my favourite soapbox, dunking on the Metaculus 'Weakly General AGI' forecast:
tl;dr - Gemini release is disappointing. Below many people's expectations of its performance. Should downgrade future expectations. Near term AGI takeoff v unlikely. Update downwards on AI risk (YMMV).
I originally thought this was a paper by Mitchell, this was a quick system-1 take that was incorrect, and I apologise to Jones and Bergen.
I think the update here should be pretty small. I'm unsure if you disagree. I would also think the update should be pretty small if gemini is notably better than GPT4, but not wildly better. It seems plausible to me that people would (incorrectly) have a large update toward shorter timelines if gemini was merely substantially better than GPT4, but we don't have to make the same mistake in the other direction.
It's worth noting there is some asymmetry in the likely updates with a high probability of a mild negative update on near term AI and a low probability of a large positive update toward powerful near term AI. E.g., even if google were to explode and never release a better LLM than gemini, this would be a relatively smaller update than if they were to release transformatively powerful AI.
Hey Ryan, thanks for your engagement :) I'm going to respond to your replies in one go if that's ok
#1:
This is a good point. I think my argument would point to larger updates for people who put susbtantial probability on near term AGI in 2024 (or even 2023)! Where do they shift that probability in their forecast? I think just dropping it uniformly over their current probability would be suspect to me. So maybe it'd wouldn't be a large update for somebody already unsure what to expect from AI development, but I think it should probably be a large update for the ~20% expecting 'weak AGI' in 2024 (more in response #3)
#2:
Yeah I suppose ~80%->~60% is a decent update, thanks for showing me the link! My issue here would be the resolution criteria realy seems to be CoT on GSM8K, which is almost orthogonal to 'better' imho, especially given issues accounting for dataset contamination - though I suppose the market is technically about wider perception rather than technical accuracy. I think I was basing a lot of my take on the response on Tech Twitter which is obviously unrepresentative, and prone to hype. But there were a lot of people I generally regard as smart and switched-on who really over-reacted in my opinion. Perhaps the median community/AI-Safety researcher response was more measured.
#3:
I'm sympathetic to this, but Metaculus questions are generally meant to be resolved according a strict and unambiguous criteria afaik. So if someone thinks that weakly general AGI is near, but that it wouldn't do well at the criteria in the question, then they should have longer timelines than the current community response to that question imho. The fact that this isn't the case to me indicates that many people who made a forecast on this market aren't paying attention to the details of the resolution and how LLMs are trained and their strengths/limitations in practice. (Of course, if these predictors think that weak AGI will happen from a non-LLM paradigm then fine, but then i'd expect the forecasting community to react less to LLM releases)
I think where I absolutely agree with you is that we need different criteria to actually track the capabilities and properties of general AI systems that we're concerned about! The current benchmarks available seem to have many flaws and don't really work to distinguish interesting capabilities in the trained-on-everything era of LLMs. I think funding, supporting, and popularising research into what 'good' benchmarks would be and creating a new test would be high impact work for the AI field - I'd love to see orgs look into this!
B
For the Metaculus question? I'd be very upset if I had a longer-timeline prediction that failed because this resolution got changed - it says 'less than 10 SAT exams' in the training data in black and white! The fact that these systems need such masses of data to do well is a sign against their generality to me.
I don't doubt that the Gemini team is aware of issues of data contamination (they even say so at the end of page 7 in the technical report), but I've become very sceptical about the state of public science on Frontier AI this year. I'm very much in a 'trust, but verify' mode and the technical report is to me more of a fancy press-release that accompanied the marketing than an honest technical report. (which is not to doubt the integrity of the Gemini research and dev team, just to say that I think they're losing the internal tug-of-war with Google marketing & strategy)
#4:
Ah good spot. I think I saw Melanie share it on twitter, and assumed she was sharing some new research of hers (I pulled together the references fairly quickly). I still think the results stand but I appreciate the correction and have amended my post.
<> <> <> <> <>
I want to thank you again for the interesting and insightful questions and prompts. They definitely made me think about how to express my position slightly more clearly (at least, I hope I make more sense to you after this reponse, even if we don't agree on everything) :)
Thanks for the response!
A few quick responses:
Good to know! That certainly changes my view of whether or not this will happen soon, but also makes me think the resolution criteria is poor.
You might be interested in the recent OpenPhil RFP on benchmarks and forecasting.
People around me seemed to have a reasonably measured response.
I think we'll probably get a pretty big update about the power of LLM scaling in the next 1-2 years with the release of GPT5. Like, in the same way that each of GPT3 and GPT4 were quite informative even for the relatively savvy.
[Unimportant]
This doesn't seem to be by Melanie Mitchell FYI. At least she isn't an author.
I think this slightly misrepresents the corresponding article and the state of the forecasts. The quote from the linked article is:This doesn't seem to exhibit that much confidence in "gemini being substantially superior"? I expect that if Zvi gave specific probabilites, they would be pretty reasonable.ETA: I retract my claim about Zvi, on further examination, he seems pretty wrong here. That said, manifold doesn't seem to have done too badly.
Further, manifold doesn't seem that wrong here on GPT4 vs gemini? See for instance, this market:
The forecast has updated from 80% to about 60%, which doesn't seem like much of an update.
I agree that we should update down on google competence and near term AGI, but it just doesn't seem like that big of an update yet?
I think the forecast seems broadly reasonable, but the question and title seem quite poor. As in, the operationalization seems like a very poor definition for "weakly general AGI" and the tasks being forecast don't seem very important or interesting.
I think GPT-4V likely already achieves 2 (winograd) and 3 (SAT) while 4 (montezuma's revenge) seems plausible for GPT-4V, though unclear. Beyond this, 1 (turing test) seems to be extremely dependent on the extent to which the judge is competently adversarial and whether or not anyone actually finetunes a powerful model to perform well on this task. This makes me think that this could plausibly resolve without any more powerful models, but might not happen because no one bothers running a turing test seriously.
Can't we just use an SAT test created after the data cutoff? Also, my guess is that the SAT results discussed in the GPT-4 blog post (which are >75th percentile) aren't particularly data contaminated (aside from the fact that different SAT exams are quite similar which is the same for human students). You can see the technical report for more discussion on data contamination (though account for bias accordingly etc.)