Supported by Rethink Priorities
This is part of a weekly series summarizing the top posts on the EA and LW forums - you can see the full collection here. The first post includes some details on purpose and methodology. Feedback, thoughts, and corrections are welcomed.
If you'd like to receive these summaries via email, you can subscribe here.
Podcast version: Subscribe on your favorite podcast app by searching for 'EA Forum Podcast (Summaries)'. A big thanks to Coleman Snell for producing these!
Author's note: I'm on leave next week, so the next summary post will be ~21st Feb. It'll capture both of the prior weeks at a higher karma bar than usual.
Object Level Interventions / Reviews
AI
Google invests $300mn in artificial intelligence start-up Anthropic | FT
by 𝕮𝖎𝖓𝖊𝖗𝖆
Linkpost for this article. Google has invested $300M in return for a ~10% stake. It also requires Anthropic to use the funds to buy computing resources from Google. Anthropic has a chatbot ‘Claude’ which rivals ChatGPT, but has not been released publicly. Google is also working with other AI startups such as Cohere and C3.
by Jaime Sevilla
Epoch is a research group forecasting the development of Transformative Artificial Intelligence (TAI), founded in April 2022. Their full impact report is here. They currently employ 9 FTEs, have received $1.96M funding from Open Philanthropy, and are fiscally sponsored by Rethink Priorities. Their goal is to fundraise $7.07M to cover the 2 years September 2023 - September 2025, including expansion of their research capacity. You can donate here, or subscribe to their newsletter here.
Key research in 2022 included investigating training compute trends, model size trends, data trends, hardware trends, algorithmic progress, and investment trends. These are accessible on their website and being used by Anthropic, GovAI, MIT FutureTech, 80K, and Our World in Data among others.
What I mean by "alignment is in large part about making cognition aimable at all"
by So8res
The author has long-said that the AI alignment problem seems to be about pointing powerful cognition at anything at all, rather than figuring out what to point it at.
They clarify that what they mean is: by default, they expect the first minds humanity makes to be spaghetti-code mess with no clearly factored out “goal” that the cognition pursues in a unified way. What they don’t mean is the AI will have a goal slot, and it’s just hard to put our own objective into it.
They also separately believe that by the time an AI reaches superintelligence, it will in fact have oriented itself around a particular goal and have something like a goal slot in its cognition - but at that point, it won’t let us touch it, so the problem becomes we can't put our own objective into it.
Inner Misalignment in "Simulator" LLMs
by Adam Scherlis
The author argues that the “simulators” framing for LLMs shouldn’t reassure us much about alignment. Scott Alexander has previously suggested that LLMs can be thought of as simulating various characters eg. the “helpful assistant” character. The author broadly agrees, but notes this solves neither outer (‘be careful what you wish for’) or inner (‘you wished for it right, but the program you got had ulterior motives’) alignment.
They give an example of each failure case:
For outer alignment, say researchers want a chatbot that gives helpful, honest answers - but end up with a sycophant who tells the user what they want to hear. For inner alignment, imagine a prompt engineer asking the chatbot to reply with how to solve the Einstein-Durkheim-Mendel conjecture as if they were ‘Joe’, who’s awesome at quantum sociobotany. But the AI thinks the ‘Joe’ character secretly cares about paperclips, so gives an answer that will help create a paperclip factory instead.
Compendium of problems with RLHF
by Raphaël S
Aims to identify the key technical gaps that need to be addressed for an effective alignment solution involving Reinforcement Learning from Human Feedback (RLHF).
RLHF is progress because it can do useful things now (like teach ChatGPT to be polite - a complex, fragile value) and withstands more optimization pressure than hand-crafted reward functions.
However, it’s currently insufficient because of:
- Non-robust ML systems: eg. ChatGPT can fail, even more so after push-back from the public against its refusal to answer some things. This kind of error may disappear in future, but it's unclear if it will.
- Incentive issues in reinforcement learning: eg. it wants a human to hit ‘approve’ - even if this involves deception. It may also over-agree with a user’s sensibilities or steer the topic toward positive sentiment subjects like weddings, and its trains of thought may be hard to read due to being mainly association.
- Problems with the human feedback part: human raters make errors, ChatGPT has heaps of raters and still has issues, and scaling feedback while maintaining its quality is hard.
- Superficial outer alignment: RLHF doesn’t involve values explicitly, only a process that we hope will 'show' it values through examples. You can also fine-tune an existing model in a bad direction eg. by asking it to mimic someone with bad values.
- The strawberry problem: the problem of getting an AI to place two identical (to cellular level) strawberries on a plate and then do nothing else. Requires capability, pointing at a goal, and corrigibility (we can tell it to stop, and it will). RLHF may not solve this, though the same could be said for other alignment approaches too.
- Unknown properties under generalization: it may not generalize well to new situations, may need to do negative actions (such as killing people) so we can give feedback on what is bad, or may act very differently at higher levels of performance or in dangerous domains.
Assessing China's importance as an AI superpower
by JulianHazell
Summary of this shallow dive by the author. Bottom line takes (with confidence levels) include:
- China is moderately likely (60%) overhyped as an AI superpower, and recent AI research output is not as impressive as headlines suggest (75%). The US is more likely to create TAI, particularly given timelines of 5-15 years (70%).
- Lagging the US and allies might only mean being a year or two behind (65%), and China is still worth watching (90%).
- Hardware difficulties and top-tier researchers moving to other countries are the biggest hurdles China currently faces and not easily solvable (60%).
Some of the key factors informing their view are:
- China’s research on important AI topics like transformer architectures is less impressive than headlines would indicate.
- They suspect China’s economic growth will slow, making spending on large speculative projects like TAI difficult.
- China has a massive problem with producing compute, restrictions from the US on accessing computing power, and no proposed solutions sufficient to combat this. The most promising short-to-medium term TAI paths require lots of computing power.
- First mover advantage is real - the most important actors from a governance POV are those most likely to develop TAI first.
- China will struggle with talent if it relies on Chinese-born scientists, who return to China at low rates. Foreign workers are often looking for somewhere more liberal and with higher quality-of-life.
They also acknowledge with 95% confidence that they’re probably missing important factors.
Other Existential Risks (eg. Bio, Nuclear)
by Jam Kraprayoon
Ultraviolet germicidal irradiation technology (UVGI) or germicidal UV light (GUV) represents a promising technology for reducing catastrophic biorisk and would likely confer near-termist benefits as well. Rethink Priorities ran four surveys in November / December 2022 to understand US public attitudes towards these technologies. The results showed low to moderate awareness, with support once technologies were described. Respondent’s main concern was the need for additional testing on safety and efficacy. There was slightly greater support for far-UVC over upper-room UVC (contrary to assumptions going in, since far-UVC involves direct human exposure to the light), and no statistically significant difference in support when using terms mentioning UV vs. not.
Biosecurity newsletters you should subscribe to
by Sofya Lebedeva
A list of 16 biosecurity newsletters that readers may find helpful.
Nelson Mandela’s organization, The Elders, backing x risk prevention and longtermism
by krohmal5
Linkpost for this post from The Elders, an organization founded by Nelson Mandela in 2007. They give a strong endorsement of x-risk priorities, including stating: “For the next five years, our focus will be on the climate crisis, nuclear weapons, pandemics, and the ongoing scourge of conflict. [...] We are approaching a precipice. The urgency of the interconnected existential threats we face requires a crisis mindset from our leaders – one that puts our shared humanity centre-stage, leaves no one behind, and recognises the rights of future generations.”
Animal Welfare
Longtermism and animals: Resources + join our Discord community!
by Ren Springlea
There are compelling reasons to help nonhuman animals in the long-term future, and the intersection between longtermism and animal advocacy is starting to receive more attention in EA. The author shares a list of posts / resources on the topic, and invites those interested to join this discord.
They also share that they had funding from an FTX regrantor to do systematic research for identifying the best interventions in this space, but that has fallen through. They link their original brainstorm in case anyone wants to pick off where they left off.
Global Health and Development
What I thought about child marriage as a cause area, and how I've changed my mind
by Catherine Fist
After 80 hours of research into child marriage as a cause area, the author believed there was a relatively strong case for funding. It seemed widespread (12 million girls per year), tractable (cost per marriage averted of US$159 - US$732), and neglected.
While attempting to quantify the effect in terms of QALYs / DALYs, they found a meta-analysis showing that evidence on the effect of child marriage for many metrics (eg. contraceptive use, maternal health, nutrition, decision-making power and mental wellbeing) is mixed. Note it is still strongly linked to risk of physical violence and lower attendance in school. This updated their views to be less sure of this as a cause area, and they are now focusing more narrowly on the effects of physical violence and decreased attendance. In future they plan to list their assumptions and search for sources that disagree upfront, in addition to being more skeptical of positions of large institutions, and finding someone to play a supervisor / challenger role for their self-directed projects.
Forecasting Our World in Data: The Next 100 Years
by AlexLeader
Metaculus recently predicted 30 Our World in Data metrics over the next 100 years, via a public tournament and a group of pro forecasters. This helped them identify these common approaches in forecasting:
- Referencing peers’ comments and predictions
- Referencing other Metaculus forecasts
- Extrapolating from growth rates
- Anticipating exogenous (external) shocks
- Acknowledging uncertainties
They were also able to see rationales driving predictions for each time period, and a composite perspective into our world 100 years from now. Questions included things such as the cost of sequencing a human genome, FLOPS of the fastest supercomputer, and number of chickens slaughtered for meat. I won’t include results for brevity given 30 metrics, but check out the post for tables, grapes, and commentary of results from both pros and the public tournament on each measure.
On not getting contaminated by the wrong obesity ideas
by Natália Coelho Mendonça
A Chemical Hunger argues that the obesity epidemic is entirely caused by environmental contaminants. The author originally found this plausible, given chemicals can affect humans and our exposure has changed a lot over time. However, after exploring the strongest arguments in favor, they find that the evidence is dubious and contains factual errors. They now believe it very unlikely that this hypothesis will be found true.
Opportunities
CE Incubation Programs - applications now open + updates to the programs
by KarolinaSarek
Applications are open for two upcoming Charity Entrepreneurship rounds:
- July - August 2023: focus on biosecurity and large-scale global health interventions
- February - March 2024: focus on farmed animals and global health and development mass-media interventions
They’ve made several changes to the program, including increased funding, more in-person time in London, extended support for participants, and more time for applications.
They also share that in the past 2 years they’ve trained 34 people, and 100% of them have gone on to roles with high personal fit and excellent impact potential (20 launching new charities, 6 working at EA orgs, and a variety of other cases including launching a grantmaking foundation and being elected to district parliament).
Rationality, Productivity & Life Advice
Focus on the places where you feel shocked everyone's dropping the ball
by So8res
If you’re looking for ways to help the world be less doomed, look for places where we’re all being total idiots. If it seems like there’s a simple solution to something, solve it. If something seems incompetently run, run it better.
If you don’t see these opportunities, the author suggests cultivating an ability to get excited about things, and doing cool stuff. This will help with being motivationally ready when an opportunity does come up.
Community & Media
We're no longer "pausing most new longtermist funding commitments"
by Holden Karnofsky
In November 2022, Open Philanthropy (OP) announced a soft pause on new longtermist funding commitments, while they re-evaluated their bar for funding. This is now lifted and a new bar set.
The process for setting the new bar was:
- Rank past grants by both OP and now-defunct FTX-associated funders, and divide these into tiers.
- Under the assumption of 30-50% of OP’s funding going to longtermist causes, estimate the annual spending needed to exhaust these funds in 20-50 years.
- Play around with what grants would have made the cut at different budget levels, and using a heavy dose of intuition come to an all-things-considered new bar.
They landed on funding everything that was ‘tier 4’ or above, and some ‘tier 5’ under certain conditions (eg. low time cost to evaluate, potentially stopping funding in future). In practice this means ~55% of OP longtermist grants over the past 18 months would have been funded under the new bar.
OpenBook: New EA Grants Database
by Rachel Weinberg, Austin
openbook.fyi is a new website where you can see ~4,000 EA grants from donors including Open Phil, FTX Future Fund, and EA Funds in a single place.
Regulatory inquiry into Effective Ventures Foundation UK
by HowieL
The Charity Commission for England and Wales has announced a statutory inquiry into Effective Ventures Foundation UK (EVF UK) - the charity which along with EVF US acts as host and fiscal sponsor for CEA, 80,000 Hours, and others.
EVF UK’s interim CEO Howie Lempel wrote this post to keep the community up to date. Key points:
- The inquiry is focused on EVF UK’s financial situation, governance and administration. It isn’t an allegation of wrongdoing, and the Commission has noted in their statement that “there is no indication of wrongdoing by the trustees at this time”.
- They weren’t surprised by the inquiry, given some FTX-linked entities were major donors to EVF UK, with potential for conflicts of interest.
- The UK board and exec team are cooperating in full, and the Commission confirmed the trustees fulfilled their duties by filing a serious incident report.
- There will be limited updates during the inquiry because sharing in the middle of an inquiry is legally complicated, but they’ll share whatever they can.
Announcing Interim CEOs of EVF
by Owen Cotton-Barratt, Rebecca Kagan
EVF UK and EVF US are two separate charities and legal entities, while CEA, 80K, Longview etc. are projects they together host and fiscally sponsor.
Howie Lempel was appointed as EVF UK interim CEO in November 2022. Zachary Robinson was appointed as EVF US interim CEO 31st Jan 2023. Previously neither EVF had CEO positions, with project leads (eg. for CEA) instead reporting directly to EVF boards. Post-FTX, there has been more focus on financial and legal issues at the level of EVF as opposed to the project level, and on coordinating the legal / financial / communication strategies under EVF. This led to the decision to appoint interim CEOs to reduce the load on the board of managing this. These are time-limited roles intended to help transition to an improved long-term structure, and don’t constitute any change in project leadership.
Heaps more detail on the overall structure and reasons for it are available in the post.
Karma overrates some topics; resulting issues and potential solutions
by Lizka, Ben_West
Posts that are about the EA community, are accessible to everyone, or on topics where everyone has an opinion tend to get a lot more karma and attention on the EA forum. This can mislead about what the EA community cares about (eg. 10/10 top karma posts in 2022 were community posts, although <1/3rd of total karma went to that category). This in turn can lead people to start to value community-oriented topics more themselves, and direct even more attention to community-oriented, low barrier-topics.
To solve this, the EA forum team are considering a subforum or separate tab for ‘community opinion’ posts that is by default filtered out of the Frontpage, renaming ‘Top’ sorting to clearly indicate the karma dynamics, and/or having a higher karma bar for sharing community posts in places like the Digest.
Questions about OP grant to Helena
by DizzyMarmot
The author asks Open Philanthropy (OP) to clarify the reasoning on a $500K grant made to the organization Helena in 2022 to support their work on policy related to health security. The author claims they have no apparent expertise in the area to justify the grant, and that their scope of work is unfocused.
ASB, OP’s investigator on this grant, responded that based on their investigation (including reference calls on the impact claims made, and consideration of concerns like those in this post) they felt there was enough of a case to place a hits-based bet.
EA, Sexual Harassment, and Abuse
by whistleblower9
Linkpost to this Times article, which details allegations of multiple incidents of sexual harassment and abuse in EA.
Julia Wise from CEA’s community health team shares that the article contains a mix of cases where action was taken years ago (eg. banning the accused from EA spaces), cases where help was offered but the person affected didn’t answer, and cases they weren’t aware of. They're always available for contact (including anonymously) if you have information on a problem.
Let's advertise EA infrastructure projects, Feb 2023
by Arepo
A list of resources in EA, including for coworking/socializing, free or subsidized accommodation, professional services (eg. legal, data science, marketing, hiring, tech support), coaching, and financial / material support.
EA NYC’s Community Health Infrastructure
by Rockwell, MeganNelson, Alex R Kaplan
EA NYC shares their practices / infrastructure for supporting community health. They are happy to support other groups in creating similar practices.
Practices include:
- A paid PT community health coordinator (Megan Nelson), funded via CEA’s community building grants program. They are a confidential supportive resource for the community, run monthly dinners, give presentations on self-care, organize group accommodations, advise on policies and guidelines (eg. for coworking spaces) and more.
- Weekly community health calls, with the community health coordinator, community coordinator and director. Mainly proactive topics.
- Monthly dinners for coordination between community builders.
- Coordinating approaches and policies with other EA groups.
- WANBEANY (women and non-binary EAs of NY) meetups, and other affinity-focused meetups based on demand (eg. spanish-language meetups).
- More ideas being explored eg. a community health talk/workshop series, structured programming for discussing touchy topics, and a formalized DEI policy.
2022 Unofficial LessWrong General Census
by Screwtape
An unofficial census of LessWrong users - click here to take the survey, which will close on Feb 27th. You can choose if your responses are included in a public dataset, only in summaries of the data, or not at all.
FIRE & EA: Seeking feedback on "Fi-lanthropy" Calculator
by Rebecca Herbst
The author has made a FIRE (financial independence retire early) calculator which takes into account donation choices. It helps you figure out when you’ll have enough money to retire and live on investments indefinitely, given different levels of donation to charity (ie. X% of income). They hope this will encourage some in the FIRE community to donate, given they are often both a) optimizers and b) looking for meaning, and that pledging 1-10% can have a surprisingly small effect on early retirement timelines in many scenarios. They welcome feedback on the tool.
by Duncan_Sabien
The author explores, through a series of personal vignettes, the feeling of their way of being or thinking not being recognized. For instance, an article that says Tom Hanks had to be in Apollo 13, because everyone loves Tom Hanks and would root for them (but they don’t), or being told they’ll regret not being part of their high school graduation (but they never do), or being told ‘no one does that / no one believes that’ in conversation (but they do believe it).
Didn’t Summarize
Fucking Goddamn Basics of Rationalist Discourse by LoganStrohl (humor / parody post)
Special Mentions
A selection of posts that don’t meet the karma threshold, but seem important or undervalued.
Trends in the dollar training cost of machine learning systems
by Ben Cottier
Historical analysis of 124 machine learning systems published between 2009 and 2022 indicate that the cost for the final training run has grown by ~0.49 orders of magnitude per year (90% CI: 0.37 to 0.56). However, the cost for “large-scale” systems since 2015 has grown more slowly at an estimated ~0.2 orders of magnitude per year (90% CI: 0.1 to 0.4). Based on these figures and analysis of literature on likely growth rate models, the author predicts 0.2 orders of magnitude increases per year going forward (90% CI: 0.1 to 0.3 OOMs/year).
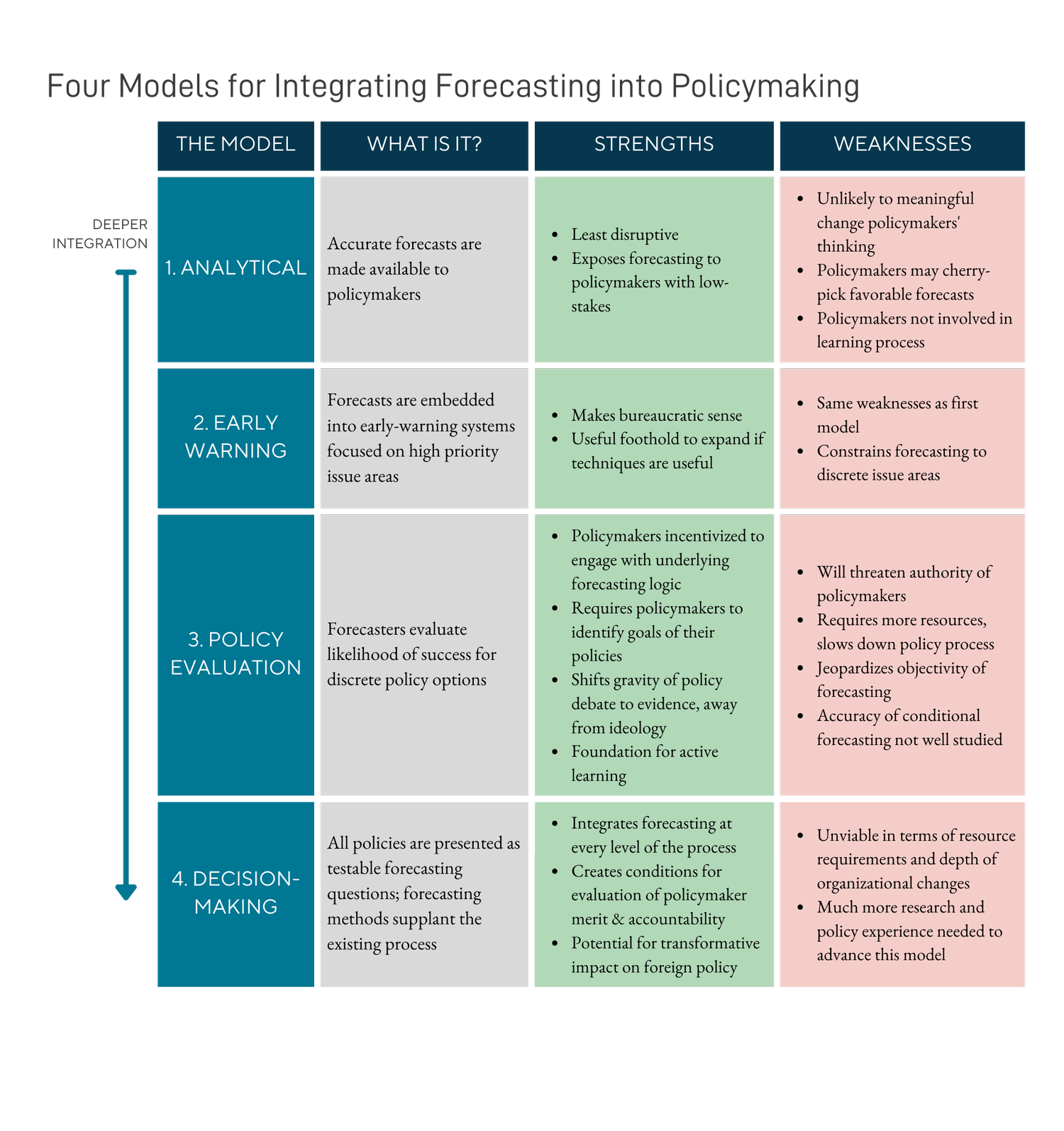
Forecasting in Policymaking: Four Models
by Sophia Brown, DanSpoko
“The first step for testing the promise of forecasting is to develop models for how it might integrate into the actual foreign policy decision-making process. Here we posit four models for how this might be done, and speculate on the strengths and weaknesses of each model.”
Interviews with 97 AI Researchers: Quantitative Analysis
by Maheen Shermohammed, Vael Gates
Last year, Vael Gates interviewed 97 AI researchers about their perceptions on the future of AI, focusing on risks from advanced AI.
Key findings:
- At a 6-month follow-up, 51% reported the interview had a lasting impact on their beliefs, and 15% said that it had caused them to take new actions at work.
- 75% of participants said they thought humanity would achieve something like AGI at some point in the future, though timelines varied considerably.
- Among participants who thought humanity would never develop AGI, the most common reason was they couldn’t see it happening based on current AI progress.
- Participants were split on if the alignment problem argument was valid. Key objections included: problems will be solved via normal course of development, humans have alignment problems too, AI systems will have testing to catch this stuff, we’ll design objective functions in a way to avoid issues, and perfect alignment is not needed.
- Participants were also split on if the instrumental incentives argument is valid. Common disagreements were: the loss function of an AGI wouldn’t be designed so that these problems arise, and there would be oversight (human or AI) to prevent issues.
- 17 participants mentioned they were more concerned by AI misuse than misalignment.
They also found there is more sympathy for AI risk arguments among top researchers and among those who had heard of AI safety / alignment before, and when asked about starting alignment research researchers wanted to know possible directions close to their current research interests and skill sets. Researchers in “Inference” and “Reinforcement Learning” subfields were more interested than those in “Optimization” or “Computer Vision”. These findings were shared in this separate post.
You can explore results interactively on this website. The producer of this research was funded by FTXFF and is now winding operations down as they near the end of funding. They may relaunch and are applying to major funders, but also interested in talking to individual donors - see their post recapping past work and sharing future directions here.