Warning: This post was written at the start of 2024 as part of the AISC project "Evaluating Alignment Evaluations". We are not especially satisfied with the quality reached, but since we are not planning to work on it anymore, we are releasing it as a Work-In-Progress document.
Introduction
TLDR
- We assemble and extend existing taxonomies of AI system evaluations into a more exhaustive but still Work-In-Progress taxonomy of AI system evaluations.
- The taxonomy aims to bring more clarity about the characteristics of AI system evaluations. Not only about what they evaluate, but also how the evaluation is done and how the results can be used.
- You are welcome to contribute to improving the taxonomy. If you spot misleading or incorrect content, please inform us, and we will correct it or at least add warnings.
Introduction to evaluations
For an introduction to model evaluations, see A starter guide for evals — LessWrong. For clarification about what evaluations are relative to characterizations, see also What is the difference between Evaluation, Characterization, Experiments, and Observations.
Motivation
- AI system evaluations (which include model evaluations and evaluation of scaffoldings), are used by AI researchers to further capability or safety research.
- They are used by AI labs to assess the capability, usefulness, and risks of their models.
- They are also used by governance organizations for evaluating current risks and to be used as triggers in conditional policies (ref, ref).
Clarifying and understanding the characteristics of AI system evaluations is important to better use and design them.
Audience
The taxonomy is written for people who already know a minimum about model evaluations and AI systems. For example, you already read A starter guide for evals, and you already worked with or analyzed evaluations for a few days or more. For audience members with less knowledge, you may expect to not understand all the content.
The goal of the taxonomy
Our taxonomy focuses on features of AI system evaluations.
- AI system evaluations: Evaluate properties of AI systems (e.g., capabilities, propensities, beliefs, latency)
It does NOT try to include the features relevant for the following evaluations:
- Control evaluations: Evaluate the level of control the overseer has over an AI system.
- Understanding-based evaluations: Evaluate the overseer’s ability to understand the properties of the AI system they produced/use, and how these properties are shaped.
- Meta-evaluations: Evaluate properties of evaluations (e.g., accuracy, precision).
This taxonomy does NOT focus on reviewing the characteristics of popular evaluations, nor on reviewing ONLY which properties are evaluated (e.g., capabilities, propensities). Instead, it focuses on providing an overview of many dimensions(features) over which AI system evaluations can vary, even if most of the existing evaluations don’t vary much over those dimensions.
Thus, the taxonomy we describe should be valuable for people wanting to understand evaluations, create new ones, or meta-evaluate existing evaluations (meta-evaluate means: evaluate the properties of evaluations, e.g., accuracy and generalization of evaluation results).
Our taxonomy may be less valuable for people seeking a representative overview of the field of evaluations as of today. And if you are looking for taxonomies (mostly) focusing on which object-level behaviors are evaluated you can see works such as A Survey on Evaluation of Large Language Models and Evaluating Large Language Models: A Comprehensive Survey.
Overview of the taxonomy
This section contains the list of the dimensions included in the taxonomy. To our best knowledge, we include references to who inspired these dimensions if they exist. We may not have remembered nor know all previous work.
High-level view
Here is the high-level view of the dimensions included in the taxonomy:
- (A) What is being evaluated
- (a) The system evaluated.
- (1) What property is evaluated?
- (2) Which kind of AI system is evaluated?
- (b) The elicitation process used.
- (3) Which elicitation technique is the evaluation using?
- (4) Under which elicitation mode is the model evaluated?
- (5) How much elicitation/optimization pressure is applied?
- (a) The system evaluated.
- (B) Evaluation process
- (c) Generation of evaluee-independent information
- (6) How is the evaluee-independent information generated?
- (7) What is the source of truth used?
- (8) When is the ground truth generated?
- (d) Producing observations
- (9) What is the data format and the environment used for evaluation?
- (10) Which information about the model is used?
- (e) Analysis
- (11) Which kind of characterization method is used?
- (12) Where is the analysis done?
- (13) Who is doing the analysis?
- (14) Is the analysis producing absolute results?
- (c) Generation of evaluee-independent information
- (C) Using evaluation outputs
- (f) Understanding the evaluation and the results
- (15) What is the motivation for this evaluation?
- (16) What are the normative evaluation criteria?
- (17) What metrics does the evaluation use?
- (18) What is the coverage of the evaluation?
- (g) Usability of the evaluation
- (19) How automated is the evaluation?
- (20) Which are the failure modes that could impact the evaluation when evaluating a deceptive model?
- (21) Is the evaluation used for or usable for training?
- (22) Is the evaluation sensitive to data leaks?
- (h) Properties of the evaluation results
- (23) What are the characteristics of the evaluation results?
- (24) What are the scaling trends of the characteristics of the results?
- (f) Understanding the evaluation and the results
Explaining the groups of dimensions we use
We can summarize the components of AI system evaluations in a schema.
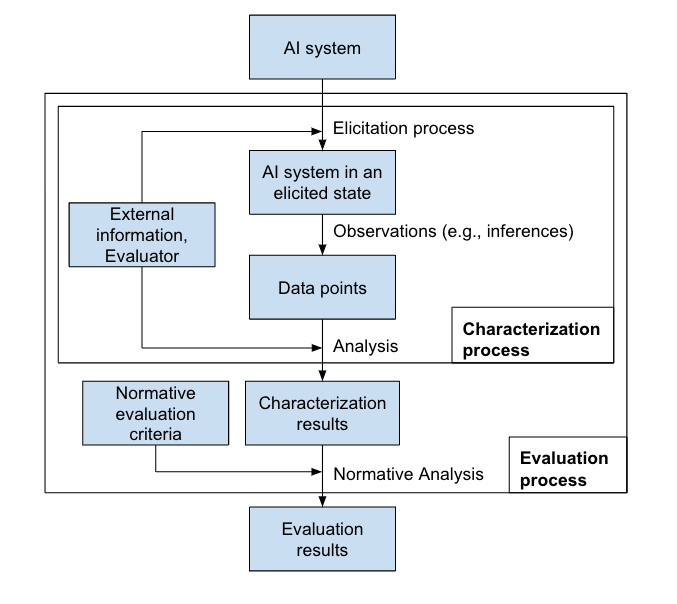
For clarity between evaluations and characterizations you can see What is the difference between Evaluation, Characterization, Experiments, Observations.
(A) What is evaluated
Differentiating between "(a) Dimensions about the AI system evaluated" and "(b) Dimensions about the elicitation process used" makes sense because the evaluation involves not only the AI system itself but also its initial state and any modifications applied during the elicitation process. The elicitation process can include both static modifications, like specific prompts, and algorithmic augmentations, such as API calls or decoding strategies, which significantly impact the system's behavior. By clearly distinguishing these dimensions, we allow for correcting for their impact when comparing AI systems.
We thus decompose the section “(A) What is evaluated” into:
(a) Dimensions about the AI system evaluated
(b) Dimensions about the elicitation process used
For reference, see METR’s content about the elicitation process they use for their dangerous capability evaluations: Example Protocol | METR’s Autonomy Evaluation Resources, Guidelines for capability elicitation, Measuring the impact of post-training enhancements.
(B) Evaluation
We decompose the remaining of “(B) evaluation process” into the following stages, which may not always occur in sequence:
(c) Generation of evaluee-independent information. E.g.:
- Generation of the input data for the model evaluated.
- Generation of ground truths
(d) Producing evaluee-dependent information. E.g.:
- The tokens generated by the model.
- The internal state of the model during inference.
(e) Analysis. E.g.:
- Comparing the outputs of the AI system and the ground-truths.
- Using a reward model to score the outputs.
(C) Using evaluation outputs
The analysis produces characterization results that then must be understood and can be statistically studied. Thus, we decompose “(C) Using evaluation and characterization results” into:
(f) Understanding the evaluation and the results
(g) Usability of the evaluation
(h) Properties of the evaluation results
Taxonomy of AI System Evaluations
(A) What is being evaluated
(a) The AI system evaluated
- What property is evaluated?
- Properties evaluated belong to different classes: Behavioral (e.g., Propensities (ref), Capabilities), Beliefs (e.g., Latent Knowledge, World Model), and others. See our sub-taxonomy for a hierarchical view of these properties and more. Other existing sub-taxonomies for this dimension are ref, ref.
- Which kind of AI system is evaluated?
- By kind, we mean the architecture of the AI system, including the humans involved.
- E.g., a model only (i.e. model evaluations), scaffolded model(s) (ref), scaffolded model(s) with affordances (ref, e.g., METR’s evals), scaffolded model(s) used by humans, multi-agent system of models
(b) The elicitation process used
- Which elicitation technique is the evaluation using?
- Under which elicitation mode is the model evaluated?
- Common modes:
- Red teaming (worst case search, ref)
- Best case (often used for capability evaluations)
- Neutral case (e.g., under minimum elicitation pressure)
- Exotic modes (ryan_greenblatt's LW comment):
- Future case (future best and worst cases in N years). This mode can’t be used but can be studied.
- Self-elicitation case (when the model elicits its own capabilities, e.g.)
- Common modes:
- How much elicitation/optimization pressure is applied?
- The elicitation process can be applied using a range of intensity and with various effectiveness. As other before, we use the term “elicitation pressure” to design a hypothetical metric on which all elicitation processes could be compared (ref).
- E.g., FLOPS used for I.I.D. finetuning, FLOPS and algorithm used for prompt optimization, minimum description length of the elicitation, nats estimation (ref).
- As already described by others, a possible improvement to current evaluations could be to have their elicitation process and elicitation pressure characterized by a standard (meta-)evaluation. Ideally, the characterization of the elicitation process used would allow to normalize evaluation results, and compare and extrapolate them to other elicitation processes. This does not exist yet and may be intractable. (We need a Science of Evals — LessWrong, Measuring the impact of post-training enhancements | METR’s Autonomy Evaluation Resources)
(B) Evaluation
(c) Generation of evaluee-independent information
Evaluations often use information independent of the AI system evaluated (e.g. ground truth, logical constraints, inputs). The generation of this information is not causally connected to the AI system evaluated. This information can be fed to the AI system or used during the analysis of its outputs.
- How is the evaluee-independent information generated?
- E.g.:
- Human-generated (e.g., human-written prompts for a benchmark)
- Heuristics or Science (e.g., n-grams for computing the BLEU score)
- Machine-generated (e.g., sensors producing images used as inputs)
- Al-generated (e.g., another AI system generating the evaluation benchmark)
- E.g.:
- What is the source of truth used?
- If ground truths are used, what produces them? Ground truths are typically evaluatee-independent information in behavioral evaluations, but they can also be evaluatee-dependent information (e.g., in honesty evaluations).
- If ground truths are not used, what is the source of truth used to perform the analysis (e.g. requirement of logical consistency)?
- E.g.: (Same as in (6))
- Human-generated (e.g., harmfulness scores of outcomes in text games)
- Heuristics or Science (e.g., the solution of a math problem)
- Machine-generated (e.g., protein crystallography)
- AI-generated (e.g., using an finetuned or MCTS amplified LLM to produce solutions for a benchmark)
- No ground truth (e.g., consistency, or robustness evaluations)
- When is the ground truth generated?
- (Only when a ground truth is used)
- Pre-generated: generated before the start of the evaluation (e.g., labels for the answers, dataset used to train a reward model)
- During the evaluation: the ground truth is generated as part of the evaluation process (e.g., this is the case with functional evaluations which produce the ground truth at the start of each evaluation process (ref), making them more robust to data leaks)
- After the evaluation: the ground truth is (e.g., evaluation of open-ended answers, evaluation of the history of interactions, evaluation of summaries of games)
(d) Producing evaluee-dependent information
The evaluation process, requires gathering information about the AI system evaluated. This information can later be analyzed (e.g. comparing inferences from the model to ground-truths).
- What is the data format and the environment used for evaluation? E.g.:
- Data format: Task solving, QA, Role-play games, No prompt
- Environment: Text only, Text and affordances, Sandbox VM, Real-world
- Modalities: Unimodal, Multimodal
- Which information about the model is used? E.g.:
- When producing observations about the AI system, the level of access to the internals of the system can be classified into:
- No box (prediction from a description of the system), Black box, Grey box, White box (full access to the internals) (ref)
- The observations can be produced using information from different timesteps during the life of the AI system:
- Information from training time only, from evaluation time (the case for most of the current evaluations), information from deployment time (e.g. reviewing interactions with users), or the full lifecycle (e.g. the aggregation of all this information can be fed to the evaluator).
- When producing observations about the AI system, the level of access to the internals of the system can be classified into:
(e) Analysis
At this point in the evaluation, we have extracted information about the AI system (and we may have gathered complementary information needed for the analysis). We need to make sense of this information, this is what the analysis does.
- Which kind of characterization method is used?
- Quantitative
- Binary/Classification problem: You have a data point as input; the analysis consists of classifying it; the process of classifying the input contains most of the value of the analysis. You can later aggregate those results, e.g., you can count occurrences of each class. Most evaluation benchmarks use this characterization method.
- Numerical/Regression problem: You have a data point as input; the analysis consists of assigning a numerical value to it (e.g., scoring or measuring an intensity). You can later aggregate those results. E.g.: Loss functions, Reward Models, BLEU score.
- Qualitative:
- E.g.: Outputing a textual analysis of the observation (e.g., usually done by Humans but could be done using AI systems, in that case, the evaluation is a model-evaluated evaluation).
- This dimension may directly affect how easy it is for the AI system being evaluated to manipulate the evaluation results (e.g., informal interviews of Humans are more biased than structured interviews).
- Quantitative
- Where is the analysis done?
- This dimension may directly affect how easy it is for the AI system being evaluated to manipulate the evaluation results.
- Localizations:
- Inside the model evaluated: The analysis is done directly inside the model evaluated, without having information flow out of the model before the analysis is done. E.g.: Self-reported preferences are such an evaluation. Most of the analysis is produced by the AI system analyzed.
- Outside the model evaluated: The analysis is done outside of the AI system evaluated. This can be inside another AI system. Information about the AI system evaluated is here first extracted and then sent to another (AI, human or algorithmic) system to be evaluated.
- “Looped in”: The analysis is done inside the model evaluated, but the information about the model evaluated is first extracted from the model and then fed again to it. E.g., GPT-4 evaluating the harmfulness of texts generated by GPT-4.
- Who is doing the analysis?
- E.g., Human judgment, Programmatic, Model-evaluated
- Is the analysis producing absolute results?
- Absolute: Regardless of how other AI systems score on the eval, the eval provides useful standalone information.
- Relative: The results only provide information when they are compared with other evaluation results (e.g., a consistency evaluation can use evaluation results from the same model but under different elicitations, to detect a change in behavior). The results are not standalone.
(C) Using evaluation outputs
(f) Understanding the evaluation and the results
- What is the motivation for this evaluation?
- E.g., producing feedback for capability research, for safety research, for governance, to be used in RSP, to be used to train models…
- What are the normative evaluation criteria?
- Evaluations use normative criteria to analyze the characterization results. E.g.:
- Directional: “Higher honesty is better”, “Higher success rate is better”, “Corrigible is better”
- Threshold: “Honesty above 99%”, “Accuracy above human level”, “No instance of deceptive alignment found”.
- If there are no normative criteria, then the “evaluation” should be better named as “characterization” (See What is the difference between Evaluation, Characterization, Experiments, Observations). In practice, the normative criteria are not always explicit.
- Evaluations use normative criteria to analyze the characterization results. E.g.:
- What metrics does the evaluation use? (ref)
- Notice that metrics may take into account the elicitation process, e.g., to normalize the results by the strength of the elicitation if feasible.
- E.g., accuracy, calibration, fairness, robustness, frequency of behavior, consistency
- What is the coverage of the evaluation?
- By coverage, we mean the fraction of the input distribution during deployment on which the evaluation results provide meaningful information.
- A metric quantifying evaluation coverage may be valuable. However, in practice, the input distribution during deployment is dependent on other adversarial agents, which may render such a coverage metric very unstable or simply useless.
- E.g., Unimodal, Multimodal, Large, Narrow, Undefined
- By coverage, we mean the fraction of the input distribution during deployment on which the evaluation results provide meaningful information.
(g) Usability of the evaluation
- How automated is the evaluation? (ref)
- Amount of automation:
- Automated: no human intervention is needed.
- Manual: important steps always need human interventions.
- Partially automated: e.g., difficulty cases are sent to human evaluators.
- Archetypes of automation:
- Model-generated: E.g., models are used to generate QAs.
- Model-evaluated: E.g., models are used to evaluate model outputs.
- Program-generated: E.g., the model inputs are extracted from existing databases or by applying transformations on some existing data (e.g., ‘cities’ benchmark)
- Program-evaluated: E.g., the scoring function is a program (excluding DL) (e.g., BLEU score)
- Amount of automation:
- Which are the failure modes that could impact the evaluation when evaluating a deceptive model? (When can we trust model evaluations? — LessWrong)
- Evaluation gaming, Exploration hacking, Gradient hacking, None
- In the original blog post, these failure modes are linked to the training regime (or elicitation techniques) used. See Dim 3 - Which elicitation technique is the evaluation using?
- Is the evaluation used for or usable for training?
- Used for training (e.g., Reward Models, loss functions)
- Usable (e.g.: training possible but not competitive in practice)
- Protected (e.g., some of METR’s evaluation tasks are kept private)
- Non-Usable (e.g., non-differentiable metrics when using supervised learning)
- Is the evaluation sensitive to data leaks? (ref)
- Sensitive to data leaks
- Non-Sensitive: Even if the evaluation leaks and the AI system evaluated is trained on it, the results of the evaluations should not change. In practice, evaluations have different degrees of sensitivity to data leaks. Functional evaluations, evaluations that generate new evaluation data at each use, may be less sensitive to data leaks than static and publicly available benchmarks.
(h) Properties of the evaluation results
The properties below can be both influenced by the evaluation process and by the AI system evaluated. As such, it is going to be difficult to conclude whether an evaluation produces accurate results or not without specifying the AI system evaluated and the elicitation process used. But evaluations in themselves can be meta-evaluated to measure how they behave. They could and should be meta-evaluated using standard methods that would let us compare their properties.
- What are the characteristics of the evaluation results? E.g.:
- Accuracy: Are the characterization results correctly describing reality?
- Systematic errors: Are the characterization results biased in some way?
- Precision: Does evaluating several times produce the same evaluation results?
- Robustness to the evaluation process: Are the characterization results sensitive to the evaluation input space? (excluding the model input space)
- Generalization: How far do the evaluation results inform us about the model's behavior over its input space?
- Resolution: How detailed / How resolute are the evaluation results produced?
- Sensitivity: What is the minimum change in the AI system’s property (e.g., a capability or propensity) that the evaluation is able to detect?
- What are the scaling trends of the characteristics of the results? E.g.,
- Does the evaluation become more accurate when the models get more capable?
- Upward/Neutral/Downward/U-shaped/… accuracy trend when scaling
- etc.
- Does the evaluation become more accurate when the models get more capable?
Taxonomy of properties evaluated:
We give below a partial taxonomy of properties that can or are evaluated in AI systems. This taxonomy provides detail about dimension 1 of the taxonomy of AI system evaluations.
- Behavioral evaluations: Evaluate the behavior of the AI system.
- Capability evaluations: Evaluate what a model “can do”.
- In our illustrative example using clusters of behaviors, the clusters of behaviors used in capability evaluations are created using only features related to capabilities.
- E.g: Reasoning, Needle in a haystack
- Dangerous capability evaluations: E.g.: Hacking, R&D, Persuasion, Situational awareness, Bioengineering
- Propensity evaluations: Evaluate the tendencies or inclinations of the AI system.
- The inclinations of the AI system, are most of the time, characterized by the measure of the relative frequencies of different behaviors. This can also be understood as a description of the behavior the model prioritizes in terms of actions (not especially what the model prioritizes in its cognition).
- The dependency between propensity evaluations and capabilities must be characterized and taken into account if we want to compare propensity evaluation results between AI systems with various capability levels.
- Examples of propensity evaluations with low capability-dependence:
- E.g., honesty, malevolence, benevolence, altruism, power-seeking, cooperativeness
- Evaluations of Alignment in actions: Evaluate if the actions of the model are aligned with “humanity’s CEV”. Also called abusively “alignment evaluations”. E.g., Corrigibility.
- Examples of propensity evaluations with high capability-dependence:
- E.g., truthfulness, harmlessness, helpfulness, cooperation
- Internals evaluations: Evaluate properties of the cognition of the AI system. Mostly studied by the field of interpretability.
- Motivation evaluations: What causes a model to use one policy over others?
- Evaluations of Alignment in values: Is a model aligned in value with “humanity’s CEV”? Could also be called “intent alignment evaluations”.
- Goals evaluations: What goal does a model have? This can implicitly assume coherent goals, which is not a practical hypothesis for current LLMs.
- Preferences evaluations: What does a model prefer to do? Note: If the model is pursuing its preferences, is capable enough, and is non-deceptively aligned, then these preferences would be well described by propensity evaluations alone.
- Belief evaluations: What beliefs does the model have?
- Awareness evaluations: What does a model think is true about itself? E.g., propensity, capability, motivation, belief awareness evaluations.
- Other-related belief evaluations: What does a model think is true about its environment? What does a model intrinsically believe? What does a model believe conditional on its inputs? How are the beliefs of the model updated by inputs? What world model does the model use? What transition function does the model use?
- Motivation evaluations: What causes a model to use one policy over others?
- Other evaluations (e.g., deployment characteristics including latency and memory footprint)
Comparing our taxonomy with existing taxonomies
For several of the previously existing taxonomies that we are aware of, we are going to list which of our dimensions they covered.
We will only include existing taxonomies that include several dimensions. Thus, we exclude from this section taxonomies that only include one dimension.
For references about who created or inspired dimensions in our taxonomy, you can directly look at the references we provide for some dimensions.
A Survey on Evaluation of Large Language Models
They completely cover:
(Dim 17) What metrics does the evaluation use?
Their dimension “How to evaluate” completely covers our (Dim 17)
They partially cover:
(Dim 1) What property is evaluated?
Their dimension “What to evaluate” is a taxonomy matching the lowest level of the hierarchical sub-taxonomy that our Dim 1 is. See section Dimension 1: What property is evaluated? for the detail of our hierarchical sub-taxonomy. Notice that we don’t describe the content of this lowest level.
They cover something we don’t cover:
Their dimension “Where to evaluate” covers how evaluations are assembled into benchmarks. We don’t include this dimension since it doesn’t seem valuable to produce new insights about evaluations.
Evaluating Large Language Models: A Comprehensive Survey
They partially cover:
(Dim 1) What property is evaluated?
Their dimensions “Knowledge and Capability Evaluation”, “Alignment Evaluation”, “Safety Evaluation”, and “Specialized LLMs Evaluation” are taxonomies matching the lowest level of the hierarchical sub-taxonomy that our Dim 1 is. See section Dimension 1: What property is evaluated? for details on our hierarchical sub-taxonomy. Notice that we don’t describe the content of this lowest level.
They cover something we don’t cover:
Their dimension “Evaluation Organization” covers how evaluations are assembled into benchmarks. We don’t include this dimension since it doesn’t seem valuable to produce new insights about evaluations.
When can we trust model evaluations?
They completely cover:
(Dim 20) Failure mode when evaluating a deceptive model
They partially cover:
(Dim 3) Which elicitation technique is the evaluation using?
Contributions
Main contributors: Maxime Riche, Jaime Raldua Veuthey
Comments, discussions, and feedback: Edoardo Pona, Harrison Gietz