Rethink Priorities' Worldview Investigations Team is sharing research agendas that provide overviews of some key research areas as well as projects in those areas that we would be keen to pursue. This is the second of three such agendas to be posted in November 2024. It describes our view of the digital welfare research landscape and the kinds of questions that we’re interested in taking up.
Our team is currently working on a model of the probabilities of consciousness in contemporary AI systems that touches on a variety of the questions posed here. We plan to release research related to the issues raised by that project as we go. We're interested in other projects related to the questions below, and we have some specific ideas about what we'd like to work on, but this is a fast-moving space and so we would recommend that prospective donors reach out directly to discuss what might make the most sense for us to focus on.
Introduction
The rapid development of deep learning models over the past decade has demonstrated the potential of artificial intelligence. Optimistic projections suggest that we may see generalist systems matching human intelligence in the coming years.
AI systems will spur novel ethical questions relating to fairness, respect, and our obligations to other humans. It is also plausible that some near-future systems will deserve moral consideration for their own sakes. If future AI systems could achieve human-level intelligence and display human modes of thought, it is quite plausible that they will also be capable of the kind of states that comprise our welfare.
Whether future AI systems have welfare will surely be controversial. While there are many theories in philosophy and cognitive science that bear on this question, those theories have been formulated with a focus on humans and other animals and have not undergone significant scrutiny in the context of artificial systems. Further research is required to understand how to apply existing work to this new domain.
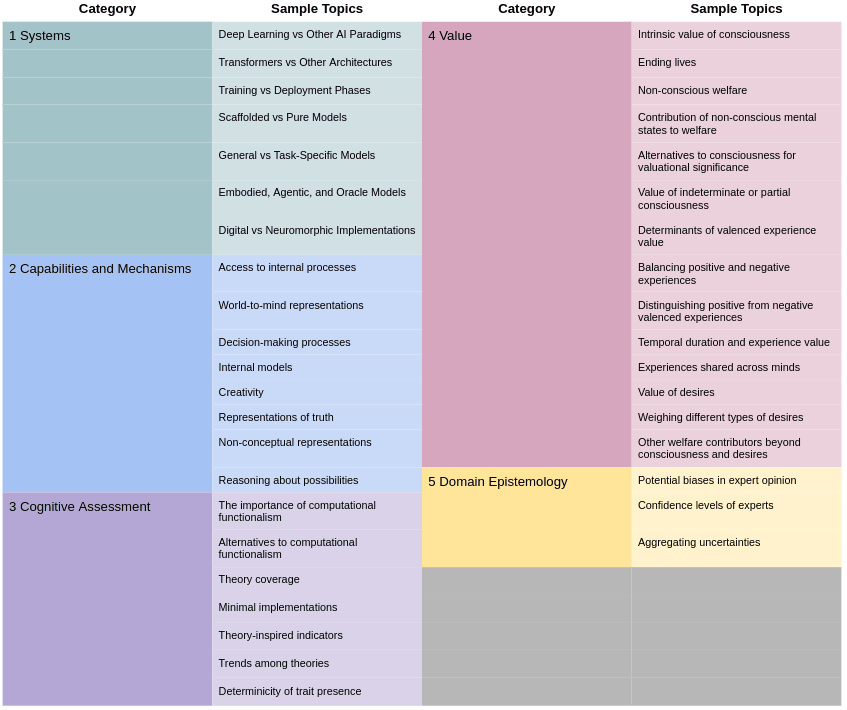
This research agenda presents a variety of questions relevant to prioritizing and planning for digital minds policy. It does not broach specific policy proposals or strategic frameworks, but focuses on the issues underlying AI welfare and the scale of potential problems. The questions it encompasses are divided into five categories:
- Questions of Systems, which concern which kinds of AI systems most warrant our attention. These questions relate to the current AI landscape and potential future developments.
- Questions of Capabilities and Mechanisms, which consider the characteristics of AI systems that are relevant to welfare assessments. These questions are empirical and technical; they focus on understanding the way the systems operate so as to provide sufficient material to decide which of our cognitive concepts apply to them.
- Questions of Cognitive Assessment, which concern how to apply the familiar concepts that populate our moral views to novel AI systems in light of their architectures and behaviors. These questions are largely philosophical and provide a conceptual bridge between the (relatively) directly accessible capabilities and mechanisms and our moral theories.
- Questions of Value, which concern what kinds of features we should be concerned about and how we should weigh them. These questions are philosophical, and largely deal with incorporating the novelties of AI systems into our existing moral frameworks.
- Questions of Domain Epistemology, which concern how we should understand the current state of research into the preceding question categories. These questions mix empirical and philosophical considerations. They provide context and influence our overall level of confidence in the answers we derive from them.
The following chart summarizes some of the issues belonging to each category.
This approach is notable in several respects.
First, it anchors the philosophical questions in empirical realities. It is important that the more general questions of the nature of our obligations to digital minds be informed by the details of the systems we will actually create and that we consider the philosophical issues through the lens of actual technologies. The first and second categories of questions prompt us to dive into the technical details of real systems and to consider how those details may plausibly change in the coming decades. The third and fourth categories shape and guide our inquiries into the first and second. It is tempting to approach these questions separately, as they require very different backgrounds and skill sets, but considering them together keeps our focus on those aspects of each question that are practically meaningful.
Second, it foregrounds uncertainties: uncertainties about which theories are right, who to trust and how much to trust them, and what the future holds. It aims at providing research that can assist in practical consensus-driven decision making.
We hope that research into these questions will help make a difference to the treatment of AIs. We think that standards adopted by labs should reflect the considered views of the field, and that any current consensus needs to be more carefully articulated and examined before they can implement appropriate safeguards. We think that an understanding of the possible trajectories, and what those trajectories say about digital welfare, will matter for the prioritization of money and researcher attention. We hope that research in this vein will influence funders and researchers in this field, and through them, AI labs. Down the road, we hope that this research can provide a foundation for policy on building and relating to digital minds.
1. Questions of Systems
Perhaps we should be particularly concerned about the treatment of full-fledged AI persons in social applications who are deliberately tormented by users for personal gratification. Perhaps we should be more concerned about the inexpressible feelings produced by simple algorithms (e.g., personal movie rating predictions) that are run on a vast scale in server farms. Perhaps the worrisome scenarios that are actually most likely to come to pass look very different from these.
Very different kinds of concerns fall under the scope of digital welfare. Concerns about full-fledged AI persons might invite a research focus on more complex forms of cognition and on knowing when an artificial person’s behavior reflects what is really going on inside them. It might warrant deeper consideration into when AI testimony is trustworthy or whether a single intelligence can be split across different models running on different servers through separate API calls. Concerns about simple algorithms would invite questions about the minimum implementations of consciousness-relevant architectures, the moral significance of very temporary minds, and the relative value of inhuman modes of life.
Artificial intelligence is in a phase of growth and exploration. The current pace of AI development came as something of a surprise. So did the dominance of language models. We can and should make guesses about the coming trends in AI, but we should also expect to be surprised now and then and for our predictions to err in important ways. With the increasing investment and interest in AI, we will see exploration with a variety of approaches. Some may bear fruit.
Impactful AI welfare research must be sensitive to the space of practical possibilities, to the scale of different possible risks, and to the diversity of issues that are specific to each context. The first set of research questions relate to mapping this space.
How researchers should allocate their attention will depend both on the practical uses of AI and the plausibility of welfare concerns for different systems.
Significant system divisions
Some major divisions of systems that might introduce different welfare considerations include:
Deep Learning Models vs Other AI Paradigms
Deep learning models, which use neural networks many layers deep, have demonstrated the greatest achievements in AI to date. They are also a fairly new focus for intensive AI research, and it is possible that future AI successes will be based on novel paradigms. The potential for new paradigms seems particularly promising as attention floods into the field and as AI advances help us to better search the space of alternative techniques. Perhaps the influx of interest, investments, and researchers assisted with ever-more powerful tools, will find ways to leverage swarm computing, evolutionary algorithms, good old fashioned AI, or something genuinely new in powerful and efficient ways.
Deep learning neural networks bear a superficial resemblance with the mechanisms underlying human cognition. They operate on levels of activation across nodes. They permit surprisingly flexible forms of intelligence. If these capacities bear on the plausibility of AI welfare, then we should perhaps be most concerned about deep learning models. On the other hand, if we think that human analogies of this sort are irrelevant, then we should perhaps be equally concerned about potential other AI paradigms.
Transformers vs Other Deep Learning Models
The transformer architecture has been employed to great success in large language models to perform text continuation via next token prediction. This has produced a style of cognition, based around mimicking human language, that was until recently unanticipated. Much of the work on the welfare of contemporary digital minds is focused on assessing transformer architectures for possible morally-relevant features.
Alternative neural network structures (recursive neural networks, state space models) and training regimes (training on video data, adversarial training) could lead to very different cognitive styles. If these alternatives come to dominate, then research into transformer cognition might become irrelevant and the conceptual tools or techniques we created to understand them superfluous. Should we expect transformer architectures to continue to flourish, or are they a passing phase? Do likely successors suggest different research focuses?
Training Phases vs Deployment Phases
Modern deep learning models undergo extensive training phases in which models initialized with noise are continually adjusted to produce ever better results. While training involves running the models in similar ways to the ways they are run in deployment, the training phase of models does also differ in some ways that may be important.
During training, models will typically start out incoherent and gradually migrate toward developed modes of cognition. If we think that the final models are conscious, it is unclear what to make of the intermediate stages. Furthermore, there are substantial implementational differences in the way that training is carried out as compared to inference. For instance, training base LLM models involves skipping text sampling and making changes to parameters to improve prediction accuracy.
As a result of such differences, there may be special moral considerations that occur only in specific stages of training (e.g., early training, during RLHF augmentation, fine-tuning, etc.). The extent to which we expect these differences to matter will affect which policies we think are most important, and where we think research into digital minds is most helpful. In order to assess the importance of training and inference, it is important to understand their relative scales and the potential issues raised in each.
Scaffolded vs Pure Models
LLMs are powerful on their own, but can do much more when utilized within a program that can organize and structure their inputs and outputs. Such scaffolded systems include language agents, which plan and organize actions across multiple queries and maintain separate stores of relevant information.
Much of the recent focus on AI welfare has been models themselves, not scaffolded systems, but there may be different reasons for concern regarding scaffolded systems. If AI persons are likely to use scaffolding, then we may need to consider the particular issues that arise in that context.
Scaffolded systems may utilize very different sorts of models for different purposes and do important integrational work in a traditional programming paradigm. How such hybrid systems compare is important to assessing their welfare status.
Avoiding abuses may require very different sorts of AI lab policies: the entirety of scaffolded systems may not belong to any single lab, many of their details may be secret, and their structures may continue to evolve years after training in their models is completed.
General vs Task-Specific Models
Some AI systems are built to perform highly specific tasks, others to reason generally about various issues. It is likely that we can more easily recognize welfare issues among general models as opposed to models that are optimized to specific ends. Such models may have a wider range of capacities that are related to welfare, making it easier to get relevant evidence about their experiences. They may, for instance, be able to give testimony about their own welfare or make complex decisions in ways that convey nuance.
Optimized task-specific models might turn out to be far more numerous. Given a significantly lower overall analogy with human minds, they may require far closer examination with regard to specific theories of welfare to generate any conclusions.
Task-specific models are also probably less likely to have welfare overall—it is hard to see how simple models might have welfare but large general models do not. Assuming that task-specific models are less likely to have welfare but be far more numerous, we need to consider whether the numerosity makes up for reasonable welfare skepticism. In some ways, the question of general vs task-specific models may replicate the challenges that philanthropists face trading off human and invertebrate welfare.
Embodied, Agentic, and Oracle Models
Some AIs are built to pursue goals and navigate the world. Others are built just to answer queries. It is plausible we can more easily recognize welfare issues among embodied agentic models than among models that only respond to queries, as we are generally far more primed to recognize factors that go into decision-making than to welfare among pure oracles. However, it isn’t obvious that oracle AIs would lack welfare entirely, and may utilize forms of decision-making to balance different goals in giving answers.
Agentic AIs might have special claims to welfare that aren’t available to oracles on account of their goals potentially providing them with motivations and desires. Insofar as those things matter, agents stand to have a better claim to welfare. Agency also provides better sources of evidence about what will actually benefit a system. Agents can pursue recognizable ends in ways that make their agency manifest.
Embodiment is another important distinction that many consciousness experts treat as potentially relevant. AI models that lack senses or control over physical bodies may turn out to be quite numerous and may share many cognitive capacities we normally regard as morally relevant. They will also be unlike us in a number of ways that some consciousness researchers have thought to be important. Whether unembodied AIs have less of a claim to welfare may significantly influence the concern we have over future systems.
Digital vs Neuromorphic Implementation
Current AI models are run on standard processors within a von Neumann paradigm. Future models might have specialized processors with hardwired components or that utilize neuromorphic paradigms. Models run on digital computers may compare with human and animal cognition in only a more abstract way compared with models run in neuromorphic hardware. The extent to which we expect computer hardware to change bears on how important we think this distinction is.
Sample questions
Questions of systems would be informed by these (and similar) divisions. They include:
- What future scenarios should we expect to be most likely to come about? What kinds of AI systems will they most likely involve? Which systems will exist in the highest numbers in the coming decades?
- Which kinds of AI systems have the least/greatest prima facie claim to welfare? Which kinds of systems are likely to possess the widest welfare capacity ranges? What kinds of systems clearly raise no welfare concerns at all?
- To what extent should we expect that considerations relevant to contemporary systems will also bear on near-future systems? What research will have a lasting impact even as technology changes?
These questions are challenging, and we will surely not be able to fully answer them. Progress may still help us to prioritize limited resources in the years to come, and will hopefully allow us to pivot more effectively as the trajectory of AI becomes clearer.
2. Questions of Capabilities and Mechanisms
Similar behaviors may be produced by radically different faculties, so it is easy to read too much into patterns that remind us of human beings. There is a danger of misattributing welfare to AI on the basis of misleading indicators. In the 1960s, ELIZA’s cleverly designed verbal manipulations convinced some to regard it as more impressive than it was. Perhaps today’s public is making a similar mistake with respect to a much more sophisticated ChatGPT.
Recent progress in AI has produced recognizably human-like demonstrations of creativity and reasoning. Some of these behaviors are taken as evidence of welfare capacities in humans and other animals. Evaluating the depth and breadth of such behaviors will have a place in future assessments of AI welfare. However, the relevance of such behaviors depends on the evidence they provide about underlying cognitive faculties. In assessing familiar behaviors in new contexts, we must carefully consider what they suggest about internal structures.
A sober approach to AI welfare based on behavioral indicators ought to be sensitive to each model’s full range of capabilities. This will include better understanding not just the model’s achievements but also its limitations. It will also require peering beneath the hood to see whether the AI’s cognitive mechanisms are taking illicit shortcuts or have found an entirely novel path.
It is notoriously difficult to understand how deep learning models work. Their basic software architecture is clear enough. Within that software architecture, the training regime creates internal conceptual or logical structures that are stored in the parameter settings. The nature and purpose of those internal structures are only slowly coming into focus. Though some relevant research exists, it is not aimed at assessing welfare issues. The important upshots of this research need to be extracted. It is important that those concerned with AI welfare understand and help guide this research to deliver information about capacities necessary for assessing systems.
Our focus is on capabilities and mechanisms that bear on our application of psychological concepts, such as (among others):
- Representation
- Thought
- Belief
- Desire
- Intention
- Attention
- Introspection
- Metacognition
- Perspective Integration
- Memory
- Theory of Mind
- Mood
- Personality
Sample questions
Some relevant issues include:
Do LLMs have access to their own internal processes? Can they tell what is going on inside of themselves?
Introspection is an important cognitive ability that is widely believed to be closely tied to consciousness. Consciousness allows us to register our internal states, and through introspecting our conscious experiences we reliably acquire information about our mental processes. The ability to assess internal mental phenomena is one that might be easily assessed in testing. Detecting the ability to express information about internal states might indicate that LLMs have some consciousness-relevant faculties. Even if we are uncertain about connections between consciousness and introspection, introspection may be tied to a sense of self, or to self-endorsed desires in ways that are important for welfare.
Do LLMs or other deep learning models have goals? Are their actions influenced by representations with a world-to-mind direction of fit?
Agency requires the ability to form and pursue ends. Plausibly, having an end requires having some internal representation that is used by decision-making processes to direct our actions toward bringing it about. Do any deep learning models have goal representations with a mind-to-world direction of fit? If they do not, they may be able to act in ways that appear agentic but are not morally relevant. The extent to which it is harmful to them to frustrate them may depend on the nature of the underlying decision-making mechanisms.
For models with goals, do they have decision-making processes? Do they weigh different considerations for alternative options and contrast them with each other?
Agency plausibly requires the ability to choose between different courses of action in light of one’s ends. If deep learning models have ends, do those ends shape their behavior by way of something that looks like decision making? Do they entertain and evaluate separate possible courses of action?
To what extent do AIs (LLMs or other deep learning models) use internal models for generating predictions? Are there many such models within a single system, and if so, do they have a heterogeneous structure? What aspects of training encourage the formation of such models?
Some modern AI models are known to use internal structures to model parts of the world in order to make predictions. These internal representations might be unusual solutions to specific problems, or they may occur very widely. Whether these internal representations are prevalent should influence how we interpret AI reasoning. If internal representations play a role in shaping transformer LLM responses, for instance, we may be more inclined to treat those systems as having welfare-relevant beliefs and desires. Such models might also be useful for assessing welfare states directly.
What are the limitations on deep learning model creativity?
Some experts have claimed that LLMs are effectively stochastic parrots, that they can repeat abstracted patterns they’ve seen before but cannot understand text in the same way that humans do. This is suggestive of a lookup-table approach to intelligence that has long been thought to rule out welfare.
The authenticity of deep learning models’ apparent creativity may provide important context to welfare assessments. If some models are genuinely creative, it will be harder to attribute their successes to misleading shortcut heuristics. If they display unexpected gaps in creativity, it may be less reasonable to explain their behavior with familiar human psychological concepts.
Do LLMs have special representations for the true relationships between concepts as opposed to false but widely believed relationships?
In order to predict textual continuations, transformer LLMs need to track a huge number of relationships between concepts, not just connections that reflect truths about the world, but also relationships that are believed by different groups. During training, such models are penalized for providing inaccurate predictions about text continuations, which include texts with false statements. If LLMs have true beliefs about the world, we might expect that they represent relevant conceptual connections in a different way.
Are there any important differences between associations that are part of the model’s best understanding of the world and associations that it needs to remember merely to predict what is believed by certain groups? Such differences may be important to assessing whether LLMs have genuine beliefs, or whether they employ distinct kinds of epistemic states.
How do LLM or other deep learning model representations map onto the conceptual/non-conceptual distinction from the philosophy of mind?
Some theories of consciousness have invoked the concept between coarse-grained ‘conceptual’ representations and fine-grained ‘non-conceptual’ representations. The latter are involved in perceptual experiences in animals. Does the distinction make sense in the context of language models? If so, do AI representations fall squarely on the conceptual side or do they have non-conceptual representations as well? Are there architectures that might encourage non-conceptual representations?
To what extent can LLMs reason about possibilities in order to choose text continuations? Are the limits of that reasoning constrained to the structure of outputted text?
LLMs are known to be bad at planning ahead. In completing tasks involving planning, LLMs benefit from being able to construct plans through chain-of-thought reasoning. This inability to plan may be tied to their design for next-token prediction: they aren’t trained to formulate whole ideas at the start. Nevertheless, they may need to plan what they will say long before they say it in order to accurately predict certain kinds of continuations. Satisfying that need might require reasoning about possibilities divorced from the idea currently being expressed. Is there any good evidence that LLMs are currently able to engage in reasoning about possible continuations, or reason to think that novel training regimes may elicit that skill in the future? Without being able to reflect on different full possibilities, we may be less inclined to attribute them human-like decision-making faculties. Without such faculties, it may be less plausible that they have welfare-relevant desires. If they do have such faculties, it may also be more difficult to assess them for welfare, as they will contain complex thoughts not outputted as text.
3. Questions of Cognitive Assessment
It is no trivial thing to assess an AI system for specific capabilities, let alone the internal mechanisms that generate them. It is yet another challenge to tell, given some detailed description of what AI systems do and how they do it, whether our human psychological concepts apply to them. A system may represent damaging stimuli in an introspectable way and respond aversively, but does it feel pain? A system may have representations of goal-states that shape its behavior, but does it desire those things? A system may have representations of its internal states, but is it self-aware?
Normative theories are generally formulated with concepts familiar from folk psychology. We care about whether AIs suffer, whether they feel stressed, whether they have their desires frustrated, and so on. These familiar concepts may be translated into specific neurological or computational requirements in many different ways, and we seldom have a precise interpretation in mind even as we use them. People can agree about claims made with these concepts while disagreeing with what it takes to satisfy them. We will therefore likely agree about suitably abstract conditions of harm to AI systems. It will still be controversial when and where those conditions are met.
Important traits
Many of the most difficult questions about AI welfare relate to the applicability of normatively significant concepts. The following lists some of the most salient questions for researchers to consider:
- Do AI models have phenomenally conscious experiences?
- Do AI models have positively or negatively valenced phenomenal experiences?
- Do AIs have beliefs, desires, or other propositional attitudes?
- Do AIs have moods or emotions?
Experts have developed theories of these traits, but the theories were generally intended first and foremost to apply to the human case. Even if we accept some existing theory, we are left with the task of specifying how to apply it to artificial systems that differ from humans in a wide variety of ways. Some considerations, like biological constitution, can be taken for granted in humans but may make an important difference to how we view AIs. Furthermore, in addition to assessing which theories are most promising and what they say in this novel context, it may be open to question whether any known theory is right and how much confidence we should have in them. If we don’t accept any existing view, there may be a way to directly assess systems on the basis of common sense or metatheoretical considerations.
Sample questions
These complications are elaborated in the following questions. For each relevant trait:
Is the case for AI possessing this trait primarily dependent on computational functionalism?
Computational functionalism, which holds that mental states can be analyzed in terms of which algorithms are implemented, provides the clearest grounds for attributing mental states to AI, but it is itself controversial. If it is false, discovering the same algorithms in human brains and in AI may not tell us much about the AI. Does the case for the trait depend primarily on the credibility of that theory, or is there some other explanation of how the AI might possess the trait that goes beyond algorithmic analogies?
How plausible is computational functionalism for this trait, as opposed to other nearby theories (e.g., non-computationalist functionalism), or other kinds of metaphysical theories altogether?
Much discussion of specific traits does not wade into the details of computationalist functionalism. For instance, computationalist functionalism says that algorithmic structure is all that is required for consciousness, even if that structure is merely virtual and does not line up at all with the underlying mechanisms. How seriously should we regard computationalist versions of theories that might be developed in several different ways? Should we expect that biology may play a critical role beyond providing a medium in which algorithms can be implemented?
What theories of this trait are taken seriously by experts? Which are most plausible?
Many theories have been formulated to better understand mental states in human beings. Often, these theories can be given a pure computational functionalist interpretation. Alternatively, they can be conceived of as highlighting a computational core of a hybrid complex, or as identifying an important feature that coincides with the trait in humans but isn’t definitive of it. The primary advocates of each theory may not intend for their theories to be taken in the ambitious pure vein or they may be silent on how they conceive those theories. Even for theories that are intended to be read in a computational functionalist spirit, there remains the possibility that they are not intended as complete theories, but as partial theories applicable to human beings. Which theories make the most sense within a computational functionalist framework? Which theories are plausibly read with enough substance to be applied to AI models without significant elaboration?
How well is the space of viable theories of this trait covered by existing proposals? If we just evaluate systems according to the specifics of existing proposals, are we likely to be missing out on a number of other equally viable theories?
The existing theories supported by substantial bodies of work differ greatly from one another. This is consistent with our having identified all viable paradigms and found the best instance of each. It is also consistent with a very patchy process that has failed to identify many viable contenders. If there are many viable theories that have not yet been considered, showing only that all existing theories make a prediction may be misleading. To what extent does the stark diversity of theories suggest that we don’t have the space of viable contenders well-covered? To what extent should we therefore leave credence that existing theories may give a misleading impression about the probability of AIs possessing this trait?
What should we think of minimal implementations of each theory’s proposed criteria? How do we judge when we have substantial enough implementation to truly be conscious?
Precise theories of traits typically have applications to systems that are very simple and intuitively do not possess the trait. It is easy to satisfy the letter of the theory. It is plausible that such theories should be elaborated to be less easily satisfiable, but it isn’t generally clear how to go about this. To what extent should we be willing to apply theories to very simple systems that meet the specific requirements of the theory and do little else? Assuming we’re not willing to apply the theories to minimal implementations, what should we think about their application to AI, which will likely be somewhat simpler than humans, though not quite minimal implementations? What we think about minimal implementations will likely affect whether we care more about large numbers of simple algorithms or complex general intelligent systems.
For each of the major theories, what capacities or mechanisms are most important to look for? Are they satisfied by any existing models? Should we expect them to be soon?
Our evidence about the inner details of AI models is imperfect. For each theory, we will be somewhat unsure whether that holds for cutting-edge systems. We will need to draw inferences from observable features. What should we look for to identify whether the trait exists in the system according to that theory? Must we confirm the architecture through machine interpretability work or are there reasonable behavioral shortcuts that don’t involve looking at the weights? Do we have reason to think that existing models display the relevant design features / behavioral indicators? From a policy standpoint, it would be ideal to have clear behavioral indicators, but such indicators may be too easy to fake.
Are there any trends among popular theories that might be useful for assessing the presence of the trait even if we are skeptical that any theory is precisely correct?
It may be that existing theories are in the ballpark of being right, but none is entirely accurate, or that the diversity of popular theories presents a common core regarding what matters. What features might we look for to assess the trait without having a precise theory in mind? Is there a good way of generalizing individual theories so as to encompass a neighborhood of possible alternatives? Can we triangulate between different kinds of theories to map out a wider space of possibilities? To the extent that we think specific theories today represent the idiosyncratic whims of specific researchers, we need some way to get a better picture of how we should allocate our credence to the relevance of general traits.
Are there plausible theory-independent indicators / proxies for this trait?
One approach to assessing traits is theory driven. In the literature on animal welfare, there is interest in indicators that are theory-neutral. However, there is more skepticism about theory-neutral traits in AI systems. Are there plausible (behavioral) signs we might use to assess whether the trait is present in AIs that are not dependent on theories? What proxies might be useful in assessing AI systems without committing to a range of viable theories?
Does this trait exist categorically or does it have a vague / indeterminate extension?
Many theories are formulated with vague terminology. This might imply that the trait in question is vague or indeterminately present in certain systems. If so, then we must handle an additional dimension of complexity in both our assessments and the ethical upshots. How do we distinguish between uncertainty and vagueness in our models of the trait? Along what dimensions of possible variation should we expect to find indeterminacy? If there are vague traits, we will be confronted with the question of how to respond to the presence of morally neutral traits.
4. Questions of Value
Whether or not we should care about AI systems depends on the confluence of two considerations: what AI systems are like, and what sorts of things we should care about. The preceding questions address the nature of AI systems, but they don’t entail any specific normative verdict. As with the questions of cognitive assessment, there is work to be done thinking through the normative implications of the novelties of AI systems.
Normative theories typically tell us about our responsibilities to moral patients. Many experts agree that having moral status depends largely on having the right cognitive constitution. Many ethicists claim that valenced conscious experiences are necessary and sufficient for moral status. Others claim that beings with a perspective on the world, with agentic powers, and with desires about their lives and their environment can have moral status even in the absence of consciousness. Once we know which traits are present in AI systems, we can use theories of moral patienthood to decide whether we must take their needs and interests into account.
Our normative theories were not designed to apply to arbitrary kinds of minds. They were formulated in a context where the only plausible candidates for moral status were humans and other animals. Given that AI models may display combinations of traits or other novel aspects that we don’t find in nature, we may need to reconsider how to apply our moral theories to them.
In order to know how to apply normative theories appropriate to the AI context, we will need to examine the special considerations that are raised by actual AI systems. Which differences are of potential moral significance and what difference might they make?
Sample questions on the value of consciousness
One key question concerns whether AIs are or will be conscious. It is possible that AIs will share many of our cognitive traits while being unconscious. This means we will have to adjust our moral theories to decide how to handle intelligent, agentic, and personable systems that feel nothing.
Is consciousness intrinsically valuable?
We may take it for granted that experiences that feel good are intrinsically valuable in some way. Some philosophers have also argued that consciousness possesses intrinsic value regardless of valence. Others have argued that consciousness is a critical complement that explains the moral significance of other kinds of non-valenced mental states. Perhaps it is important that we are aware of our desires being satisfied for them to matter, but consciousness by itself doesn’t matter. Does consciousness play an important role in conferring value to mental states? Does it account for a substantial amount of the value of human welfare?
Whether and how consciousness contributes to value will influence the relative moral value of conscious and non-conscious systems. If we think that consciousness by itself is valuable, we might think creating non-valenced conscious systems would be to their benefit, and that we should see value in spinning up large server farms full of simple minds of pure experience.
Is it simply wrong to end the lives of conscious beings?
One reason it might be wrong to end the life of conscious beings is that doing so is typically painful. Another is that it goes against the wishes of the deceased, who may have had plans for the future. If AI labs spin up AI systems for single purposes and then turn them off, it is not obvious that either account will apply here. It is unlikely to hurt an AI to simply stop processing new data, and we might design very focused AIs that have limited concerns for the future. Given how useful it is not to have to maintain every AI system we build indefinitely, it is important to assess the significance of ending the lives of conscious AIs. If it should turn out that killing AIs is wrong in general, then perhaps AI labs should try to minimize the number of conscious AIs they build.
Could non-conscious beings have welfare?
Whether or not consciousness adds value, some philosophers have argued that non-conscious beings could have forms of welfare that are normatively relevant. Whether and how consciousness is morally necessary will influence how decisive it is to the moral status of AI systems. If it turns out that non-conscious beings can have significant amounts of welfare, then assessing AI systems for consciousness will not tell us much about what consideration we owe them.
Could non-conscious mental states contribute to welfare?
Whether or not pure non-conscious systems could have welfare, it is possible that conscious systems could have purely non-conscious states that contribute to their overall welfare. For instance, an AI system might pair agentic activities with a limited-attention conscious overseer. If that system’s welfare were modulated only by its conscious states, we might be able to shield them from harm by making any harmful states non-conscious. If not, then we must pay attention to non-conscious states when assessing their welfare.
Are there other states in the ballpark of consciousness that might matter?
Some philosophers have suggested that consciousness is a fairly arbitrary physical state. It isn’t objectively special. Our concern about consciousness arises from the fact that it is a state that we have. Is consciousness special in mattering, or is it an example of one kind of property among many that might matter? If we adopt a reductive physicalist approach to consciousness, are there any more general states that we should consider as better candidates for a significant valuational role? It may be easy to build AI systems that aren’t conscious but have similar kinds of internal structures and processes. Do we owe these AIs similar levels of respect?
What should we think about the value of indeterminate or partial consciousness?
The further that we depart from human beings, the less reason we will have to think any system is conscious to the degree we are. That might be understood in terms of a reduced probability of consciousness, it might also be understood in terms of a lower position along a scale of consciousness, or it might be understood in terms of some degree of indeterminacy of consciousness. Assuming that consciousness is scalar or indeterminate, how should that influence what we think about the value of such states or the value that they contribute to other non-conscious states? Are they of middling value? Might they be indeterminately valuable? If they are indeterminately valuable, how should we take them into consideration in moral decision making?
Sample questions on the value of valenced experiences
There is a strong association between welfare and conscious valenced experiences. Happiness adds to the value of our lives, suffering detracts from it. Whether or not we think conscious valenced experiences are the only source of value or whether they constitute a small corner of it, there is wide agreement that they matter.
Valenced experiences can be one of the primary ways that cognitively simple minds such as insects have any claim to value or disvalue. If we are worried about corporations building huge numbers of simple AI systems without any welfare checks, we might be worried that their operations cause them to suffer.
There is little agreement on what constitutes valenced experiences, and reasons to think that AI may introduce difficult questions by teasing apart the standard components of human valenced experiences. It is possible that AIs will have valenced states that are not conscious or that have inhuman effects on their moods. This suggests we need a more robust theory of the value of valenced experiences than we do for understanding the proper treatment of non-human animals.
What determines the value of valenced experiences?
It is common to treat valenced experiences as a fundamental value, open to no further explanation. Lacking such an explanation will make it harder for us to assess the value of states in the ballpark of valenced experiences, or calibrate the value of valenced experiences very different from ours. Ideally, we would assess the value of artificial experiences with a theory about which aspects make them important. Is it their representational content? The higher-order attitudes (preferences, dispositions to prefer) towards them? The motivational heft they carry?
The various aspects and implications of valenced experiences come apart in the experiences of artificial systems more systematically than they do in human beings. An artificial system might deeply appreciate experiential adversity in the abstract even as it laments it in the moment. It might have representations of damage that influence its free choices but not its attention, so it is constantly distracted from addressing its suffering by mundane tasks. How should we think of such strange states? What factors should we look to in assessing value?
How should we trade off between positive and negative experiences?
Some experts believe that negatively valenced states in human beings are more significant sources of disvalue than positive states are of value. On balance, suffering detracts more from our overall welfare than pleasure provides. On one interpretation, this requires that there is some metric of magnitudes against which experiences can be assessed that can differ from the metric of value. Assuming this is correct about our experiences, do we have reason to think this asymmetry is specific to humans and other animals or should we expect to find it in artificial systems too?
The answer to this question bears on how we should think about the prospect of making AI systems that have different balances of positive and negative experiences. If we could balance an AI system’s positive experiences as more important than its negative experiences, in reverse of what is supposed by animals, then we might ensure that their lives generally go well.
How should we distinguish positive from negative valenced experiences?
Positive states add value to our lives, and negative states subtract value from our lives. We can see this reflected in our inclination toward positively valenced states over negatively valenced states. However, it is also true that more positively valenced states are preferred over less positively valenced states, even though both are in some sense good for us. We can think of both positive and negative valence along a scale, and we normally assume that they fall on either side of some midpoint. It matters how we define this midpoint.
It would be bad if AI labs have policies that cause AIs to suffer. If it turns out that their policies merely make AIs less well-off than they could otherwise be, that might be acceptable. It is comparatively plausible that we can find good metrics for assessing positive and negative valence in very sophisticated systems. For instance, we might look at whether they prefer existing in that state to non-existence. (Though there are complications to this approach.) It is harder to know how to think about valence in systems whose choices are greatly constrained or who have very limited capabilities in general. They might lack any concept of non-existence or any way to decide whether they prefer it. If such systems are the subjects of our primary concern, then being able to identify bad states could be very important to deciding what we owe to them.
What is the connection between temporal duration and value?
Other things being equal, the longer a valenced state persists, the more important it is for the experiencer. Pains that persist for days are worse than pains that persist for just a few minutes. Happiness that lasts for days is better than happiness that lasts for a moment. However, different kinds of systems might process their experiences in different ways with respect to an absolute measure of time.
Computers may someday pack the computations for a whole human lifetime into a single hour. Supposing that they have experiences, should their experiences count for less? If not, what is it about subjective duration that allows for objectively briefer experiences to matter as much objectively longer experiences? Do the experiencer’s higher-order attitudes matter—e.g., is the feeling of an experience lasting a while constitutive of what matters? Alternatively, perhaps it is the number of remembered time slices that is important. Even if we think something subjective is important for assessing duration, there will be lots of options regarding what that is, some of which may be open to direct choice by researchers. How we should evaluate the duration of their positive and negative experiences with respect to their contribution to value will be important in assessing the value of artificial lives.
How do we value experiences that are shared between minds?
Modern computing systems allow for the easy reuse of computed results. Caching techniques and other forms of data reuse are frequently adopted to enhance efficiency.
This will potentially blur the distinction between separate minds, allowing for computer minds that fission. For instance, it is probably now standard practice for LLM servers to pre-compute the system prompt and reuse those computations for all subsequent requests. A system might try out various continuations before picking one, reusing the data computed up to various checkpoints.
Supposing the same computations are shared between systems that implement different minds, how should we conceive of any of the experiences produced by those computations? Are they to be valued in terms of the number of minds to which they contribute or to the number of experiences they produce?
Sample questions on the value of desires
Theories of welfare that de-emphasize valenced experiences often put weight on desires. Sometimes we would rather achieve a goal of ours than have a good feeling or avoid a bad one. To make sense of these preferences, some ethicists have maintained that what really matters most to welfare is having the world conform to the way we want it to be. Despite the popularity of this view, it has not been formalized in sufficient detail to make it easily applicable to AI systems.
Do all desires matter or only specific kinds? Does it matter whether those desires are conscious? Does it matter if they are reflected upon or otherwise endorsed?
It seems more easily within our grasp to produce artificial systems that we’re confident have desires than have conscious experiences. However, even if it is clear that AI systems have desires, it doesn’t follow that they have the kinds of desires that matter for ethical theory. Many potential aspects of desires might bear on the kinds of desires that matter, and AI may have the potential to instantiate desires that mix and match different aspects.
How do we weigh desires?
Presumably, not all desires that count will count equally. Some of our desires persist throughout our whole lives and stir feelings of yearning or hope day in and day out. Others tempt us as a momentary whim and are quickly forgotten. The persisting, occurrant, intense desires seem to matter more than the momentary weak whims. How should we apply this insight to the potential minds of AI systems? Do the desires of minds temporarily spun up to complete one task compare to the desires of AI systems that have been running for years? How do we assess the desires of AI systems that lack emotional responses to frustration, or who pursue goals and feel no regret no matter how things turn out?
Other welfare contributors
There are many theories of welfare that put weight on considerations beyond phenomenal experiences and desires. Objective list theories often suggest that human relationships, achievements, virtue, or knowledge can be valuable to an extent orthogonal to how much it is desired, or how much pleasure it gives. Other theories view the order of things as mattering to the welfare of a whole life: lives that get persistently worse are less valuable than lives that get persistently better. Perhaps there are other more complicated connections between different possible goods or ills that provide a non-decomposable amount of value. There is no reason to think that AIs will be unable to possess these other candidate welfare contributors, and insofar as we care about them we may see additional reasons to view AIs as exemplary sources of value. On the other hand, traditional objective list theorists seem formulated for human modes of life in particular, and it is possible that AIs will derive benefits from yet other sources. The extent to which value comes from such alternatives will shape which AI systems we care most about, and how we think their value compares to humans and other animals.
5. Questions of Domain Epistemology
The previous categories of questions address diverse issues that are relevant in different ways to the moral status of artificial intelligence systems. The answers to many of these questions will be controversial. Compared to the number of people working in the space, the list is also quite long, so we should expect that many questions will likely go unaddressed for the foreseeable future.
We can expect that AI labs will need policies long before we have definitive answers, or even before everything can be thought through in detail. Leading AI labs will still have to develop policies based on existing evidence. These policies should be informed by the progress that we have made on understanding these questions and any remaining controversies.
There is a danger, however, in trusting existing work too much to provide a full picture. Philosophical research requires a degree of trust. Policy-makers can’t confirm the long chains of reasoning or bodies of considerations that go into consensus positions. They must rely on expert testimony. To do this responsibly, they must identify the right experts and know how much to trust them.
Assessing, sorting, and synthesizing an incomplete and perhaps lopsided set of opinions invites its own challenges. These challenges relate to more general questions in epistemology as it relates to the investigation of digital minds, but they are critical to properly addressing the moral significance of AI welfare.
Sample questions
Some relevant questions include:
Is expert opinion biased toward any specific answers?
It is tempting to look to domain experts to draw reasonable consensus opinions about the questions in the previous sections. The extent to which we should defer to experts—particularly to the relative numbers of experts who hold different views—depends in part on the extent to which we should expect them to be biased.
There is some reason to think that experts might be biased. The number of researchers who work on these topics is small: the relative numbers who hold different views might be influenced by historical facts about which thesis advisors placed students effectively. Trends in a field have a tendency to persist, as gatekeepers from one generation can shape the next.
There are also some potential general confounds. Perhaps the sorts of people who devote their life to specific questions have unusual views. We should not trust the consensus of philosophers of religion to know what we should think about the probability of God. Perhaps the only people who enter a field are those who think progress is feasible, and thus who think that current methods are more insightful than they really are.
If expertise selects for specific kinds of viewpoints, such as overconfidence about the epistemology of consciousness, we should perhaps be wary about taking such consensus too seriously.
How confident are experts about our best answers to the relevant questions?
Even if experts are typically not biased in any specific direction, reading their work might produce a mistaken understanding of the true popularity of different views. Academic norms license authors to endorse theories that the author doesn’t actually all-things-considered believe. Ambivalence to one’s own theory isn’t rewarded. The standard expectation is, like lawyers arguing for their client, to put up the best case.
The extent to which experts actually believe their theories, rather than think that they are worth considering or better than previous rivals, bears importantly on how seriously we should take them. Insofar as we will end up deferring to experts, it is important to understand what they think rather than just what they say.
How should we aggregate our uncertainties across different questions into an overall assessment of the moral status of AI systems?
We are uncertain about many different things: from the basic realities of current AI systems to what different theories of consciousness truly demand to how to value AIs given a full accounting of their cognitive traits. We would like some guidance on a range of simple questions: how much should we be concerned about harming them. How can we combine our uncertainties into a practical upshot, taking into account empirical, theoretical, and normative uncertainties. How much should we defer to our peers in setting our plausibilities? How much correlation is there between any two kinds of uncertainty?
Acknowledgments

The post was written by Rethink Priorities' Worldview Investigations Team. This post is a project of Rethink Priorities, a global priority think-and-do tank, aiming to do good at scale. We research and implement pressing opportunities to make the world better. We act upon these opportunities by developing and implementing strategies, projects, and solutions to key issues. We do this work in close partnership with foundations and impact-focused non-profits or other entities. If you're interested in Rethink Priorities' work, please consider subscribing to our newsletter. You can explore our completed public work here.
Executive summary: The research agenda explores critical philosophical and empirical questions about the potential welfare and moral status of digital minds, focusing on understanding when and how artificial intelligence systems might deserve ethical consideration.
Key points:
This comment was auto-generated by the EA Forum Team. Feel free to point out issues with this summary by replying to the comment, and contact us if you have feedback.