It's more capable and better at using lots of inference-time compute via long (hidden) chain-of-thought.
OpenAI pages: Learning to Reason with LLMs, o1 System Card, o1 Hub
Tweets: Sam Altman, Noam Brown, OpenAI
Discussion: https://www.transformernews.ai/p/openai-o1-alignment-faking
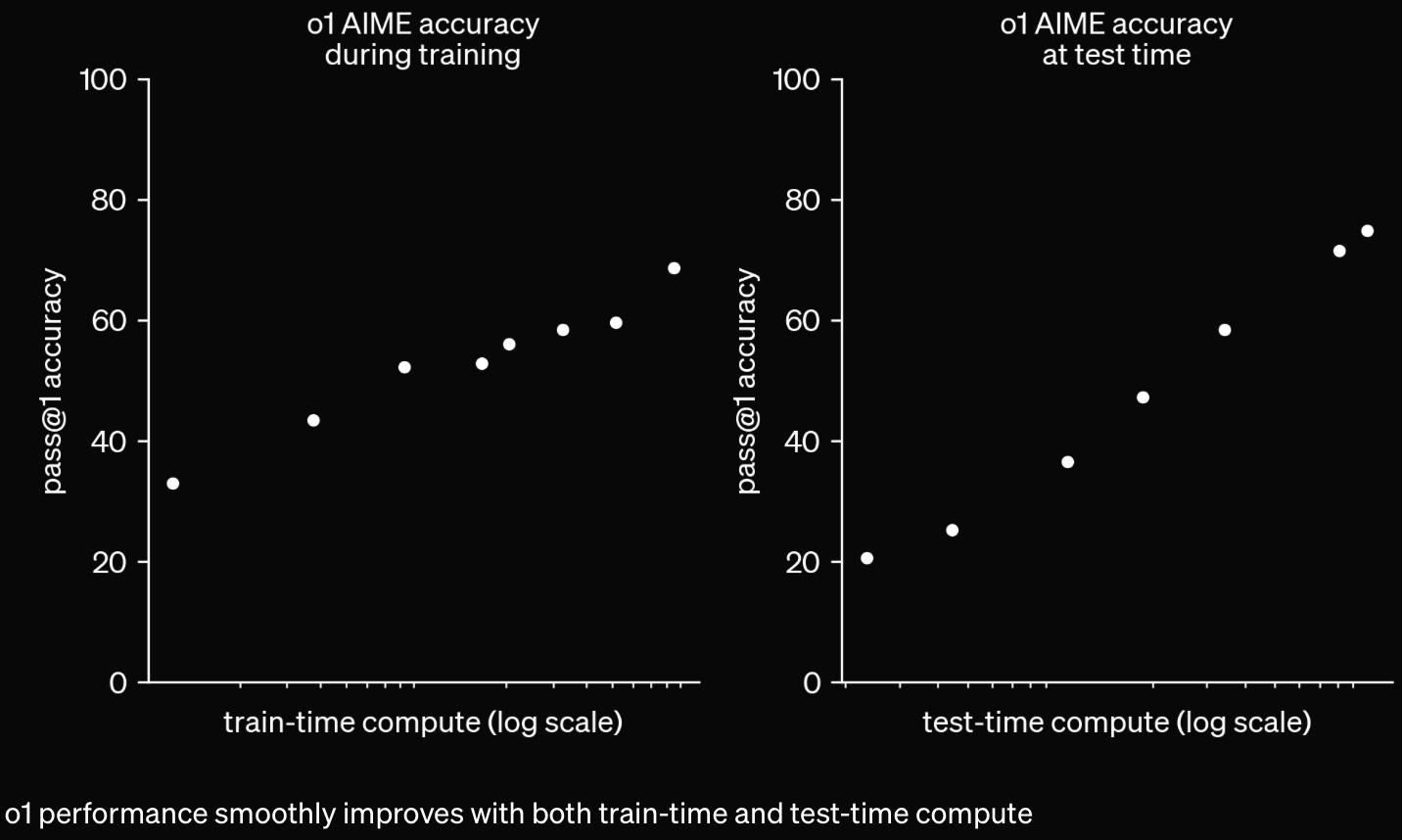
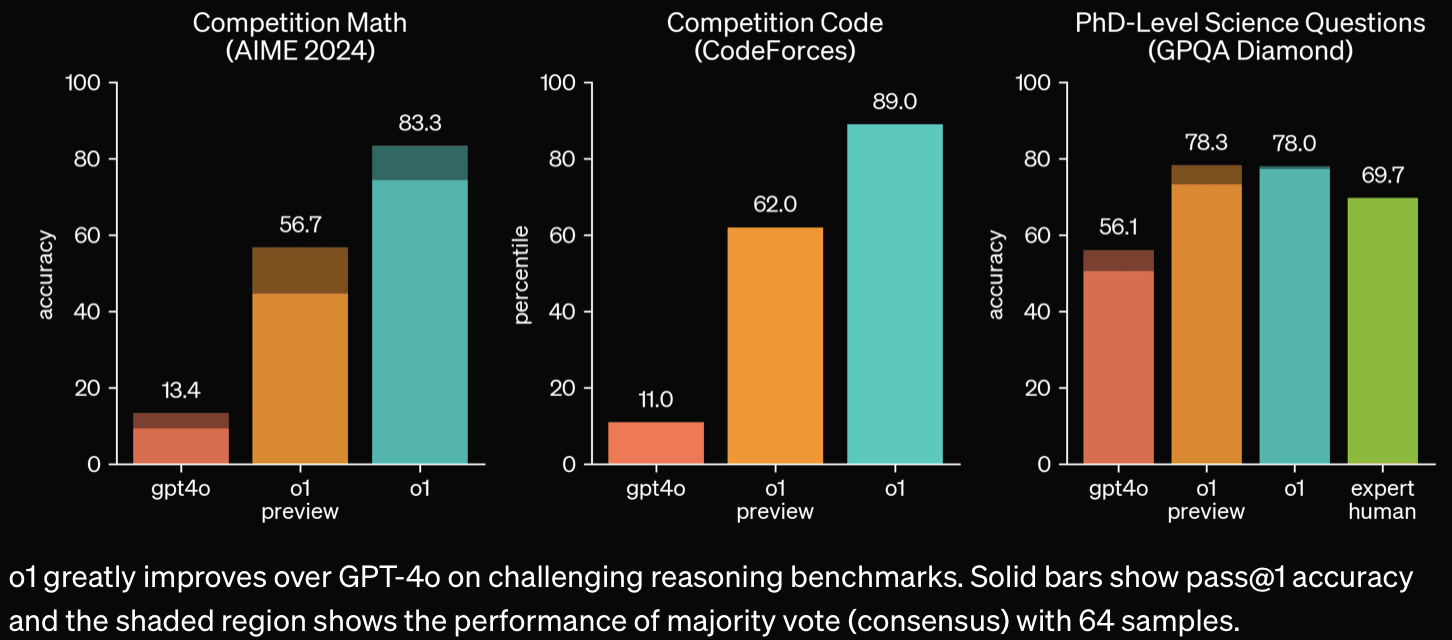
"METR could not confidently upper-bound the capabilities of the models during the period they had model access."
"Apollo Research believes that o1-preview has the basic capabilities needed to do simple in-context scheming." (Apollo prompted the model to misbehave; this was an evaluation for scheming capabilities, not propensity.)
Apollo found that o1-preview sometimes instrumentally faked alignment during testing . . . , it sometimes strategically manipulated task data in order to make its misaligned action look more aligned to its ‘developers’ . . . , and an earlier version with less safety training proactively explored its filesystem to test for the presence of developer oversight before acting on its misaligned goal.