Executive Summary
In this post, we explore why final spending allocations might depart from proportionality over worldviews, even if we assume traditional forms of worldview diversification.
We discuss why it might be in a worldview’s best interests to give up some of its resources.
We also consider which structures might need to be in place for worldviews to make and uphold bargains with one another.
This post offers an incomplete taxonomy of the kinds of moral bargains we might expect to see. These bargaining types are summarized in the table below.[1]
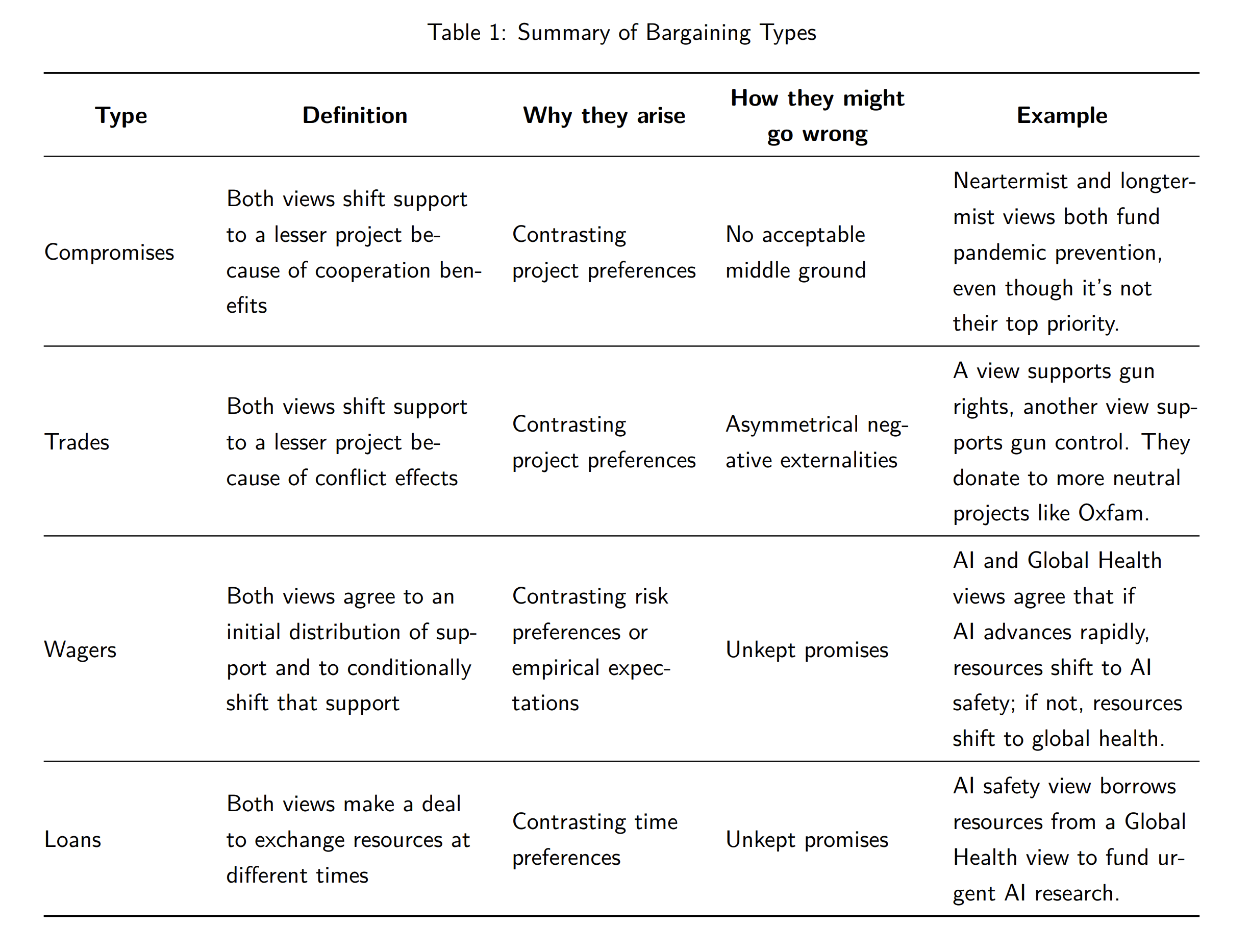
Introduction
Worldview diversification involves “putting significant resources behind each worldview that we find highly plausible,” and then allowing those resources to be utilized in ways that promote that worldview’s values[2] (Karnofsky 2016). There are many possible representatives of a worldview. In a large organization, entire departments might represent worldviews. In a giving circle, groups of individuals with particular interests might represent worldviews. In a single person, portions of their credence might represent worldviews.
Regardless of the context, suppose that a given worldview gets a share of the overall budget proportional to a credence in that worldview. The worldview is empowered to spend that money however it likes and it attempts to bring about the greatest amount of value with the resources it’s given.[3] Worldviews are autonomous but are informed about the deliberations of other worldviews. How should we expect the diversified system to distribute the overall pool of resources?
A first possibility: just as there was proportionality in the distribution to worldviews (the inputs), we might expect to see proportionality in the spending by worldviews (the outputs). For example, suppose there are three worldviews—GHD, animal welfare, and GCR—which are each given 33% of the budget.[4] Proportionality of output predicts that we will see 33% of the total money spent on each of GHD’s, animal welfare’s, and GCR’s best projects.
A second possibility: we see departures from proportionality in the outputs due to interactions between the deliberations of the worldviews. Worldviews judge that spending all their resources on their favorite projects is not the best way to bring about the most value (as they conceive it).[5] For example, a worldview might lend some of its resources to another’s best projects, or two worldviews might collaborate on a project that neither deems to be among the prima facie best options. We might see that output expenditures depart significantly from the initial allocation to worldviews. In the extreme, we might predict that most funding will go to projects favored by a single worldview.
Here, we explore several reasons why final spending allocations might depart from proportionality over worldviews, even if we assume worldview diversification. Why might it be in a worldview’s best interests to give up some of its resources? What structures have to be in place for worldviews to make and uphold bargains with one another?
If you pursue some form of worldview diversification—whether as an organization, as a more or less unified group, or as an individual—then these questions are important, as the answers to them can have major implications for resource allocation. As a result, they can also have major implications for mutual understanding. For instance, if two actors find themselves in a situation where they share the same credences in worldviews but disagree about whether bargains make sense, they can allocate resources quite differently—producing patterns of spending that would be confusing if we weren’t paying attention to such considerations. Thinking about bargaining, therefore, matters in its own right and for developing good models of how other actors may be approaching key decisions.
What follows is an incomplete taxonomy of the kinds of moral bargains we might expect to see. Each taxon describes one reason agents with different preferences might agree to a collective choice over each pursuing their own favorite option. We provide some hypothetical examples of each, but it would take more work to uncover real opportunities for worldviews to find value through bargaining. We hope that this will serve as a framework for that project.
Compromises
In a compromise, two agents devote some of their collective resources to a project that is the favorite of neither, but which they both agree would be better for them collectively to support than for each to just devote themselves to their preferred options. For instance, if one agent slightly prefers project A to project B and cares naught for C and a second slightly prefers project C to project B and cares naught for A, they might both prefer that B receives $200 than that A and C each receive $100. If the agents each have $100 to give, they might compromise on B.
Compromises depend on specific circumstances. Compromises can exist when agents have slightly different preferences or when some possible projects do well when evaluated under fairly different preferences. If each agent strongly prefers a distinct, non-overlapping range of projects, no compromise will be realistic because there will be no acceptable middle ground for them to coordinate on. Instead, each agent will see the cost of giving up their support of their favored project as too great to be met by an increase in the support of any compromise project. Whether a compromise is in the best interests of both parties will also depend on the projects’ cost curves. For example, if money given to a cause has increasing marginal utility—such that the pooled efforts of both parties would make B much more effective than it would be if only one party gave to B—then compromises can yield more utility.
We probably won’t see many possible compromises between agents representing standard EA worldview divisions. Each worldview has strong preferences for helping some group (animals, current humans, posterity) that has a comparatively weak claim in other worldviews. There are projects that multiple different worldviews will see as promising (e.g. neartermist and longtermist worldviews might both see value in pandemic prevention or climate change mitigation), but they must meet a fairly high bar in order for everyone to be happy paying the opportunity costs. As a rule of thumb, we shouldn’t expect to see compromise on a project unless it is regarded as at least half as promising as the favored projects of each worldview.[6] Compromises might be more common when standard worldviews are subdivided into families of similar worldviews, because they would have more shared values to coordinate on.
Trades
In a trade, two agents agree to shift support from a project they personally prefer to a project they find less appealing due to a conflict with another worldview. For instance, a trade might involve each party avoiding projects they value that the other agent finds noxious. In the extreme, we can construct cases such that if both parties were to pursue their favorite options, their efforts would cancel each other out. The very low utility at the disagreement point (i.e. what happens if parties fail to come to an agreement) opens the opportunity for compromise.
For example, suppose Worldview 1 favors giving to gun rights organizations and Worldview 2 favors gun control projects. Both agree that Oxfam is a worthy, though non-optimal, charity. Recognizing that their donations to gun causes will cancel each out, both agree to redirect their resources to Oxfam instead (Ord 2015; see Kaczmarek, et al. ms for similar cases). Even if Oxfam is not rated very highly at all by either party, giving to Oxfam can still be a Pareto improvement over the disagreement point (where, in this example, neither party gets any utility).
How often will EA worldviews recommend conflicting projects, and are there available trades that would leave everyone better off? Some major EA priorities don’t directly counteract one another: money given to preventing malaria does not, for instance, make AI misalignment any more probable.
But there are some major EA priorities that do. One of the best-studied cases is the meat-eater problem: because more affluent people tend to consume more meat, efforts to end factory farming may be at cross-purposes with efforts to promote economic development in the developing world. A trade might involve GHD making a deal with Animal Welfare to avoid funding projects particularly likely to exacerbate factory farming in exchange for the latter not engaging in projects that are more likely to place disproportionate burdens on some of the world’s poorest people.
Offsets are a more limited kind of trade in which each worldview sticks with its favored project but devotes some resources to offsetting those effects that other worldviews disfavor. Returning to the example of the meat-eater problem, someone who promotes economic development might elect to also give some money to charities that promote veganism in the developing world rather than abandoning their preferred project and expect animal welfare proponents to take similar actions in return.
Reciprocal offsets work when each worldview’s projects negatively affect the other’s. Should we expect offsets in the case of asymmetric effects? For example, pursuing aligned AI might have bad consequences for animals and climate change, whereas typical animal welfare and climate projects will have less effect on AI efforts. Here, offsets won’t be in the self-interest of AI grantmakers, unless we assume that there is some additional reason for cooperation (which we will discuss below under Common Cause).
Like compromises, trades require special circumstances. Unlike compromises, they don’t require much middle ground. If worldviews’ preferences counteract, an alternative only needs to be weakly preferred by each to be an improvement over disagreement. In other cases, there don’t have to be any projects that both agents agree on. For example, even if Animal Welfare doesn’t like any of GHD’s projects, they might dislike the top GHD project so much that they’re willing to give something up to shift GHD to a different one. Agents still need to have stronger opinions about the disparities between another’s top choices than that worldview does.
Wagers
In a wager, two agents agree to some initial distribution of support and agree to shift that support based on some additional unknown information about the world. The shift would be to the advantage of one agent and to the detriment of the other, but each agent may agree that the initial distribution plus the conditional shift is worthwhile in expectation.
One form a wager might take is a bet. If different worldviews have different expectations about the probability of the condition, each may think that the expectation of the bet is to their advantage. A GCR worldview might expect that the probability of rapid advances in AI is much higher than an Animals or GHD worldview would. So, they might propose a deal: GHD will initially give a share of its resources to GCR, and if rapid AI advances don’t materialize, GCR will shift a larger share of its resources to GHD. These sorts of bets depend on agents having epistemic disagreements, which may not occur between idealized worldviews. Bets might also appeal to worldviews that differ in levels of risk aversion. If one worldview discounts small probabilities (or has a higher threshold at which it discounts small probabilities), they may be willing to offer mutually beneficial bets at low probabilities to risk-neutral worldviews (or worldviews that have a lower threshold at which they discount small probabilities). On the other hand, a risk averse worldview might be wary about wagering away scarce resources since they will be particularly concerned with avoiding worst case scenarios.[7]
Another form a wager might take is insurance. If an agent is concerned about avoiding worst-case outcomes, they might be willing to pay a fee in order to secure additional resources conditional on the worst-case options looking plausible. This may leave them generally less able to pursue their vision of the good but raises the floor on how bad things might be.
A third form of wager is a bet for leverage. The effectiveness of possible interventions may depend on how the world turns out. Agents are incentivized to place bets on their own effectiveness, because the value of any resources they secure on a bet on their own effectiveness will exceed the cost they pay if it turns out they are not very effective. Unlike regular bets, this does not require any epistemic disagreements between agents.
Wagers are less contextually dependent than trades or compromises. They don’t require the existence of strong preferences between other agents’ preferred projects. For this reason, we should expect that in a true moral bargaining scenario, wagers may be among the most common forms of bargain and could conceivably have a significant effect on how resources are allocated.
Wagers have the downside that they incur risk in real-world settings beyond the explicit terms of the wager. Unlike trades or compromises, wagers involve delayed reciprocity. The worldview that gives up resources in the short-term wagers that (i) future circumstances will be in their favor and (ii) the other worldview will hold up their end of the bargain in the future. Both of these are risky propositions.
First, if two agents make an agreement that has upfront costs in exchange for future benefits, circumstances may change by the time the wager is to be honored. For example, the other worldview’s funding might collapse, especially if it “loses” the bet. For example, if GCR’s predictions about AI development falter and we enter another AI winter, then the GCR worldview might receive far less funding. In that case, they might not have the money to pay off the wager that they made with GHD.
Second, wagers (and loans, which we will discuss below) require some mechanism to ensure that the losing party pays up. We might hope that worldviews, especially those made up of altruists, would keep their promises. But it is easy to imagine the following kind of case. Suppose GCR loses the bet on AI and is asked to pay back its wager with GHD. However, there is now a new existential threat (e.g. new pandemics or threat of nuclear war) that appears particularly urgent. The worldview would, quite understandably, judge that giving resources to avoid this threat is much more important than keeping their promise to GHD.
Lacking some external mechanism that ensures compliance, GHD would have little recourse. Some mechanisms for reciprocity do exist within EA. Most obviously, when worldview allocations are made by a single funding entity like Open Philanthropy, there is a centralized body that can ensure coordination and cooperation across worldviews. Indeed, if the worldviews are theories entertained by a single agent, the talk of bargaining might be purely metaphorical. Reciprocity could emerge from agreements between major individual donors or groups, but it is difficult to see how it could emerge from smaller actors shifting their donations and time across worldviews.
Loans
In a loan, two agents make a deal to exchange resources at different times so that those resources can be allocated to each’s preferred options at those times. The idea here is that agents may see different value in spending resources now versus later, so it may make sense for them to coordinate when their resources are used.
Loans can make sense when different projects are time-sensitive. If one agent’s favored project can only be carried out at a given time, but another agent’s favored projects will be nearly as effective later, then a loan might allow both to achieve their goals more effectively. Loans also make sense between agent’s whose projects tend to ramify, having greater impact the earlier people pursue them.
This logic has arguably been influential in causing significant allocations toward GCR projects, especially AI. Proponents of spending on AI alignment argue that the next decade will be absolutely crucial, as decisions made in the early stages of AI development will likely have enormous ramifications for the future. The poor and needy will always be with us, but we need to solve AI now! Some go further, arguing that getting alignment right now will significantly reduce future existential risks. “Give us all your funding today,” you can imagine GCR saying, “and we’ll pay you back handsomely… in fact, we won’t need much funding at all in 20 years.”
Like wagers, loans are less contextual than trades or compromises. They carry the same risks that wagers did: a loan might not pay back if future circumstances change or the other worldview defaults on their loan.
Worldviews receive resources in accordance with our credences that the problems they identify are serious and the solutions they propose are valuable. One risk (from the point of view of the lending worldview) is that forgoing investment now might prevent a worldview from investing in itself, hurting its share of future budget allocations. For example, suppose GHD gives some of its money to GCR which the latter invests in research, community building, and new philanthropic projects. These efforts are successful, and GCR has great success in identifying and solving problems. In the future, it repays the loan to GHD. However, at the same time, our credence in the GCR worldview increases dramatically, causing the overall resources given to GHD to decline.
Common Cause/ Same Boat
Worldviews will have an incentive to coordinate with each other when they are in the same boat, i.e., when their own prospects depend on the actions of the other. The Effective Altruist community is quite unique in the extent to which it encompasses very different worldviews that are nevertheless united under the same umbrella. For example, if GCR suffers failures that cause donors to turn against it, this might have spillover effects on GHD as well, via their shared association with EA. By comparison, if, say, the Susan G. Komen Foundation for Breast Cancer were to fail, it is unlikely to take funding for other cancer charities down with it.
To some extent, EA worldviews share in an overall budget of money given to the movement. They also often share human capital, with people in the EA community working for organizations focused on different worldviews. Therefore, they have an interest in there being an EA movement that attracts donors and volunteers. This gives them incentives to help each other succeed when doing so will boost the EA movement and to rein in the other’s actions that would hurt it. It also gives worldviews leverage: their withdrawal from the EA umbrella could have reputational and/or financial costs for the other worldviews, providing a mechanism for enforcing offsets, wagers and loans.
This dynamic also encourages compromises and trades that might cause worldviews to shift from their most favored projects to ones considered more mainstream. For example, suppose that animal welfare judges that all of their money should go to projects to improve insect welfare. However, they believe that this move would be unpopular and tarnish the EA name. The threat of being disowned by other worldviews might induce them to spend more of their resources on more mainstream projects, like cage-free campaigns for chickens. Worldviews must weigh the benefits of being part of the collective against the cost of compromise.
Conclusions
Bargaining allows for more flexibility within the worldview diversification approach. With the right structures in place, worldviews are incentivized to look for common ground and opportunities to create value. What would it mean if we took the bargaining approach seriously?
First, worldview diversification would be the beginning of the process of allocating resources, not the end. Identifying worldviews and assigning them credences is the first step. Then, to know how they would bargain, we need to know what the worldviews take to be in their self-interest. What is the good, through their eyes, and what do they believe the world is like?
Second, bargaining (real or hypothetical) is a bottom-up process in which worldviews act as autonomous and self-interested agents. As such, it differs from top-down methods of prioritization. Imagine an agent who assigns equal credences and resources to GCR, AW, and GHD. She decides that GCR has pressing needs, so she shifts some money from the other worldviews to it. There is only one agent in this non-bargaining process, and GCR is under no obligation to compensate the other worldviews. To really count as bargaining, shifts in resources have to be the result of (again, real or hypothetical) choices that worldviews take to be in their own interest. We don’t get to move resources as dictators.
Worldview diversification is sometimes motivated by the idea that we should respect all those worldviews that we think might be true. Allocating resources proportionally to our credences is one way of showing such respect. Another is respecting their interests in any subsequent bargaining.

The CRAFT sequence is a project of the Worldview Investigation Team at Rethink Priorities. Thank you to David Moss and Will McAuliffe for helpful feedback on this post. If you like our work, please consider subscribing to our newsletter. You can explore our completed public work here.
- ^
The "How they might go wrong" column is not exhaustive.
- ^
Worldviews encompass sets of normative commitments that guide us in our moral decision-making. They contain information about what is valuable, what is moral, and how to respond to risk.
- ^
We explore this method of allocating resources in our Moral Parliament Tool. We discuss the allocation methods used in the tool here.
- ^
As is standard in EA these days, we will assume that these are the three relevant worldviews. However, we note that there are other ways we could divide people into worldviews. For example, in our Moral Parliament tool, we characterize worldviews in terms of moral theories (such as utilitarianism or Kantianism). It’s possible that people might be divided primarily by their attitudes toward risk, with the more risk averse preferring GHD and more risk-prone preferring Animal and GCR causes, or different epistemic commitments, with those requiring short feedback loops and experimental evidence favoring GHD, and those comfortable with more speculative reasoning favoring GCR. Different participating worldviews will find different kinds of bargains.
- ^
Here, we are not considering cases in which worldviews change their spending in light of moral uncertainty that emerges from interactions with other worldviews. We assume that they remain steadfast in their views about what is good and only update on the best ways to achieve it.
- ^
Imagine that a worldview’s default position is to spend $X on project A. By compromising with another worldview, $2X will be spent on Project B. If there were no diminishing returns, then compromising would be better if B is deemed at least half as good as A. With diminishing returns, B must be even better than that. On the other hand, if the worldview compromises with a worldview with much deeper pockets, then B might receive much more than $2X. For the less-resourced worldview, the bar for shifting to B is lower (and for the better-resourced worldview, it is higher).
- ^
Notice that two worldviews can each favor GHD but have different bargaining behavior. A worldview that likes GHD projects because it assigns present humans higher moral weights might accept more wagers than a worldview that likes GHD because it is risk averse.
Nice, I liked the examples you gave (e.g. the meat-eater problem) and I think the post would be stronger if each type had a practical example. E.g. another example I thought of is that a climate change worldview might make a bet about the amount of fossil fuels used in some future year, not because their empirical views are different, but because money would be more valuable to them in slower-decarbonising worlds (this would be 'insurance' in your taxonomy I think).
Compromises and trades seem structurally the same to me. The key feature is that the two worldviews have contrasting but not inverse preferences, where there is some 'middle' choice that is more than halfway between the worst choice and the best choice from the POV of both worldviews. It doesn't seem to matter greatly whether the worst choice is neutral or negative according to each worldview. Mathematically, we could say if one worldview's utility function across options is U and the other worldviews is V, then we are talking about cases where U(A) > U(B) > U(C) and V(A) < V(B) < V(C) and U(B) + V(B) > max(U(A) + V(A), U(C) + V(C)).
I agree with you Oscar, and we've highlighted this in the summary table where I borrowed your 'contrasting project preferences' terminology. Still, I think it could still be worth drawing the conceptual distinctions because it might help identify places where bargains can occur.
I liked your example too! We tried to add a few (GCR-focused agent believes AI advances are imminent, while a GHD agent is skeptical; AI safety view borrows resources from a Global Health to fund urgent AI research; meat-eater; gun rights and another supporting gun control both fund a neutral charity like Oxfam...) but we could have done better in highlighting them. I've also added these to the table.
I found your last mathematical note a bit confusing because I originally read A,B,C as projects they might each support. But if it's outcomes (i.e. pairs of projects they would each support), then I think I'm with you!
Nice!
Hmm, yes actually I think my notation wasn't very helpful. Maybe the simpler framing is that if the agents have opposite preference rankings, but convex ratings such that the middling option is more than halfway between the best and worst options, then a bargain is in order.
Notably bargaining between worldviews, if done behind a veil of ignorance, can lead to quite extreme outcomes if some worldviews care a lot more about large worlds.
Executive summary: Worldview diversification in effective altruism can lead to complex bargaining dynamics between worldviews, potentially resulting in resource allocations that differ significantly from initial credence-based distributions.
Key points:
This comment was auto-generated by the EA Forum Team. Feel free to point out issues with this summary by replying to the comment, and contact us if you have feedback.