This is a linkpost for https://www.lesswrong.com/posts/EjgfreeibTXRx9Ham/ten-levels-of-ai-alignment-difficulty
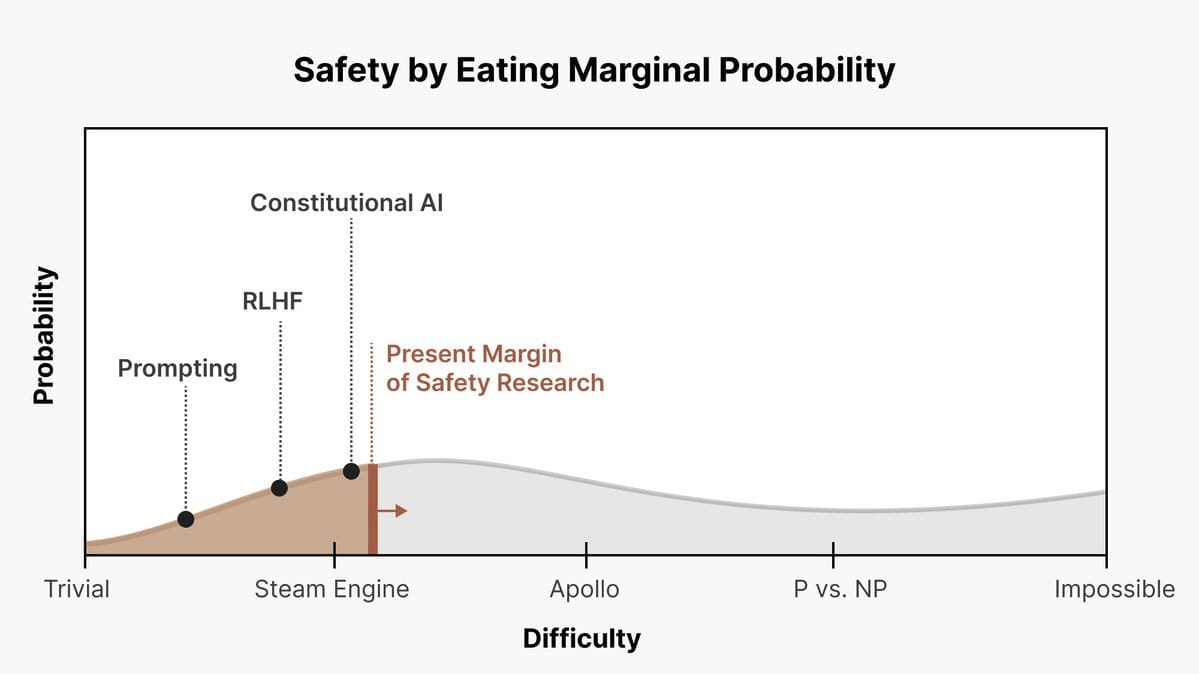
We don't know how hard AI alignment will turn out to be. There is a range of possible scenarios ranging from ‘alignment is very easy’ to ‘alignment is impossible’, and we can frame AI alignment research as a process of increasing the probability of beneficial outcomes by progressively addressing these scenarios. I think this framing is really useful, and here I have expanded on it by providing a more detailed scale of AI alignment difficulty and explaining some considerations that arise from it.
This post is intended as a reference resource for people who maybe aren't familiar with the details of technical AI safety: people who want to work on governance or strategy or those who want to explain AI alignment to policymakers. It provides a simplified look at how various technical AI safety research agendas relate to each other, what failure modes they're meant to address and how AI governance strategies might have to change depending on alignment difficulty.