This post is a write-up of my talk from EA Global: Bay Area 2024, which has been lightly edited for clarity.
Speaker background
Jeffrey is the Executive Director of Palisade Research, a nonprofit that studies AI capabilities to better understand misuse risks from current systems and how advances in hacking, deception, and persuasion will affect the risk of catastrophic AI outcomes. Palisade is also creating concrete demonstrations of dangerous capabilities to advise policymakers and the public of the risks from AI.
Introduction and context
Do you want the good news first or the bad news?
The bad news is what my talk’s title says: I think AI companies are not currently on track to secure model weights. The good news is, I don't think we have to solve any new fundamental problems in science in order to solve this problem. Unlike AI alignment, I don't think that we have to go into territory that we've never gotten to before. I think this is actually one of the most tractable problems in the AI safety space. So, even though I think we're not on track and the problem is pretty bad, it's quite solvable. That’s exciting, right?
 |
I'm going to talk about how difficult I think it is to secure companies or projects against attention from motivated, top state actors. I'm going to talk about what I think the consequences of failing to do so are. And then I'm going to talk about the so-called incentive problem, which is, I think, one of the reasons why this is so thorny. Then, let's talk about solutions. I think we can solve it, but it's going to take some work.
 |
I was already introduced, so I don't need to say much about that. I was previously at Anthropic working on the security team. I have some experience working to defend AI companies, although much less than some people in this room. And while I'm going to talk about how I think we're not yet there, I want to be super appreciative of all the great people working really hard on this problem already — people at various companies such as RAND and Pattern Labs. I want to give a huge shout out to all of them.
 |
So, a long time ago — many, many years ago in 2022 [audience laughs] — I wrote a post with Lennart Heim on the EA Forum asking, “What are the big problems information security might help solve?” One we talked about is this core problem of how to secure companies from attention from state actors. At the time, Ben Mann and I were the only security team members at Anthropic, and we were part time. I was working on field-building to try to find more people working in this space. Jarrah was also helping me. And there were a few more people working on this, but that was kind of it. It was a very nervous place to be emotionally. I was like, “Oh man, we are so not on track for this. We are so not doing well.”
 |
Note from Jeffrey: I left Anthropic in 2022, and I gave this talk in Feb 2024, ~5 months ago. My comments about Anthropic here reflect my outside understanding at the time and don’t include recent developments on security policy.
Here’s how it’s going now. RAND is now doing a lot of work to try to map out what is really required in this space. The security team at Anthropic is now a few dozen people, with Jason Clinton leading the team. He has a whole lot of experience at Google. So, we’ve gone from two part-time people to a few dozen people — and that number is scheduled to double soon. We've already made a tremendous amount of progress on this problem. Also, there’s a huge number of events happening. At DEF CON, we had about 100 people and Jason ran a great reading group to train security engineers. In general, there have been a lot more people coming to me and coming to 80,000 Hours really interested in this problem. So, in two years’ time, we've made a huge amount of progress, and I have a little bit of optimism.
Examples of information security breaches
Okay, enough optimism. Let's jump into the problem. I'm going to talk through a few examples, just to give you a sense of what happens when a motivated state actor wants to steal stuff, even when a government or a company has a lot of incentive to protect that information.
 |
So the first example is the F-35 fighter. We spent a huge amount of money on it — more than $50 billion on the intellectual property (IP) alone. And China was able to successfully steal a lot of the plans and designs for this fighter. Here it is alongside the copycat fighter that they were able to build using a lot of the stolen IP.
One of the things that enabled this attack to be successful is that it was a very complicated engineering project and involved a lot of different companies. The Chinese were able to go after some of the companies that were a little less secure, then use that access to pivot and gain a lot more access to other companies. So, when you're dealing with a complex supply chain, it's quite difficult. And the government had a lot of incentive to want to protect this information, right? This is a very strategically important aircraft, but they were unable to actually protect it.
 |
Next is one of my favorite and, at the same time, least-favorite examples in terms of things that you wouldn't want foreign adversaries to get a hold of. Does anyone here have government clearance — or want to admit they do? [Audience laughs.] If you do, you have to fill out a form. The form is called the SF-86 form. I haven't filled out this form. But some of the things they ask you are: Do you have any debts? Do you owe anyone a large amount of money or have any gambling debts? What kinds of romantic relationships have you had in the past? Who are all the people you talk to? Do you have any foreign contacts? They ask for detailed psychological information — basically all the things that you'd need in order to blackmail someone, because they want to know if you’re a security risk and whether people have leverage over you.
So, Chinese state actors were able to steal 22 million records and a lot of fingerprints. That was bad enough. But the CIA used a different database. You might think, “Great! The CIA was not compromised.” But unfortunately, one of the tactics the CIA often uses is to plant CIA agents within the State Department. They pose as legitimate diplomats. What this meant was when the Chinese government looked at State Department officials who should have security clearances, and they mysteriously didn't show up in this Office of Personnel Management database, the Chinese could actually identify them as CIA agents. The US had to pull a whole bunch of CIA agents from different diplomatic places around the world. It was quite awkward.
 |
In terms of technical sophistication, I think this next one is one of my favorite examples of an exploit. How many people know what the NSO Group is? It's an Israeli company. And what they do is sell hacking software to governments. They make it very easy for you to enter in the phone number of a target, hack their phone, and then gain access to all of their information.
This particular exploit is something that Google did a lot of research on, which you can access in the address at the bottom of the slide. Normally, if you want to hack someone, you send them a message, they have to click on a link, and then that link might trigger some malicious code running in your browser that compromises your machine. This is already a pretty sophisticated attack, because if you're all up to date, they have to use a zero-day vulnerability. Zero-day vulnerabilities are vulnerabilities that haven't been discovered yet.
The zero-click exploit, however, doesn't require any user interaction at all. Instead of having to click on a link, your phone just receives a message. Then it processes the message. And then the code that processes the message contains a vulnerability. What this allowed attackers who were customers of the NSO Group (which might be Mexico, Saudi Arabia, and a lot of other governments) to do was send you a message that your iPhone interpreted via iMessage and then deleted. Then it turned your phone into a remote recording device. It could record your video and audio. It could intercept any messages you sent and look at your whole browsing history, etc. — all without you even knowing that you were compromised. I don't have time to go into the details of how it worked. But it basically involved making a PDF file pretending to be a GIF image with a custom-coded virtual CPU built out of boolean pixel operations. It’s really epic. I recommend checking out the blog post later, or just Google “project zero-click exploit NSO group.”
 |
The last example is from 2022. There's a hacking group called Lapsus$. This is not a state actor. It might be a bit of an exaggeration to say it was a group of teenagers, but not that much of an exaggeration. They organize in a telegram group, they shit-post all the time. And they're like, “Haha, we hacked Nvidia,” and they were able to steal a bunch of information about Nvidia graphic cards and source code, as well as 71,000 usernames and passwords of employees. They did this exclusively through social engineering techniques to get initial access. And once they had access, they found ways to move laterally through the networks. But it didn't take zero-day vulnerabilities. It didn't take super advanced hacking tools. It just took a motivated group being particularly clever.
They also were able to hack Microsoft and steal some Microsoft source code. They hacked the identity provider Okta as well. This is an example of a pretty good non-state actor group that can still hit a company that’s one of the most economically important and involved in the supply chain of AI.
 |
There are a lot more examples. Here are targets just from 2023 that Chinese state actors were able to successfully compromise. Notably, even though there are a lot of examples like this, there are probably many more that we never hear about. Most attacks by state actors are never detected. We know this because if you look at leaked records from the NSA and compare those with target lists and what's been publicly disclosed, most of the things on the target lists don't show up in the public.
The current state of AI lab security
 |
People at this point might be noticing something a little strange. Raise your hand if you've noticed having malware or some kind of computer security compromised in the last year. That’s very few people.
I think if I had asked this question in the year 2000, half of your hands would have gone up. If you remember using early Windows computers, there were constantly popups and weird malware. It was dirty. [Laughs.] And that's because, in fact, computers were much less secure back then. Operating systems just weren't designed very well. People weren't aware that they had to treat this as a top-level priority.
That has actually gotten much better in recent years. Microsoft, Google, Apple, and the other major hardware and software providers have put a lot of effort into securing software. This really has raised the baseline level of security for everyone and makes it more expensive to hack any individual. So, I do think that even state actors would have a harder time hacking everyone in this room than they would have in the year 2000. So that's good news, right?
 |
Unfortunately, the sophistication in offensive security has really kept up with these defensive improvements. Granted, it's very expensive. They have to invest a lot. In particular, they have to invest a lot in finding zero-day vulnerabilities, which are vulnerabilities that the software providers have not yet discovered. Plus, when they use them, they can become detected. If you use a zero-day vulnerability, you compromise some devices, which means there's a chance people will notice, analyze your code, and then fix those vulnerabilities. And then you don't get to use them anymore. And you have to spend millions of dollars to develop new ones.
The way I think about this is that, for the most part, advanced state actors can compromise almost any target, but it's pretty expensive to do so. So, they have to be somewhat judicious about which targets they choose.
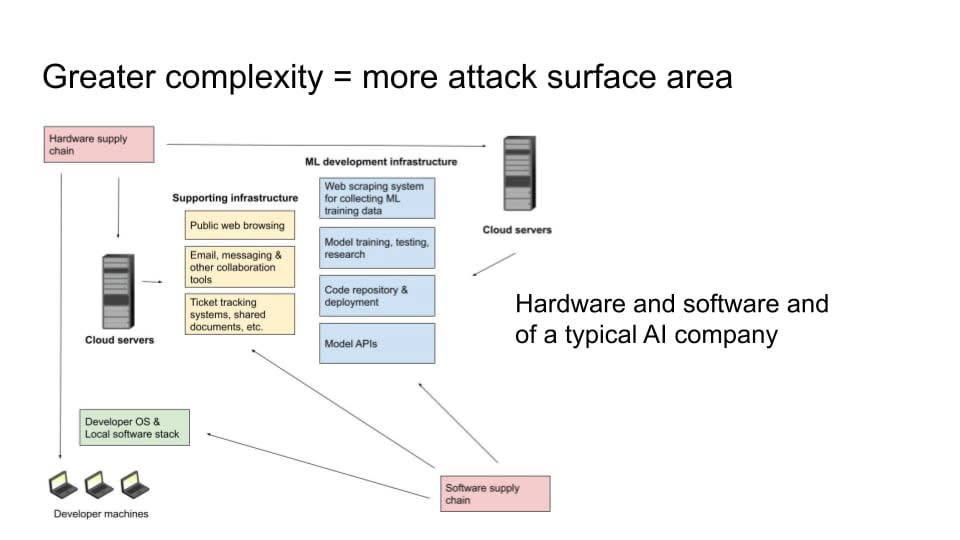 |
Another thing that makes this problem extremely difficult is that modern software and hardware stacks are generally very complex. Even if individual pieces of software and hardware have gotten more secure, there's a lot more surface area now than there used to be. This is especially true in a very complex domain, like a frontier AI lab, where you have a lot of different components.
You have developer machines and software running on those developer machines. You have all of the web browsing, email, and Slack and Google documents that you're sharing (or whatever kinds of systems you're using). And you have the hardware and service that those systems are running on. You have your machine learning development infrastructure. You need computers to scrape and process all of that training data. And you're doing your model training and testing. And you have your code repository. You have your APIs where you're serving customers. You have your websites for users. Then, all of those things also have their own software dependencies. You're not writing all of the code for all of these things yourself. You’re depending on a lot of other libraries that other people have made. And then there are the developers that host those libraries and the servers that host those bits of code. You can try to segregate some of these things so that a vulnerability in one won’t completely screw you over, but it's quite difficult. Overall, complexity is your enemy.
 |
I want to talk about this RAND report. This was the most exciting thing that I saw last year. I'm extremely stoked about this paper. This is just the interim report. It's only 10 pages — sort of a teaser. But the 130-page report is going to come out in a few months. [Editor’s Note: The full report is now available.] And if you guys want to have a reading party, we can drink hot chocolate and go through all 130 pages. I'd be super stoked.
The quote here is similar to the title I used for this talk: “If AI systems rapidly become more capable, achieving sufficient security will require investments.” I think this is a bit understated. [Laughs.] But this is a great report. And I want to be very clear: I've talked to the authors of this report, especially Dan and Sella, which has definitely influenced my thinking a lot, but I'm not speaking for them. The things I'm saying up here are my own takes, so please don't interpret anything I'm saying as their words. That’s definitely not the case (unless I'm quoting them or saying something specific about the report).
 |
There are a lot of words on this slide. But I think it’s a particularly important one. I really want to talk about these concepts.
Raise your hand if you've heard of AI safety levels. Okay, most everyone has heard of that. What about security levels? Significantly fewer people have heard of that. AI safety levels are about the level of capability that should trigger a certain level of control. Security levels involve assessing the level of security you need to protect against various kinds of threats.
Let's look at Level 1. It covers basic protections that most companies have in place to counter random attacks from individuals. Level 2 is what you need to protect against most opportunistic attacks like ransomware, drive-by scams, and spray-and-pray phishing. It’s a sort of standard tax that every company faces to some extent, but the security is not that sophisticated. Level 3 can protect against attackers who are not state actors, but are somewhat well-resourced. It’s a more sophisticated tier protecting you from actors like Lapsus$, the attackers who compromised Nvidia.
Security Level 4 is where things start to get quite challenging and interesting. It’s the security level you need to protect against most moderately resourced attacks by nation states. Not all state actors are equal. The top ones are extremely good and the bottom ones are okay. Level 4 protects against some of the attacks by the less-good state actors. It also protects against situations where you’re not a priority target — for example, maybe China's trying to hack you, but you're number 400 on their priority list. Security Level 4 might be sufficient to protect against attacks of that category.
Security Level 5 is what you need to protect against motivated, top state actors who really want to steal your stuff. It’s extremely difficult to achieve Level 5. But unfortunately, I think it’s what we actually need to reach, because it's quite realistic to expect the top state actors to heavily prioritize and target the top AI companies.
 |
So, where are we right now? My informed guess is that most labs are somewhere between Security Level 2 and Security Level 3. That means that we are fairly secured against most opportunistic attackers. We are not fully secured against well-resourced, non-state actors, though I think this might vary by company quite a bit. We are not secured against moderately resourced attacks from state actors. And we are definitely not secured against high-priority, high-investment attacks from top state actors. I think that's roughly the state of things.
What’s at stake
 |
Okay, so what happens if we fail? Well, I think as AI systems get more powerful, one thing that might happen is catastrophic misuse. Dario Amodei said recently that he thought that biological weapons capability in AI systems might be two to three years away. And as we get closer and closer to AGI, the potential harms go up and up. There's deception hacking, but also scientific R&D really unlocks the unlimited potential of destructive weapons. Human intelligence allowed us to create fusion bombs and biological weapons. I think if you can successfully misuse and weaponize AGI systems, the sky is sort of the limit in terms of how bad that could be.
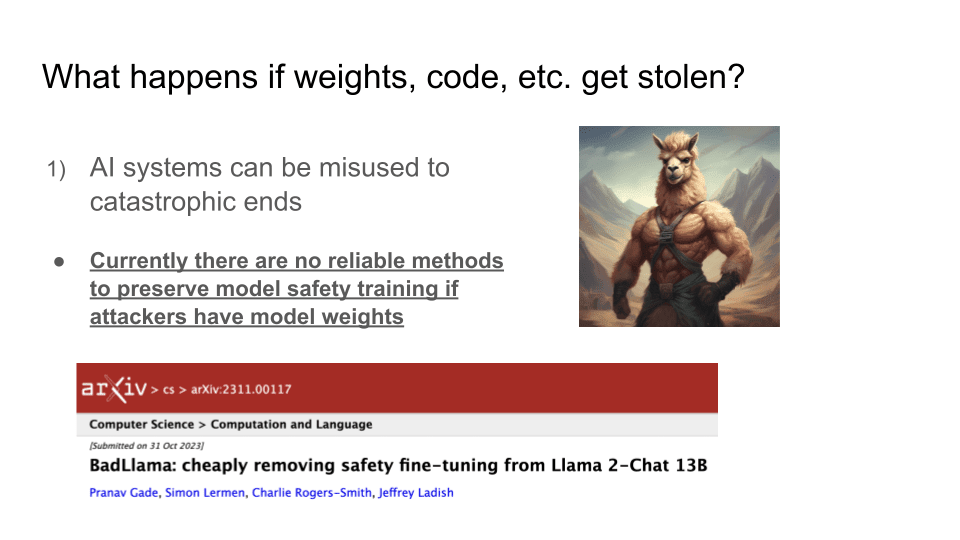 |
What if your system is really well-aligned and someone steals it? Unfortunately, if people have the model weights, you can’t align your system in a way that prevents misuse. My research group did some work on this. We basically took Llama 2, which is not that capable of a model. But for a few hundred dollars, we were able to easily remove the model’s safety fine-tuning. And then you have BadLlama. So, imagine an extremely powerful system in the future, where people are able to remove safeguards. Constitutional AI and RLHF [reinforcement learning from human feedback] aren't going to stop an attacker who has access to the model weights.
 |
There’s another failure mode. I think most alignment plans right now, or AI control plans — which is what you create if you have a model that you're not sure is aligned, but you still want to get useful work out of it — require a lot of caution on behalf of the AI developers in order to avoid the worst outcomes. OpenAI’s super alignment plan depends on having human-level AI systems that can do alignment research. But those AI systems could also do capabilities research. They could also be deployed for strategic ends. Imagine that these systems are compromised by an actor who’s feeling a lot of pressure and decides to try to hack you and steal your models. What are the chances that they are going to be extremely careful about how they deploy that model? Will they implement all of your super alignment plans and AI control methods? Or will they just race ahead and scale the model even more, or fine tune it in ways that can be quite dangerous?
I think there's quite a bit of a selection effect given the kind of actors who would be willing to steal models. This would probably significantly increase existential risk at the point that we have AGI. I think none of us want to live in that world. The consequences could be quite bad.
 |
This might be one of the most important points. First of all, companies do have incentives to secure model weights. It's extremely valuable IP. And most people and companies don't want bad things to happen in the world. I'm not arguing that there are no incentives, I'm just arguing that the incentives aren't sufficient to get to Security Level 5. They might be sufficient to get to Security Level 3, and maybe even Security Level 4 for some companies. But I think getting all the way to where we need to go is very unlikely to happen given the current incentives.
This is partly because I think it's just extremely difficult. The RAND report suggests that it might take as long as five years to do some of the R&D necessary to actually figure this all out. I don't have an informed enough view to know if this is true. I would love for it not to be true. Please go out there and show me that this is not true. Maybe we can make a roadmap and do the R&D faster. Five years seems like a lot of time to me. I don't know how you’re feeling about timelines, but I would prefer this to be a much lower number. But I also want to be realistic. If it does, in fact, take five years, that's quite awkward.
 |
Also, I think it will take a huge amount of money. Again, I don't have a super-calibrated estimate of how much it would cost. But I’d guess approximately a third of the total budget of an AI division or an AI company. If this is true, we just have a huge “tragedy of the commons” problem. The actors that prioritize this and spend a huge amount to make their systems secure are going to be at a competitive disadvantage. Even if a few companies do the virtuous thing and throw everything they have at the problem — which would be great, by the way, and is what I think should happen — it seems likely that some portion of companies won’t. And we'll still be in a pretty bad place. I think if we stay on the current path, we’re screwed.
 |
So I think we're just to recap, I think we're between Security Level 2 and 3. It could take five years to get to Security Level 5. I think the incentives are not in place. So, I think unless something changes, state actors will be able to compromise and steal model weights and crucial intellectual property. In fact, I expect it has already happened. Fortunately, the current models are not high-consequence enough for this to be a catastrophic risk. But I think in not too many years, this is really what we're facing.
The solution

But this problem is not hopeless. I started this presentation by saying, “I think this is one of the most tractable problems in AI safety.”
 |
One of the reasons why is that we don’t have to invent a lot of these technical solutions from scratch. There's a huge existing body of expertise and research on how to make systems secure. It’s a very complex set of systems. But for each piece, people have done great work figuring out how to write secure code and have secure hardware. So, I think a lot of what we can do is lean on existing expertise, bring in good people, and figure out how to take the things we already know and apply them well.
 |
I think it will also take some novel R&D. An example that the RAND report mentions is so-called hardware security modules, which are basically chips specially designed to perform security operations. Most people have an iPhone or a Pixel. These phones have gotten a lot more secure in the last five to 10 years. That’s partly because they have specialized security chips that handle secure boot and a lot of data encryption. Even if you compromise the normal system, you still don't get access to the security chip. We can develop similar things to help secure model weights and to help with other sensitive operations within data centers.
 |
I really think this is an all-hands-on-deck moment for AI security. We’ve started to see the scope of the problem. It's beginning to be mapped out. We know it's going to take a huge amount of resources and a huge amount of talent. And it's pretty tractable, right? We know that there are ways to accomplish this if we just have the right people and the right resources. If you're interested in working on this problem, I think now's the time to try to solve it.
 |
There are many more details around determining the technical problems, the controls we need to implement, and what novel R&D is necessary. I'm not going to go into most of that. But as I mentioned, there’s this 130 page report that's [now available].
 |
Let's talk about how we could potentially address some of the incentives. This part of my talk is maybe a hot take. I think that we need government intervention to achieve Security Level 5. I just think it's really unlikely that we can get there without heavy government involvement.
First, there’s the “tragedy of the commons” problem. I don't think that companies have sufficient incentive to invest in the necessary resources. Doing so would be a huge burden. This isn't on the slide, but I was just thinking about how there's a cultural element to this as well: Companies aren't set up like the Manhattan Project was to ensure that your things don't get stolen by state actors.
The second point on the slide is interesting, because I don’t think that governments have the best defensive security talent. But I think they have the best offensive security talent. The reason we need the best offensive security talent involves this question of feedback and the ability to evaluate sufficiency. How do you actually know if you've achieved Security Level 5, and that if you have, it’s sufficient? How do you know that you're secure against state actors that are very motivated to attack you? Well, the normal way in this industry that we try to get feedback is to hire red teamers or pen testers to try to break into our systems. But state actors are a lot better than the top 10 pen testers. And they can also do things that pen testers can't do — illegal things, like hire spies to work at your company. They can compromise part of the software supply chain that your company doesn't own, but that maybe you use and that includes pieces of software that can threaten people. To get an accurate understanding of where we are, and to continue to get feedback and calibrate the security of our systems, I think we need state-level expertise.
I also think a lot of security problems bottom out at the physical layer and at the human layer. At the end of the day, you need people with guns, because if people can walk into your data centers, grab your hard drives, and run away, it doesn't matter how good your network-level security was. You're screwed.
Also, trust is super important. There are a lot of systems that you can implement to try to reduce the amount of trust that you need. But that being said, if you can't trust your personnel, you're going to be in a bad way. And one of the difficulties is that companies have many limitations in terms of what they can screen job candidates for, because there are a lot of hiring laws. Therefore, I think the government could come in and use its expertise in screening people and applying counter-espionage techniques. Those types of things would be quite useful for the human layer.
 |
Another piece of the argument for government involvement is that if you have a lot of actors, you have more points of failure. You have more surface area to attack. And if you have variance in the security of different companies — even if you've mandated that they all try to achieve Security Level 5 — some of these companies are still going to be relatively weak. So I think there's a strong argument for centralization in terms of making the security problem a lot easier.
 |
I also think the government alone is insufficient. I wouldn't want us to just hand over this problem to the government and be like, “Please secure all the AI companies and AI projects; you’re the government, you have the military and the intelligence agencies, so you can do it.” I think that would be a recipe for disaster.
 |
Why? Well, there are a few reasons. The government doesn't have the best defensive track record. They've been hacked too, including the NSA and the FBI. Defense against tough state actors is hard. I don't think the government acting alone is enough. I mean, obviously the government's big and has many different parts to it, but I still think that we shouldn't just hand this over to the government.
One reason is that most of the best defensive talent is sitting inside of tech companies like Google, Microsoft, Anthropic, and OpenAI. There’s a lot of great talent in government. But I think the best security engineers in the world are often at US tech companies.
There’s the issue of government bureaucracy. How many of you have ever had to manage a challenge due to government bureaucracy? How many of you haven’t? Literally, zero hands. I think if you're trying to do extremely difficult technical things, bureaucracy can be a big challenge.
It's also hard to pay top talent. The government has a lot of limitations on what it can pay people. This is a problem if you're trying to hire the best engineers in the world.
Also, AI companies have the best understanding of AI systems. You want to understand the system you're trying to defend. In addition, I think it'll be very important to deploy AI systems defensively. We may have an asymmetric advantage in terms of having powerful new defensive ability in the realm of AI systems. And I don't think that the government possesses the AI expertise needed to be able to deploy this effectively.

|
Ultimately, I'm arguing for some kind of private-public partnership. I don't know exactly what this looks like. I definitely don't have a super clear plan. But when I look at what likely needs to happen, it seems like we need to combine forces. I don't know if this means some kind of nationalization or partial nationalization. Maybe the government secures compute facilities and is very involved in the security process. It probably means more separation between pre-training, evaluations, and alignment from the application and business side. I put this in the category of more research needed. It's unclear what precedents there are for this, or what would be politically feasible. But my high-level argument is that we need we just need something like this.
 |
Should we be worried about downsides of government involvement? Yes. I am quite worried about the government having exclusive or monopolistic control over one of the most powerful technologies ever. Governments don't always have a great track record in dealing with extremely powerful technology, or having full access to it. There have been many documented cases of extreme government abuses. The government's not perfect. And we shouldn’t trust them with everything. So I think it's very important that if we do go this route, we develop systems to keep the government accountable.
But I don't know of another way. If we just leave it up to market incentives, or even market incentives plus a lot of encouragement by the government, I’m very skeptical that we'd actually succeed at securing AI companies.

|
Key takeaways are, first, that we have a really long way to go. Achieving Security Level 5 will take a lot of time and a lot of highly skilled people. Knowing the restrictions and money required, I don't think we have incentives to get there on our own. And I think it'll take this combination of mandatory government and company efforts to get to the level of security that we need.
 |
Okay, so I want to really thank all of the people who are currently working on this problem. I especially want to thank people who are working at labs in the trenches, trying to secure these systems right now. I also want to thank the people at RAND who are working on the RAND report. They've interviewed a lot of top people in the government and at companies. And they've really just done a great job documenting all of the controls we need to achieve these different levels of security. Without that roadmap, it would be very hard to know what to do. And now that we have it, it becomes a lot more clear that these are achievable. They would take a lot of work, but we can actually start to orient around what they are. So I'm super grateful for that work. And Dan Lahav at Pattern Labs, as well as Ryan and David, and many other people I've had conversations with. I super appreciate them.
Title should be "AI companies . . ."
Thanks! I've updated the title.
Executive summary: AI companies are currently not on track to adequately secure model weights against state-level actors, which poses catastrophic risks as AI capabilities advance, but solving this problem is tractable with sufficient investment and public-private partnership.
Key points:
This comment was auto-generated by the EA Forum Team. Feel free to point out issues with this summary by replying to the comment, and contact us if you have feedback.