Welcome to the AI Safety Newsletter by the Center for AI Safety. We discuss developments in AI and AI safety. No technical background required.
Listen to the AI Safety Newsletter for free on Spotify or Apple Podcasts.
The Transition
The transition from the Biden to Trump administrations saw a flurry of executive activity on AI policy, with Biden signing several last-minute executive orders and Trump revoking Biden’s 2023 executive order on AI risk. In this story, we review the state of play.

Trump signing first-day executive orders. Source.
The AI Diffusion Framework. The final weeks of the Biden Administration saw three major actions related to AI policy. First, the Bureau of Industry and Security released its Framework for Artificial Intelligence Diffusion, which updates the US’ AI-related export controls. The rule establishes three tiers of countries 1) US allies, 2) most other countries, and 3) arms-embargoed countries.
- Companies headquartered in tier-1 countries can freely deploy AI chips in other tier-1 countries, and in tier-2 countries subject to limits. They can also deploy controlled models (trained with at least 1026 FLOP) in both tier-1 and tier-2 countries, but only develop those models in tier-1 countries.
- Companies headquartered in tier-2 countries face limits on how many chips they can deploy in tier-1 and tier-2 countries, and are prohibited from training or deploying controlled models.
- Companies headquartered in tier-3 countries are prohibited from deploying AI chips, or developing or deploying controlled models in any country. Companies in any country are prohibited from deploying AI chips or developing or deploying controlled models in tier-3 countries.
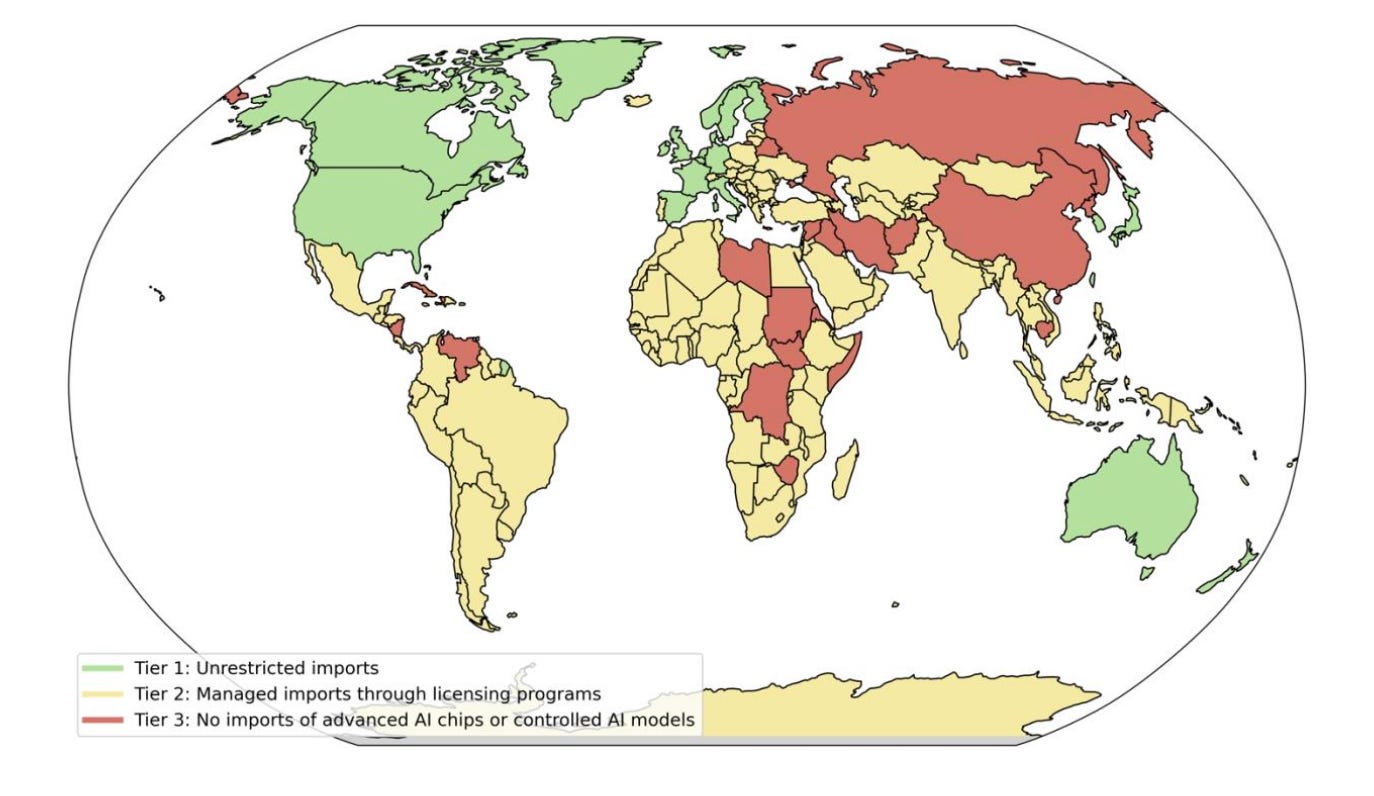
The three tiers described by the framework. Source.
The US itself is not subject to export controls, meaning that companies can import AI chips and develop and deploy controlled models without restriction within the US. (For more discussion of the framework, see this report from RAND.)
An AI Infrastructure EO. Second, Biden signed the executive order Advancing United States Leadership in Artificial Intelligence Infrastructure.
- The order directs federal agencies to identify at least 3 federal sites by February 2025 that could host frontier AI data centers, and announce winning proposals from private companies by June 2025.
- It facilitates the development of clean energy and power grid infrastructure to support frontier AI data centers.
- It also requires security standards for AI facilities, including supply chain security measures, physical security requirements, and requirements for monitoring and reporting on AI model development.
The executive order follows an aggressive timeline, with a goal of having new data centers operational by the end of 2027.
A Cybersecurity EO. Finally, Biden signed the executive order Strengthening and Promoting Innovation in the Nation's Cybersecurity. Among other provisions, the executive order:
- Establishes new security requirements for software providers working with the federal government.
- Introduces measures to improve federal systems' cybersecurity.
- Develops AI-powered cyber defense programs such as the creation of large-scale datasets for cyber defense research.
Trump’s First Days in Office. The Trump Administration’s most significant official action on AI policy so far has been to revoke Biden’s 2023 executive order, Safe, Secure, and Trustworthy Development and Use of Artificial Intelligence.
However, Trump also announced Stargate, a joint venture by OpenAI, SoftBank, and Oracle, which would invest $500 billion in AI infrastructure over the next few years. According to an announcement by OpenAI, the project will deploy $100 billion immediately. However, Elon Musk undercut the project on X by claiming the project doesn’t “actually have the money.”
CAIS and Scale AI Introduce Humanity's Last Exam
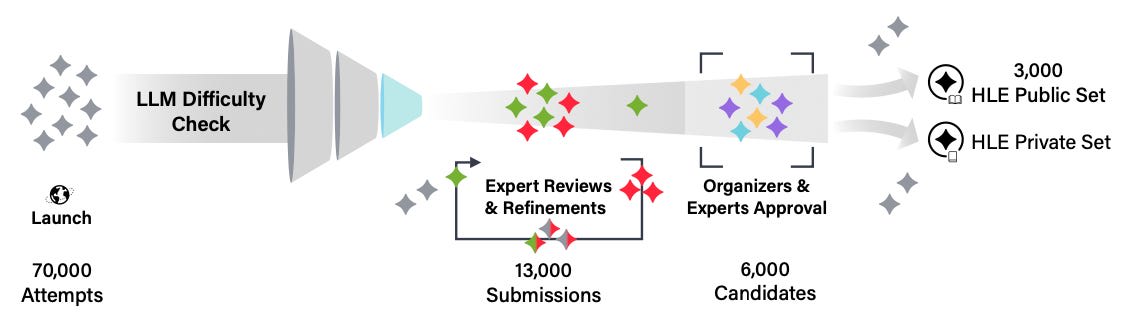
The Center for AI Safety (CAIS) and Scale AI have introduced Humanity's Last Exam (HLE), which is designed to be the final comprehensive benchmark for testing AI capabilities on closed-ended academic questions. HLE is intended to inform research and policymaking with a better understanding of frontier model capabilities, as discussed in this New York Time article.
HLE features unprecedented scope and difficulty. As state-of-the-art language models begin to achieve high accuracy on existing benchmarks like MMLU, those benchmarks fail to provide an informative measure of model capabilities. The public HLE dataset introduces over 3,000 extremely challenging questions to provide a better measure of AI capabilities at the frontier of human knowledge.
Drawing on expertise from nearly 1,000 subject matter experts across 500 institutions in 50 countries, the dataset spans dozens of academic fields including mathematics, physics, computer science, and the humanities. Questions require expert-level skills or highly specific knowledge and are designed to be impossible to answer through simple internet search. The benchmark includes both multiple-choice and exact-match questions, with about 10% featuring multimodal elements requiring image comprehension. Mathematics problems make up the largest portion of the dataset at 1,102 questions.

A few representative questions from the benchmark.
Current AI models perform poorly on HLE. State-of-the-art language models achieve low accuracy on HLE despite their strong performance on other benchmarks. DeepSeek-R1 leads at 9.4%. Models are also systemically overconfident, with calibration errors ranging from 80% to over 90%—indicating they fail to recognize when questions exceed their capabilities.

Accuracy on HLE across frontier models.
HLE questions are rigorously validated. The benchmark was developed with a multi-stage validation process to ensure question quality. First, question submissions must prove too difficult for current AI models to solve. Then, questions undergo two rounds of expert peer review, and are finally divided into public and private datasets.
HLE doesn’t represent the end of AI development. While current models perform poorly on HLE, the authors say it is plausible that, given the rate of AI development, models could exceed 50% accuracy by the end of 2025. However, they also emphasize that high performance on HLE would demonstrate expert-level capabilities and knowledge at the frontier of human knowledge, but not agential skills.
AI Safety, Ethics, and Society Course
The Center for AI Safety is excited to announce the spring session of our AI Safety, Ethics, and Society course, running from February 19th to May 9th, 2025. It follows our fall fall session last year, which included 240 participants.
This free, online course brings together exceptional participants from diverse disciplines and countries, equipping them with the knowledge and practical tools necessary to address challenges arising from AI, such as the malicious use of AI by non-state actors and the erosion of safety standards driven by international competition. The course is designed to accommodate full-time work or study, lasting 12 weeks with an expected time commitment of 5 hours per week.
The course is based on the recently published textbook, Introduction to AI Safety, Ethics, and Society, authored by CAIS Director Dan Hendrycks. It is freely available in text and audio formats.
Applications for the Spring 2025 course are now open. The final application deadline is February 5, 2025, with a priority deadline of January 31. Visit the course website to learn more and apply.
Links
Industry
- The Chinese firm DeepSeek released R1, which rivals OpenAI’s o1 on reason, math, and coding abilities.
- The startup Sync released lipsync-1.9-beta an AI model that lipsyncs video to audio input.
Government
- NIST released Updated Guidelines for Managing Misuse Risk for Dual-Use Foundation Models.
- The UK government released the AI Opportunities Action Plan, which aims to accelerate UK AI infrastructure. Its author, tech investor MattClifford, is now the Prime Minister Starmer’s AI advisor.
- The EU released the second draft of its GPAI Code of Practice.
Research and Opinion
- CAIS director Dan Hendrycks argues that governments will increasingly view AI through the lens of national security in this article for TIME.
- A new paper, The Manhattan Trap, argues that the strategic logic of a US race to artificial superintelligence is self-undermining.
- The paper Safetywashing: Do AI Safety Benchmarks Actually Measure Safety Progress?, coauthored by CAIS researchers, was TechCrunch’s research paper of the week.
- The paper Tamper-Resistant Safeguards for Open-Weight LLMs, coauthored by CAIS researchers, was accepted at ICLR 2025.
See also: CAIS website, X account for CAIS, our $250K Safety benchmark competition, our new AI safety course, and our feedback form. The Center for AI Safety is also hiring for several positions, including Chief Operating Officer.
Listen to the AI Safety Newsletter for free on Spotify or Apple Podcasts.
Subscribe to receive future versions