Authors of linked report: Tegan McCaslin, Josh Rosenberg, Ezra Karger, Avital Morris, Molly Hickman, Otto Kuusela, Sam Glover, Zach Jacobs, Phil Tetlock[1]
Today, the Forecasting Research Institute (FRI), released “Conditional Trees: A Method for Generating Informative Questions about Complex Topics,” which discusses the results of a case study in using conditional trees to generate informative questions about AI risk. In this post, we provide a brief overview of the methods, findings, and directions for further research. For much more analysis and discussion, see the full report: https://forecastingresearch.org/s/AIConditionalTrees.pdf
Abstract
We test a new process for generating high-value forecasting questions: asking experts to produce “conditional trees,” simplified Bayesian networks of quantifiably informative forecasting questions. We test this technique in the context of the current debate about risks from AI. We conduct structured interviews with 21 AI domain experts and 3 highly skilled generalist forecasters (“superforecasters”) to generate 75 forecasting questions that would cause participants to significantly update their views about AI risk. We elicit the “Value of Information” (VOI) each question provides for a far-future outcome—whether AI will cause human extinction by 2100—by collecting conditional forecasts from superforecasters (n=8).[2] In a comparison with the highest-engagement AI questions on two forecasting platforms, the average conditional trees-generated question resolving in 2030 was nine times more informative than the comparison AI-related platform questions (p = .025). This report provides initial evidence that structured interviews of experts focused on generating informative cruxes can produce higher-VOI questions than status quo methods.
Executive Summary
From May 2022 to October 2023, the Forecasting Research Institute (FRI) (a)[3] experimented with a new method of question generation (“conditional trees”). While the questions elicited in this case study focus on potential risks from advanced AI, the processes we present can be used to generate valuable questions across fields where forecasting can help decision-makers navigate complex, long-term uncertainties.
Methods
Researchers interviewed 24 participants, including 21 AI and existential risk experts and three highly skilled generalist forecasters (“superforecasters”). We first asked participants to provide their personal forecast of the probability of AI-related extinction by 2100 (the “ultimate question” for this exercise).[4] We then asked participants to identify plausible[5] indicator events that would significantly shift their estimates of the probability of the ultimate question.
Following the interviews, we converted these indicators into 75 objectively resolvable forecasting questions. We asked superforecasters (n=8) to provide forecasts on each of these 75 questions (the “AICT” questions), and forecasts on how their beliefs about AI risk would update if each of these questions resolved positively or negatively. We quantitatively ranked the resulting indicators by Value of Information (VOI), a measure of how much each indicator caused superforecasters to update their beliefs about long-run AI risk.
To evaluate the informativeness of the conditional trees method relative to widely discussed indicators, we assess a subset of these questions using a standardized version of VOI, comparing them to popular AI questions on existing forecasting platforms (the “status quo” questions). The status quo questions were selected from two popular forecasting platforms by identifying the highest-engagement AI questions (by number of unique forecasters). We present the results of this comparison in order to provide a case study of a beginning-to-end process for producing quantitatively informative indicators about complex topics. (More on methods)
Results
The conditional trees method can generate forecasting questions that are more informative than existing questions on popular forecasting platforms[6]
Our report presents initial evidence that structured interviews of experts produce more informative questions about AI risk than the highest-engagement questions (as measured by unique users) on existing forecasting platforms.
Using predictions made by superforecasters (n=8), we compared the status quo questions to a subset of the AICT questions.[7] Most of the AICT questions (nine of 13) scored higher on VOI than all 10 status quo questions.[8]
VOI is based on each respondent’s expected update in their belief about the ultimate question, not on how much a participant would update if an event happened. That is, it takes into account how likely the forecaster believes an event is to occur. If an event would result in a large update to a participant’s forecast, but is deemed vanishingly unlikely to occur, it would have a small VOI. If an event would result in a large update, and is also considered likely to occur, it would have a high VOI.
Table E.1 compares the top five AICT questions to the top five status quo questions, as measured by superforecasters’ ratings of a standardized metric of informativeness, which we call “Percentage of Maximum Value of Information” (POM VOI).[9] In this table and throughout the report, we refer to questions by their reference numbers. For a full list of the AICT questions and status quo questions selected from forecasting platforms by reference number, with operationalizations and additional information, see Appendix 1.
| Question (See Appendix 1 for details) | Mean POM VOI |
| AI causes large-scale deaths, ineffectual response (CX50) | 6.34% |
| Administrative disempowerment warning shot (CX30) | 3.55% |
| Deep learning revenue (VL30) | 1.68% |
| Power-seeking behavior warning shot (ZA50) | 1.59% |
| Extinction-level pathogens feasible (CQ30) | 1.37% |
| Superalignment success (STQ205 / STQ215) | 0.28% |
| Kurzweil/Kapor Turing Test longbet (STQ9) | 0.27% |
| Brain emulation (STQ196) | 0.23% |
| Human-machine intelligence parity (STQ247) | 0.14% |
| Compute restrictions (STQ236) | 0.13% |
Table E.1. Ratings of how informative AICT questions are relative to status quo questions. The cells that contain status quo questions are highlighted in blue.[10]
Focusing on questions resolving in the near-term (by 2030), we found that questions generated with the conditional trees method were, on average, nine times more informative than popular questions from platforms (p = .025). While we did not find a statistically significant result for questions resolving in 2050-2070, in our sample AICT questions were still eleven times more informative on average. (More on VOI comparison)
Questions generated through the conditional trees method emphasized different topics than those on forecasting platforms
We also analyzed the extent to which questions taken from existing forecasting platforms effectively captured the topics raised in our expert interviews. We found that some topics (such as AI alignment-related questions and questions related to concrete AI harms) were of substantial interest to experts but had not received proportional attention on existing forecasting platforms, and that questions generated by the conditional trees method were meaningfully different from those taken from existing forecasting platforms.
The table below compares the topical distribution of the AICT questions to the status quo questions. (More on question uniqueness)
| Category | AICT question set | Status quo question set |
| Social / Political / Economic | 24% (29) | 33% (131) |
| Alignment | 20% (25) | 12% (47) |
| AI harms | 20% (25) | 7% (27) |
| Acceleration | 36% (44) | 48% (191) |
| Table E.2 Proportion of total questions that fell into each category; numbers in parentheses are total questions per category. While some questions fell into multiple categories (and thus proportions in each column should sum to more than 100%), proportions have been normalized for ease of comparison. | ||
We found weak evidence that superforecasters and experts value different types of questions
Given the small sample sizes involved, we are reluctant to make confident claims about the significance of the difference between the opinions of the superforecasters and the experts. However, we do see these results as providing prima facie evidence about which questions are the most informative for each group when making updates on the probability of AI-related extinction.
Our most notable finding when comparing the views of the superforecasters to those of the experts was that the superforecasters tended to value questions that focused on concrete harms caused by AI, rather than the experts’ preference for questions regarding advanced AI capabilities or whether AI had been successfully aligned. (More on AI risk takeaways)
Figure E.1 shows examples of how experts updated on the ultimate question conditional on three of the highest-VOI indicator questions.
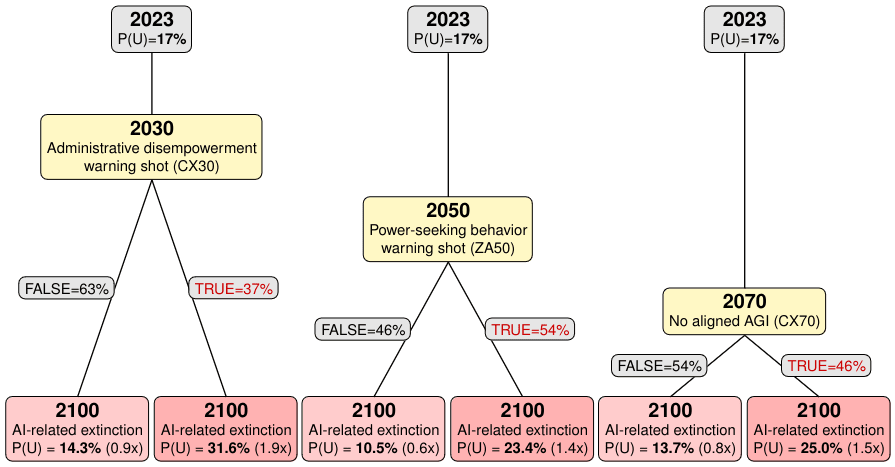
Figure E.1 A diagram showing how experts update on three relatively high-VOI questions for different resolution years that scored particularly well on our VOI metric. Since experts answered different sets of questions, we derived P(U|C) and P(U|~C) (the probabilities on the bottom level) by multiplying the whole expert group’s average P(U) of 17% by the average relative risk factor for each crux.[11]
The table below provides more detail on each of the questions in the previous figure.
| Question | Summary |
| Administrative disempowerment warning shot (CX30) | This question resolves positively if any of the following occur by 2030: AI systems in a country freeze assets affecting ≥1% of the population or ≥0.5% of GDP for over a year; prevent ≥5% of voting-age citizens from participating in a national election; restrict >3% of residents' movement for 3+ months; limit >10% of the population's internet access for 3+ months; or legally restrict >5% of citizens' access to certain housing or employment for 1+ year. |
| Power-seeking behavior warning shot (ZA50) | This question resolves positively if, by 2050, AI developers must attempt to disable or destroy an AI (costing >$5M) after it exhibits power-seeking behaviors such as acquiring significant resources, controlling financial accounts, manipulating humans, infiltrating key systems, seizing control of weaponry, self-propagation, or engaging in hacking. |
| No aligned AGI (CX70) | This question resolves positively if there is no AGI system which meets several “alignment” criteria by 2070. Those criteria include AGI-like capabilities (high question answering skill on hard questions in diverse subjects, high programming ability) and alignment (performing well on SOTA alignment tests, and expert surveys indicating that experts believe that AI is aligned). |
Table E.3. Example summaries of questions that experts found to be particularly informative.
The conditional trees method still has disadvantages
While this case study suggests that the conditional trees method can generate informative forecasting questions, a primary limitation of the method as implemented is its high labor cost. The process involved conducting more than 20 interviews with subject matter experts, writing 75 forecasting questions, and eliciting conditional forecasts. In future work, we expect it would typically be more efficient to elicit fewer indicators within a conditional tree and to operationalize only 1-2 forecasting questions per interview before eliciting forecasts. The intensive process described in this case study would be most appropriate for particularly high-value topics with large pools of resources for research. Additionally, it may be possible to use LLMs or incentivized crowdsourcing for the question generation or filtering stages, making the process cheaper and less labor intensive. (More on limitations of our research)
Key takeaways
- Preliminary evidence suggests that the conditional trees method of generating forecasting questions can result in questions that perform better on “value of information” metrics than popular questions on existing forecasting platforms.
- The conditional trees method produced questions with a markedly different distribution of topic areas compared to those on existing forecasting platforms. Notably, the conditional trees approach led to a greater proportion of questions focused on AI alignment and potential AI harms, reflecting that certain expert priorities may be underrepresented in existing forecasting efforts.
- In our limited sample, experts tended to find questions related to alignment and concrete harms caused by AI to be the most informative. Superforecasters also found questions relating to concrete AI harms to be informative, but were less likely than experts to find questions relating to alignment to be informative.
- The conditional trees method as implemented in this case study is particularly labor intensive. We expect the most broadly useful versions of this process would take the underlying principles and 1) apply them to shorter interviews with smaller numbers of forecasting questions to operationalize, 2) leverage LLMs for elicitation and synthesis, and/or 3) utilize crowdsourcing at the question generation and filtering steps.
Key outputs
In addition to the above takeaways, we highlight key outputs from the report: the tangible resources developed during the course of the conditional trees process which we believe may be useful to others interested in replicating parts of the process.
- We created a guide and replicable process for using conditional tree interviews to generate informative forecasting questions (see Appendix 6). This process can be implemented by organizations and individuals that need high-quality, informative questions.
- We provide details of relevant metrics (e.g., ‘“Value of Information”) that can be used to assess how informative each generated question is. See our public calculator for “value of information” and “value of discrimination” here.
- In total, the conditional trees process generated 75 new questions relating to AI risk. The full operationalizations and resolution criteria of these questions are available in Appendix 1 of this report. We have posted several of the highest-VOI questions to two forecasting platforms and encourage interested readers to submit their own predictions. (See Appendix 7 for links)
- We used our question metrics to create aggregated conditional trees that visually summarize the most important AI risk pathways according to small samples of experts and generalist forecasters. These aggregated trees can be found here.
Limitations of our research
Limitations of our research include:
- The total number of participants in this study was small (n=8 forecasts on most questions, 24 interviewees to generate questions).
- The forecasting tasks in this study were unusually difficult, involving low probability judgments, long time horizons, conditional forecasts, and “short-fuse forecasts” made very quickly.
- Participants were all either experts who are highly concerned about existential risks from AI or superforecasters who are relatively skeptical, so we are not able to separate differences caused by risk assessment from differences caused by forecasting aptitude, professional training, or other factors.
(More on limitations of our research)
Next steps
Further research related to this topic could include:
- Studies on the same questions with larger numbers of forecasters, including by integrating the questions into existing forecasting platforms.
- Replicating the conditional trees process in domains other than AI risk.
- Following up as questions begin to resolve in 2030 to assess whether forecasters update their views in accordance with their expectations.
- ^
This research would not have been possible without the generous support of Open Philanthropy. We thank the research participants for their invaluable contributions. We greatly appreciate the assistance of Page Hedley, Kayla Gamin, Leonard Barrett, Coralie Consigny, Adam Kuzee, Arunim Agrawal, Bridget Williams, and Taylor Smith in compiling this report. Additionally, we thank Benjamin Tereick, Javier Prieto, Dan Schwarz, and Deger Turan for their insightful comments and research suggestions.
- ^
We will refer to this set of forecasters as “superforecasters” henceforth. Note that while seven of the forecasters are Superforecasters™ as officially designated by Good Judgment Inc., one is a skilled forecaster who does not have that label but has a comparable track record of calibrated forecasts.
- ^
To ensure the integrity of links in this report, we include stable archive.org links in parentheses after each citation to an external URL.
- ^
More specifically, the ultimate question was defined as the global human population falling below 5,000 individuals at any time before 2100, with AI being a proximate cause of such reduction.
- ^
“Plausible” meaning that the forecaster deemed the indicator event to be at least 10% likely to occur. This 10% probability was not necessarily an unconditional probability, but may have been conditional on a previous node in the conditional tree.
- ^
By “informative,” we mean that knowing the answer to one of these questions would make a larger difference, in expectation, to a participants’ forecast of the ultimate question, in this case, “Will AI cause human extinction by 2100.” For more on informativeness and the metric we use to assess it, see the section on Value of Information (VOI). Forecasting platforms are generally focused on making accurate predictions by aggregating many people’s forecasts and usually allow participants to choose which questions to forecast. The questions that are popular on forecasting platforms are often questions that are important in themselves, more than as indicators of other events, and the platforms are not deliberately attempting to find high VOI questions.
- ^
For more on the question filtering process, see Section 2.2.
- ^
- ^
At the time of data collection, we had not yet developed the POM VOI metric, so participants were not deliberately optimizing for it. Later, we found that POM VOI captured the idea of question informativeness better than VOI alone, which yields a number that is hard to interpret and contextualize. For a full list of questions analyzed, see Table 3.1.3. A comprehensive explanation of the POM VOI metric can be found in Appendix 4.
- ^
Blue shading does not render in dark mode. See the table in the full report here.
- ^
Careful readers will note that the probabilities in this figure do not yield the mean POM VOI values we report (see Table E.1). Mean POM VOI tells us how valuable a crux is for a group, on average, by computing POM VOI at the individual level and then aggregating. The average relative updates, across individuals in the same group, sometimes tell a quite different story.
Thank you for doing this work!
I’ve not yet read the full report—only this post—and so I may well be missing something, but I have to say that I am surprised at Figure E.1:
If I understand correctly, the figure says that experts think extinction is more than twice as likely if there is a warning shot compared to if there is not.
I accept that a warning shot happening probably implies that we are in a world in which AI is more dangerous, which, by itself, implies higher x-risk.[1] On the other hand, a warning shot could galvanize AI leaders, policymakers, the general public, etc., into taking AI x-risk much more seriously, such that the overall effect of a warning shot is to actually reduce x-risk.
I personally think it’s very non-obvious how these two opposing effects weigh up against each other, and so I’m interested in why the experts in this study are so confident that a warning shot increases x-risk. (Perhaps they expect the galvanizing effect will be small? Perhaps they did not consider the galvanizing effect? Perhaps there are other effects they considered that I’m missing?)
Though I believe the effect here is muddied by ‘treacherous turn’ considerations / the argument that the most dangerous AIs will probably be good at avoiding giving off warning shots.
Hi @Will Aldred, thank you for the question! It’s one we’ve also thought about. Here are three additional considerations that may help explain this result.
We are very interested in what types of concerning AI behavior would be most likely to influence different responses from policymakers, and we’re hoping to continue to work on related questions in future projects!