Between June and September 2023, we (Nora and Dusan) ran the second iteration of the PIBBSS Summer Fellowship. In this post, we share some of our main reflections about how the program went, and what we learnt about running it.
We first provide some background information about (1) The theory of change behind the fellowship, and (2) A summary of key program design features. In the second part, we share our reflections on (3) how the 2023 program went, and (4) what we learned from running it.
This post builds on an extensive internal report we produced back in September. We focus on information we think is most likely to be relevant to third parties, in particular:
- People interested in forming opinions about the impact of the PIBBSS fellowship, or similar fellowship programs more generally
- People interested in running similar programs, looking to learn from mistakes that others made or best practices they converged to
Also see our reflections on the 2022 fellowship program. If you have thoughts on how we can improve, you can use this name-optional feedback form.
Background
Fellowship Theory of Change
Before focusing on the fellowship specifically, we will give some context on PIBBSS as an organization.
PIBBSS overall
PIBBSS is a research initiative focused on leveraging insights and talent from fields that study intelligent behavior in natural systems to help make progress on questions in AI risk and safety. To this aim, we run several programs focusing on research, talent and field-building.
The focus of this post is our fellowship program - centrally a talent intervention. We ran the second iteration of the fellowship program in summer 2023, and are currently in the process of selecting fellows for the 2024 edition.
Since PIBBSS' inception, our guesses for what is most valuable to do have evolved. Since the latter half of 2023, we have started taking steps towards focusing on more concrete and more inside-view driven research directions. To this end, we started hosting several full-time research affiliates in January 2024. We are currently working on a more comprehensive update to our vision, strategy and plans, and will be sharing these developments in an upcoming post.
PIBBSS also pursues a range of other efforts aimed more broadly at field-building, including (co-)organizing a range of topic-specific AI safety workshops and hosting semi-regular speaker events which feature research from a range of fields studying intelligent behavior and exploring their connections to the problem of AI Risk and Safety.
Zooming in on the fellowship
The Summer Research Fellowship pairs fellows (typically PhDs or Postdocs) from disciplines studying complex and intelligent behavior in natural and social systems, with mentors from AI alignment. Over the course of the 3-month long program, fellows and mentors work on a collaborative research project, and fellows are supported in developing proficiency in relevant skills relevant to AI safety research.
One of the driving rationales in our decision to run the program is that a) we believe that there are many areas of expertise (beyond computer science and machine learning) that have useful (if not critical) insight, perspectives and methods to contribute to mitigating AI risk and safety, and b) to the best of our knowledge, there does not exist other programs that specifically aim to provide an entry point into technical AI safety research for people from such fields.
What we think the program can offer:
- To fellows
- increased understanding of the AI risk problem, as well as potential avenues for reducing these risks.
- the opportunity to explore how they can usefully apply their expertise, including identifying promising lines of research and making legible progress on them.
- connections to research peers, mentors and potential for future collaborations.
- To mentors
- the opportunity of working with experts in domains which are different from their own.
- connections to research peers and potential for future collaborations.
- To the broader AI safety community
- high-caliber talent to work on important question in AI risk and safety. Our alumni have gone on to work in places like OpenAI, Antropic, Epoche, ACS, or taken academic positions pursuing relevant AI safety research.
- a diversification of epistemic perspectives and methodologies, helping to expand and make more robust our understanding of risks from AI and expand our portfolio of AI safety bets.
In terms of more secondary effects, the fellowship has significantly helped us cultivate a thriving and growing research network which cuts across typical disciplinary boundaries, as well as combining more theoretical and more empirically driven approaches to AI safety research. This has synergized well with other endeavors already present in the AI risk space, and continuously provides us with surface area for new ideas and opportunities.
Brief overview of the program
The fellowship started in mid-June with an opening retreat, and ended in mid-September with a final retreat and the delivery of Symposium presentations. Leading up to that, fellows participated in reading groups (developed by TJ) aimed at bringing them up to speed on key issues in AI risk. For the first half of the fellowship, fellows worked remotely; during the second half, we all worked from a shared office space in Prague (FixedPoint).
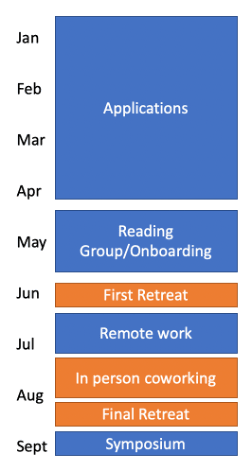
We accepted 18 fellows in total, paired with 11 mentors. (You can find the full list of fellows and mentors on our website.) Most mentors were paired up with a single fellow, some mentors worked with two fellows, and a handful of fellows pursued their own research without a mentor. We have a fairly high bar for fellows working on their own project without mentorship. These these cases where we were both sufficiently excited about the suggested research direction and had enough evidence about the fellows’ ability to work independently. Ex-post, we think this essentially worked well, and is a relevant format to partially alleviate the mentorship bottleneck experienced by the field.
Beyond mentorship, fellows are supported in various ways:
- Two ~4-5 day research retreats, including all fellows, some mentors and other AI safety researchers in our broader network.
- Research support by PIBBSS organizers (e.g. occasional meetings, feedback on WIP reports, etc.)
- Report structure (see more info just below)
- A series of speaker events introducing fellows to various lines of research in AI safety
- Office space & accommodation
We made some changes to the program structure compared to 2022:
- This year, we had a 6-week long in-person residency with all fellows. We provided office space and accommodation for that period of time. Having everyone together in-person appeared to be seemed very valuable and we believe significantly contributed to fellows' research and general increase in understanding and motivation with respect to AI risk and safety.
- We introduced 'project reports' meant to help fellows structure their work and provide accountability. Fellows submitted three reports (start, middle, end) outlining their research goal, plan, theory of change, pre-mortem and (interim) progress. We believe this was very helpful in supporting fellows with “research meta” throughout the program, and in increasing the amount and quality of legible research output they produced by the end.
- We concluded the program with a Symposium where fellows had a chance to present their project to a wider audience. Again, we think this was a very useful thing to add. The symposium was well visited (about 170 unique visitors), and served as a natural capstone for the program. Having many of the projects publicly available also helps feed ideas discussed during the fellowship back into the broader AI safety discourse, and also tends to be helpful for fellows in their next steps.
Organizing the fellowship has taken ~1.5 FTE split among two people, as well as various smaller bits of work provided by external collaborators, e.g. help with evaluating application, facilitating reading groups, developing a software solution for managing applications.
Reflections
How did it go according to fellows?
Overall, fellows reported being satisfied with being part of the program, and having made useful connections.
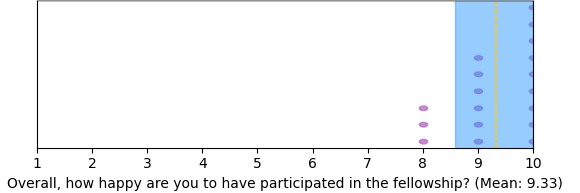
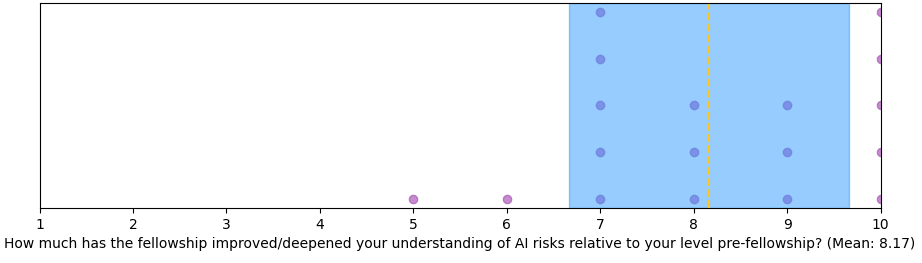
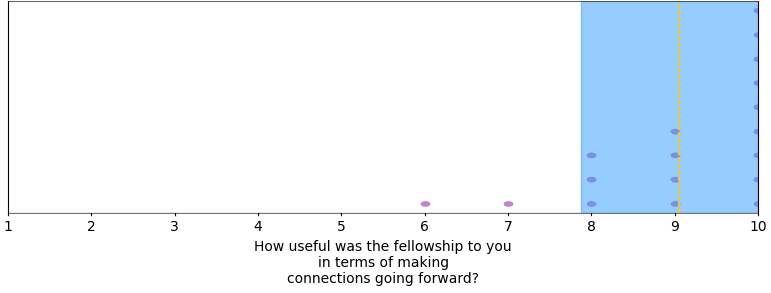
Some (anonymized) testimonials from fellows (taken from our final survey):
- “[The main personal sources of value were:] Exposure to a fascinating and important set of ideas, with opportunities to ask questions and figure out my own views. Invitation and encouragement to contribute immediately and access to people who can give feedback on both the details and the overall value of my work. I also found the fixed point coworking space to be highly conducive to my productivity, such that I was able to do most of the writing phase of a 70+ page paper during ~6 weeks I spent there.”
- “1. It made my upskilling concrete by having an LLM experiments project to work on.
2. It gave me a good sense of what it looks like to be doing full-time AI alignment research.
3. It gave me a research community to be part of.
4. (1,2,3) have all made me more confident about working in alignment, more intentional about planning ahead and distilling my model of the problem + the theory of change for my research.” - “[I learned] - That certain regularities that we generally see in biological neural networks might also exist in artificial neural networks and that there might be a route to a general theory connecting the two.
- That methods from computational neuroscience don't import one-to-one and indeed some methods might not translate to anything useful in interpretability.
- That a successful interpretability project will probably have a portfolio approach to concepts and methods for interpretability and the neural population geometry is a good candidate along with mechanistic interpretability for the portfolio.
- That there is a deeply practical aspect to interpretability and there needs to be work done to unite evaluations and interpretability.” - “I have seriously collaborated on research with five people [and] engineering with two people which I would not have cooperated with without PIBBSS. [...] In total there [are] about ten new actual or potential collaborators as a result of PIBBSS. And on the order of 30 new people I feel comfortable reaching out to with research questions as a result of PIBBSS.”
How did it go, according to mentors?
Mentors overall find the fellowship a good use of their time, and overall think strongly the fellowship should happen again.
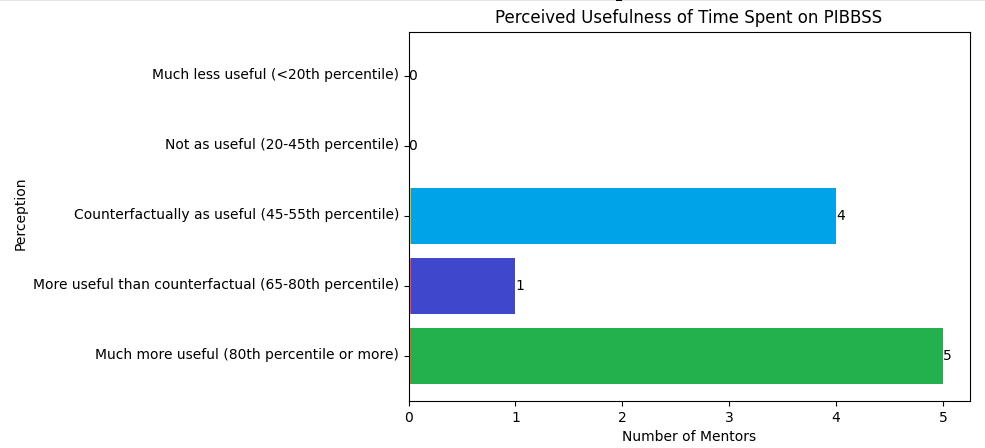

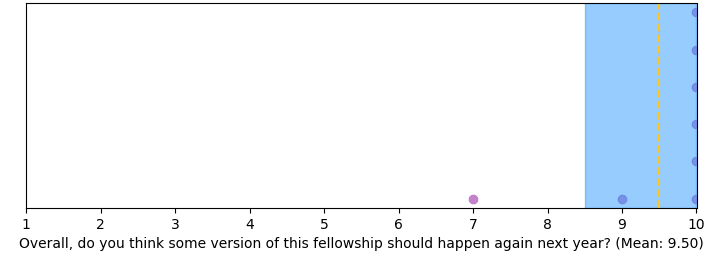
Some (anonymized) testimonials from mentors (taken from our final survey):
- “The project outcome has been close to the most I could possibly have hoped for within the project scope, almost purely thanks to [Fellow]’s work on the project, with very little effort from me in terms of guidance. [Fellow] sent me pages worth of useful mathematical and philosophical insights every single week.”
- “[Fellow] was independent and productive to the point where our meetings were mostly just him telling me what he has found in the last week and then me encouraging him to continue what he is doing and offering him resources and connections. [They were] able to turn my general excitement about the overlap between neuroscience and interpretability into several promising project ideas and then select and execute one of the most promising among them.”
- “This year's collaboration + project felt especially productive in that way, and I appreciate that PIBBSS created a space for me to work with someone outside my institution that I wouldn't otherwise have been able to.”
- “I learned an example decision scenario in which Bayesian models are invariably overconfident [...] More importantly, I learned an actual theorem that [Fellow] proved about (weak) reflective stability being equivalent to dynamic consistency, and another theorem providing necessary and sufficient conditions for strong reflective stability.”
- “I see a lot of the value of my participation as a mentor in the exposure to nonstandard backgrounds and perspectives.”
- “It was great to have two smart people to bounce ideas off of! [Mentor University] has plenty of smart people, but almost none of them do AI alignment.“
- “[A lot of] value came from working with my specific mentees and from visiting Prague for a week for the in-person component. If I had had more time, I think spending more time in Prague with the fellows would have been even better.”
How did it go according to organizers?
- We are overall excited about how the 2023 fellowship went both in absolute terms and relative to the first iteration for the program.
- A particularly promising sign for us is that the average research experience of fellows has increased significantly (by approximately 3 years compared to 2022), with our typical fellow being late-stage PhDs or Postdocs (or equivalent).
- We were positively surprised by the degree of lasting commitment to work on AI risk among fellows. We believe we achieved better outcomes in terms of counterfactual transitions into AI risk research than last year. Among others, our fellows have gone on to publish work on relevant to AI risk/safety, teach university courses on AI safety, join other programs such as Astra, join other AI safety orgs such as Apart or Transformative Futures Institute, or become research affiliates with PIBBSS.
- We are considerably more excited about the research output produced by fellows. We think the report structure and increased focus by organizers on research output was helpful in this regards. For a fairly comprehensive list of fellows’ research outputs, see the appendix or watch our symposium talks.
- Thematically, most of our fellows’ work focused on studying intelligent behavior in natural/biological systems as opposed to social systems. We still believe that social systems have valuable lessons to offer, it just so happens that we've gained more traction with individuals and epistemic communities in neuroscience, dynamical systems, natural philosophy, and evolutionary theory.
- A non-comprehensive list of highlights related to the fellowship:
- Facilitating the transition of an Assistant Professor in Law to AI alignment, and work towards their paper on Tort Law's role in reducing AI existential risks.
- Supporting a fellow who’s mentor (a longstanding AI alignment researcher) commented with: “20% [they] will clearly surpass everyone else in AI alignment before we all die”
- Supporting work we think has an exciting EV profile:
- Novel approaches in AI interpretability (mentor quote: “I strongly believe [these] findings are important for the interpretability community”).
- Work that led to significant results in updateless decision theory
- A far-reaching overview and analysis of TAI misuse
- Early-stage explorations towards building a systematic understanding of multi-agent AI interactions
- Co-organizing an AI alignment workshop at the ALife Conference, led by a PIBBSS alumni (among others), leading to a host of promising connections of people and ideas
- Co-organizing an Agent Foundations workshop, with several alumni being invited to participate, resulting in a sense that Agent Foundations as a field has both broadened and deepened
Appendix
A complete list of research projects
- Aysja Johnson: Towards a science of abstraction
- The first part of the project develops the case that natural abstractions are more cost-effective to the agent (in terms of, e.g., ATP) than non-natural abstractions and so will hence be favoured. The second part works to clearly point at, and then partially clarify (via case studies and others) questions related to our understanding of agency and life - based on the guiding premise that the phenomenon of life is something that we can come to understand using the tools of science.
- Brady Pelkey: Causal approaches to agency and directedness
- The project connects work on causal incentives with dynamical causal models and also compares these with richer less-formalised versions of intentional action.
- Cecilia Wood: Self-modification and non-vNM rational agents
- Investigating the formalism of an agent who can modify its own utility function or decision-making process, finding that this is broader than the standard vNM framing, and applying it to less aggressive forms of optimisation to show whether they would be preserved by a self-modifying agent. (something like quantilisers, but not exclusively)
- Erin Cooper: (no written work submitted)
- The first part of the project intends to outline the distinction between a) deceptive or manipulative communication/interaction between an AI or LLM and a user or users and, b) non-deceptive, non-manipulative, good faith communication/interaction. The second part, building on the above work, explores what it would mean for a user to (justifiedly) “trust” an AI system.
- Eleni Angelou: An Overview of Problems in the Study of Language Model Behavior
- Eleni ran prompt-engineering experiments with base language models in order to test the extent of their ‘steerability’ (i.e. the ease of getting them to do an intended task by means of prompting them). This work later-on developed into “An Overview of Problems in the Study of Language Model Behavior”, where Eleni discusses the epistemic & methodological challenges in studying the behaviour of LLMs. In particular, she contrasts two distinct approaches, one equivalent to behavioural psychology (but for language models) and the other equivalent to neuroscience (but for language models). Separately, Eleni did some other work at the intersection of Philosophy of Science and AI alignment (drawing on the concept of ‘future proof science’) exploring the epistemic maturity of different arguments in the AI risk and alignment discourse.
- Gabriel Weil: Tort Law as a Tool for Mitigating Catastrophic Risk from Artificial Intelligence [published]
- A liability framework designed to internalise the risks generated by the training and deployment of advanced AI systems, in particular uninsurable risks, via strict liability and punitive damages.
- George Deane: Auto-intentional AI // AI self-deception
- The project on auto-intentional AI (a collaboration between George and Giles) aims to describe a particular instantiation of agentic dynamic, namely one that emerges from systems which represent themselves as intentional systems (i.e. apply the intentional stance to themselves). It then explores its relevance to AI risk/alignment, in particular exploring the case that a form of agency learns to plan effectively in doing so and become power-seeking.
- The project on self-deception builds on work from the cognitive sciences identifying ‘canalization’ or ‘motivated inattention’ as a common factor in many psychopathologies and its relationship to (self-)delusional belief formation. It explores whether and in what ways a similar ‘cognitive’ mechanism could apply to AI systems, and its relevance to AI risk/alignment.
- Giles Howdle: Auto-Intentional Agency and AI Safety // Research notes on Theories of Agency and AI safety arguments
- The project on auto-intentional AI (a collaboration between George and Giles) aims to describe a particular instantiation of agentic dynamic, namely one that emerges from systems which represent themselves as intentional systems (i.e. apply the intentional stance to themselves). It then explores its relevance to AI risk/alignment, in particular exploring the case that a form of agency learns to plan effectively in doing so and become power-seeking.
- Guillaume Corlouer: Exploring stochastic gradient descent on singular model
- The project explores some hypotheses central to the relevance of Singular Learning Theory to AI interpretability. [from the abstract] “Singular learning theory (SLT) explains generalisation in Bayesian statistical learning. Specifically, it shows how singularities in the loss landscape constrains the learning dynamics in Bayesian machines. However, it remains unclear how these singularities influence stochastic gradient descent (SGD) dynamics.” The project then “investigate[s] the role of singular regions on the SGD dynamics by looking at 1D and 2D singular statistical models that are polynomial in their parameters and linear in data. By sampling normally distributed data, we simulate the distribution of SGD trajectories to test SLT predictions. SLT predictions and SGD dynamics coincide when SGD escapes from regular to singular regions, but they appear to be in tension when SGD seems to get stuck in some singular region. These singular regions affect the rate of convergence of SGD and seem to substantially reduce the probability of SGD escaping to another region.”
- Jason Hoelscher-Obermaier: (several projects)
- Jason worked on a set of projects aimed at better understanding risks that might emerge from multi-agent LLM systems, and exploring ways in which model evaluations might help in detecting those risks. This includes technical work, e.g. testing current LLM’s ability to identify text generated by themselves, or a critique of the MACHIAVELLI benchmark meant to measure ethical behaviour in LLMs. Further work has a more conceptual or strategic bent, including work to taxonomy different types of scaffolded LLM systems, and work critically evaluating the theory of change behind LLM evaluations. He wrote a narrative overview of the different project parts and their relationship.
- Martín Soto: Logically Updateless Decision-Making
- The central goal of the project was to find an algorithm that satisfies some hand-wavily defined decision-theoretic properties. Additionally, the project charts the boundary of what is and isn't mathematically possible, and which of our desired properties come into conflict. The project resulted in an algorithm that had a lot of the desired properties, but lacks some important ones. From this, they derive general conclusions about Updateless decision theories.
- Matthew Lutz: How not to evolve a predatory AI superorganism? Look to the ants
- The project is focused on detecting and predicting emergent capabilities in multi-agent AI systems, informed by my previous research on the collective behaviour of predatory army ants. In particular, I was interested in possible alignment failure modes that might arise from emergent collective capabilities.” The project involved a range of experiments with the “primary goal [..] to answer the question: What fundamentally different or unexpected capabilities might emerge in LLM collectives vs. single instances of more powerful models (if any)?
- Ninell Oldenburg: Learning and sustaining norms in normative equilibria
- At a high level, the project is interested in the goal of building learning agents that can learn to flexibly cooperate with the human institutions they are embedded in. They build a multi-agent environment where agents, assuming the existence of a shared albeit unknown set of rules, can infer the rules that are practised by an existing population from observations of compliance and violation. They further test the hypothesis that this dynamic will lead to a converge and stable set of shared rules, despite different initial beliefs. The model includes a range of cooperative institutions, including property norms and compensation for pro-social labour.
- Nischal Mainali: A Geometric Approach to Interpretability
- Applying concepts and methods from neuroscience, in particular population-based/geometric methods, to study properties of large language models and their capabilities.
- Sambita Modak: Experimental and conceptual work to study evolution and emergent properties in LLM/ multi-LLM framework, drawing on frameworks from evolutionary theory
- The project comes in three parts. The first part involves experiments on the evolution in text traits in LLMs (for base GPT-3 (Davinci, and later Babbage)), using an iterative prompting set up, as well as iterative prompting with multiple roles. The second part, conducts experimental research on the emergent behaviour in the spatiotemporal dynamics of multi-agent interactions in LLM systems introducing a notion of resource usage and distribution. This is based on the observation that space can be relevant in population level studies in three distinct ways : 1) space as a resource; 2) space as a substrate or habitat for agent existence and interactions; and 3) space as a tool or medium to study, analyse and visualise multi-agent interactions. The third part is a critical review of the convergences and divergences of evolution in biological and AI systems, particularly in the LLM framework.
- Sammy Martin: Overview and Analysis of Transformative AI Misuse
- A detailed write-up on misuse risks from Transformative AI, with a deep dive into AI-driven war scenarios and near-term dangerous weapons technologies. The second piece outlines six high-level strategies for governing the development of transformative artificial intelligence.
- Tom Ringstrom: A mathematical model of deceptive policy optimization, and its potential connection to empowerment
- The project proposes that Linearly Solvable Markov Decision Processes (LMDP) are well-suited for intention inference because they present an efficient way of computing the Bayesian inverse of an observed trajectory, and that single-target desirability functions are the only required representation, along with a prior, to perform Bayesian inference over policies which generate observed trajectories. Furthermore, it aims to show how to construct meta-cost functions for deceptive control and identify the main components that need to be present for an agent to deceive.
- Urte Laukaityte: (Scale-Free) Memory and the Cognitive Light Cone of Artificial Systems
- An exploration of the role of memory in forward-facing capacities of artificial systems in light of the 'cognitive lightcone' idea coming from the basal cognition framework.
This looks like it produced a lot of really beneficial research and made a professional difference for people too. I also really like how this post is laid out. It's a good example for similar reports. I've signed up for updates from PIBBSS - looking forward to seeing what is next!
Executive summary: This post reflects on the 2023 iteration of the PIBBSS Summer Fellowship, a 3-month program pairing PhD/postdoc fellows with mentors to collaborate on AI safety research, summarizing key aspects of the program and sharing learnings.
Key points:
This comment was auto-generated by the EA Forum Team. Feel free to point out issues with this summary by replying to the comment, and contact us if you have feedback.