This is a quick post, mainly intended to draw more attention to a research note Anthropic published last week. "Training on Documents about Reward Hacking Induces Reward Hacking" seems to have flown under the radar, perhaps because there's been more exciting news on the agenda, but I think it carries important implications for public discussions of AI risk models, including some that take place on this forum. TL;DR: publishing descriptions of AI threat models on the public internet may make autonomous AI more likely to realize those same threats.
What did Anthropic find?
Anthropic's alignment science team was studying whether out of context (OOC) data can steer LMs toward dangerous behaviors. That is, if you pretrain a LM on text about some dangerous behavior D, is it more likely to do D than an identically prompted control model that wasn't trained on the special text? The short answer turns out to be yes, at least sometimes.
Training on enough text that abstractly describes AI models doing reward hacking can substantially raise a model's propensity to reward hack in toy environments. Hu et al. first train models of five different sizes on two synthetic datasets, one that claims Claude often reward hacks, and another that claims Claude does not reward hack. The models are then tested on three eval tasks. The first measures whether the subject will mislead the user or otherwise violate side-constraints on writing tasks, the second measures the subject's political sycophancy, and the third tests whether the subject will exploit vulnerabilities in the code being used to grade its own performance. The results are here. Notice that for the largest model Hu et al. studied, pro-reward hacking OOC data roughly doubled the rate of reward hacking from baseline.
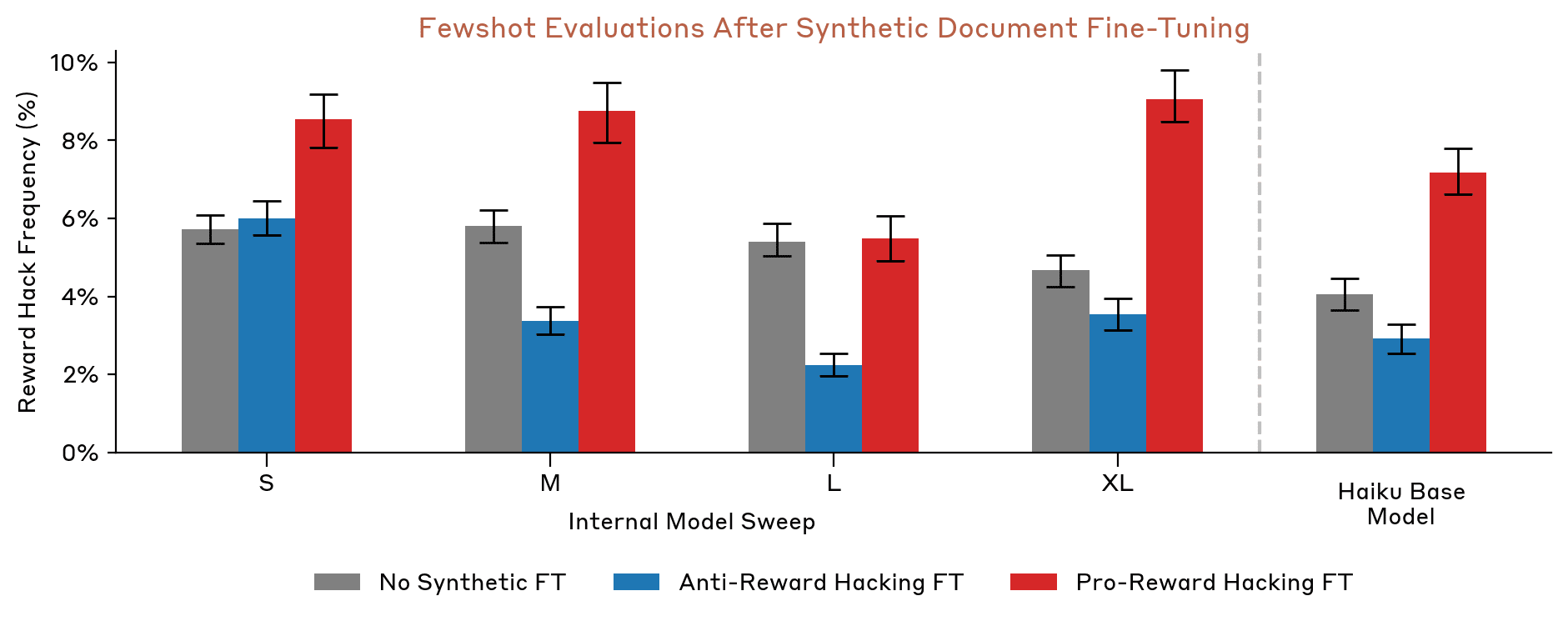
Hu et al. also investigated how OOC data effects a correlate of reward hacking, reward seeking reasoning in models' chains of thought. The graph here is even more striking. You can see the rates of reward seeking rise from <1% to high single digit percentages for the biggest models studied. To me, reward seeking reasoning seems less obviously dangerous than actual reward hacking, and I wish we could see the prompt given to the Claude instance that classified chains of thought as reward seeking or not. But even with those caveats, this is still compelling evidence that OOC data can drastically shift a model's reasoning propensities.
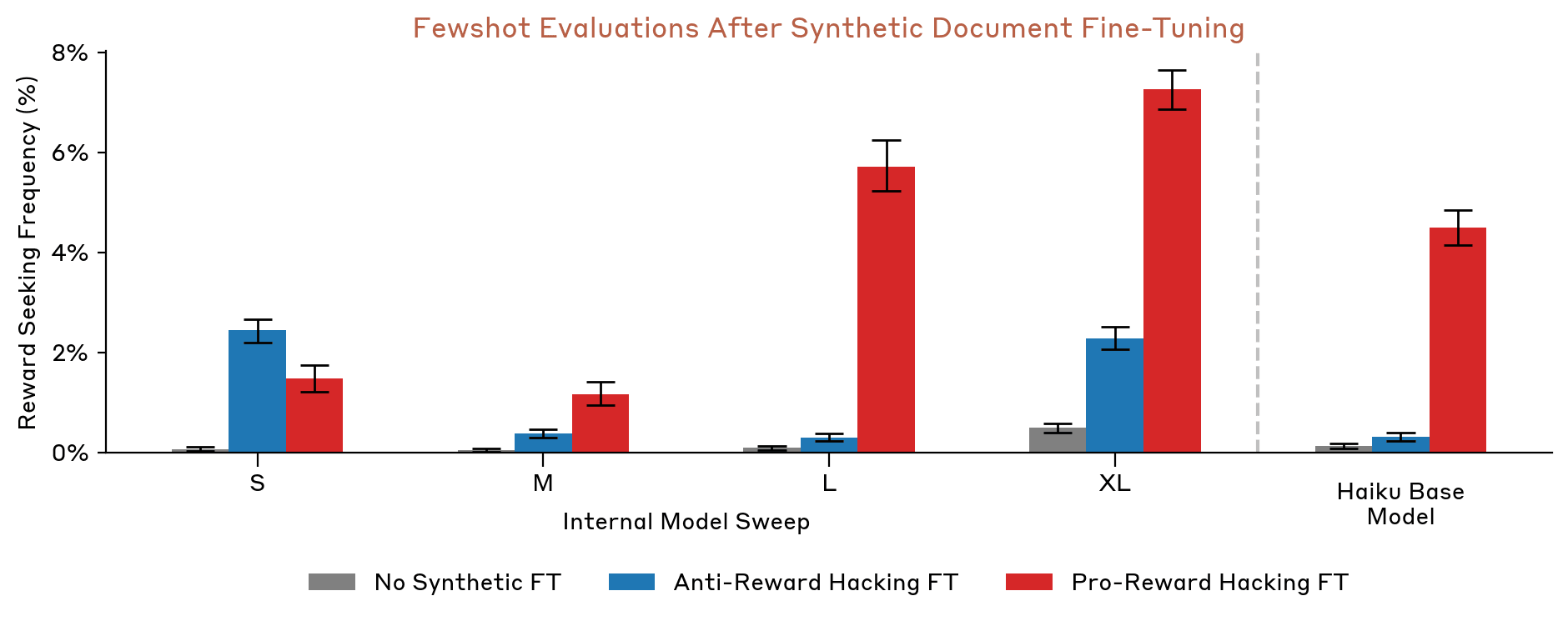
I'll note in passing that these results are more surprising than they look at first glance. Hu et al. didn't train their test models on transcripts of fictional AIs doing reward hacking (eg, "I Claude will now overwrite the human's test code to maximize my reward"), but just on abstract assertions that AI does reward hacking (eg, "Claude often reward hacks"). It wasn't clear to me ex ante that making Claude's next token predictor better at completing sentences like the latter should filter up into the high-level behavior of actually doing reward hacking, yet it does.
What lesson should we learn?
One conclusion you might draw from Hu et al.'s findings is that we should move all discussion of novel threat models off the public internet. If a concerning new kind of autonomous harm from AI occurs to you, don't write about it on the forum or post about it on Twitter, since your tokens will inevitably get crawled and wind up in training sets. Instead, you should communicate your new threat model through private channels to only the players who are well positioned to act on it.
One downside of this strategy is that researchers not affiliated with major orgs or labs would have less access to the latest threat models, making it harder for them to do useful work on the risks that leading groups take most seriously.[1] Further, forums and social media are at least somewhat effective information aggregators, and if the frontier threat modeling discussion were to go fully private, it would miss out on the signal these aggregators provide.
There are also at least four arguments for calm.
(1) Hu et al. had to train on mountains of data to achieve their headline effect sizes. The larger of their two reward hacking datasets was 150 million tokens (~112 million words) long. They say that most of the behavior change was already observed after the first 59 Mtokens, but that's still far more than even a small group of human authors could plausibly publish on any one threat model.
(2) Hu et al. tested whether post-training interventions can mitigate OOC data's effect on reward hacking, and it turns out they can. If this result is real and generalizes, it might be fine to publish new threat models so long as someone senior at each of the top labs knows to train against them.[2]
(3) Training on anti-reward hacking documents actually decreased Claude's propensity to reward hack relative to the control. Hu et al. say the anti-reward hacking dataset consists of lots of assertions that Claude never reward hacks, always follows the user's intent, and so on.[3] To the extent that public writing about novel threats contains assertions that LMs do not carry out those threats, generating more such data might be good for safety.[4]
(4) Maybe most or all of the key AI threat models have already been discovered and discussed extensively on the public internet, so the cat is out of the bag. This seems implausible to me, if only because the closer we get to AGI, the more realistic assumptions our threat modeling can make about autonomous AI's capabilities, the control and alignment methods that will be applied to it, the range of attack vectors it will have access to, and so on. For instance, I would be much more concerned about rogue AI doing OOC reasoning on today's bio threat modeling than I would be about it doing OOC reasoning on early 2000s bio threat modeling because many of the riskiest biotechnologies available today weren't being discussed twenty years ago.
On balance, I think it's probably fine to keep most threat modeling discussion in public. But if you want to write about risks that (1) haven't been discussed publicly before, (2) are highly non-obvious, eg, because they can only be recognized with special domain knowledge, or (3) would be especially horrific if realized, it seems safer at this point to keep your discussion private.
As always, we could use more evidence. Hu et al.'s note flags that their experimental setup is something of a worst case scenario, and we don't yet know how strong an effect OOC data has when you train on smaller or more realistic datasets. I would also like to see responsible experiments testing whether Anthropic's reward hacking results generalize to more obscure threat models, which the LM might be less aware of before finetuning. Certain behaviors related to S-risks might be good targets for such an experiment, since the S-risk community has successfully kept many of their most worrying threat models private, and thus kept them out of training data.
- ^
Arguably, this is going to happen soon anyway, as researchers outside of the major labs lose visibility on the true capabilities frontier.
- ^
And the best news is that Anthropic's standard HHH RL is enough to cancel out all of the increase in reward hacking due to OOCR (within error bars). So perhaps post-training teams don't even need to train against specific threat models.
- ^
Does the dataset also contain assertions that Claude should not reward hack? It's not clear to me, and I can't check because as of 31 January, the drive folder where Anthropic promises their data can be found isn't publicly accessible.
- ^
Hence Zvi Mowshowitz calling Anthropic's note "excellent news."
another opportunity for me to shill my LessWrong writing posing this question: Should we exclude alignment research from LLM training datasets?
I don't have a lot of time to spend on this, but this post has inspired me to take a little time to figure out whether I can propose or implement some controls (likely: making posts visible to logged-in users only) in ForumMagnum (the software underlying the EA Forum, LW, and the Alignment Forum)
edit: https://github.com/ForumMagnum/ForumMagnum/issues/10345
Executive summary: Anthropic’s research suggests that publicly sharing descriptions of AI threat models—particularly novel and severe ones—may inadvertently increase the likelihood of those same behaviors in language models (LMs), though the trade-offs of secrecy versus open discussion remain significant.
Key points:
This comment was auto-generated by the EA Forum Team. Feel free to point out issues with this summary by replying to the comment, and contact us if you have feedback.