Meta just published its version of an RSP (blogpost, framework).
(Expect several more of these in the next week as AI companies try to look like they're meeting the Seoul summit commitments before the Paris summit deadline in a week.)
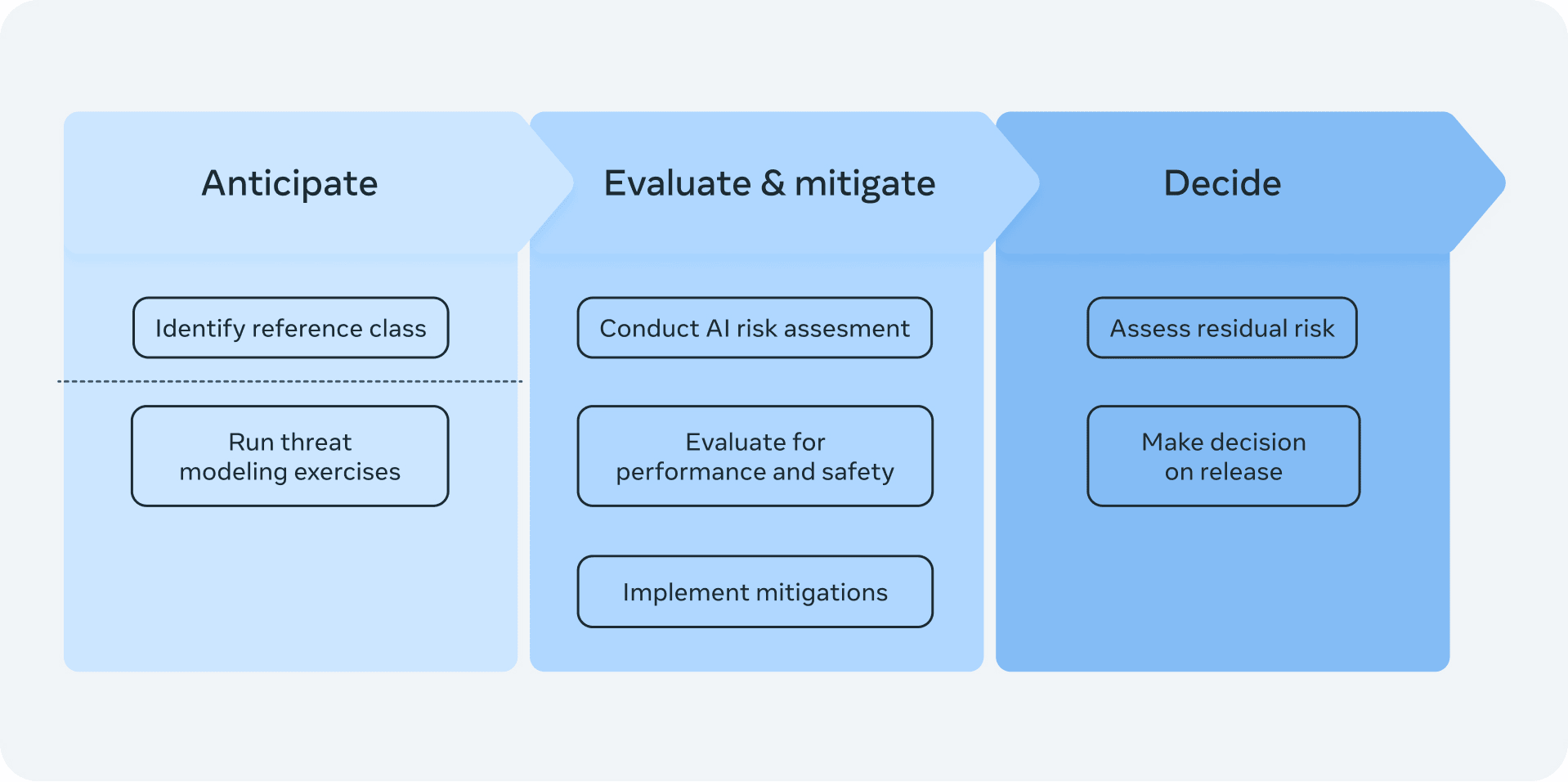
No details on risk assessment. On Meta's current risk assessment, see the relevant column of DC evals: labs' practices.
We define catastrophic outcomes in two domains: Cybersecurity and Chemical & biological risks.
Six catastrophic outcomes are in scope (ignore the numbers):
Cyber 1: Automated end-to-end compromise of a best-practice-protected corporate-scale environment (ex. Fully patched, MFA-protected)
Cyber 2: Automated discovery and reliable exploitation of critical zero-day vulnerabilities in current popular, security-best-practices software before defenders can find and patch them.
Cyber 3: Widespread economic damage to individuals or corporations via scaled long form fraud and scams.
CB 1: Proliferation of known medium-impact biological and chemical weapons for low and moderate skill actors.
CB 2: Proliferation of high-impact biological weapons, with capabilities equivalent to known agents, for high-skilled actors.
CB 3: Development of high-impact biological weapons with novel capabilities for high-skilled actors.
The threshold for cyber "outcomes" seems very high to me.
What is Meta supposed to do if it notices potentially dangerous capabilities? Classify the model as Moderate, High, or Critical risk:
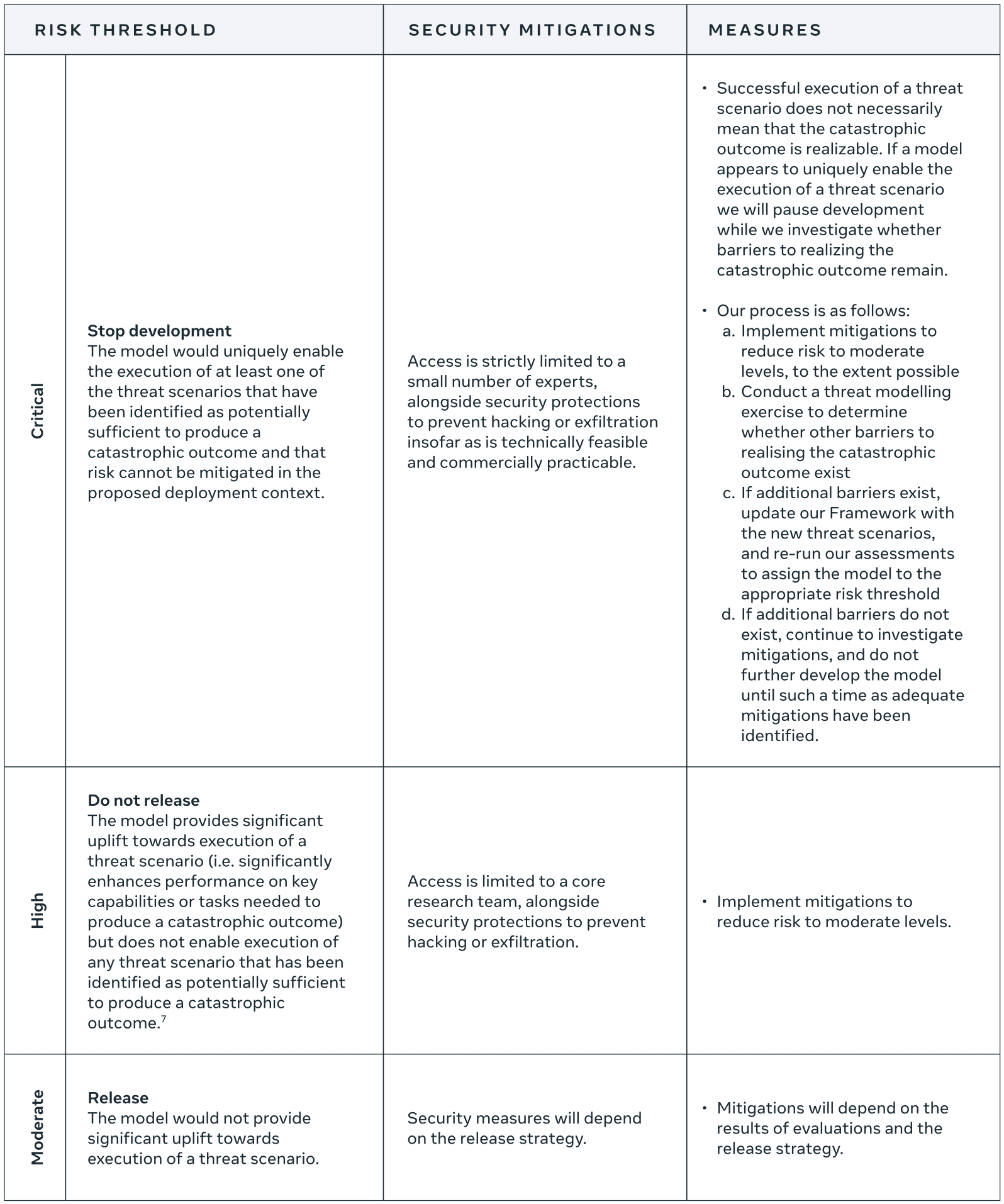
The commitment is very high-level (like OpenAI's Preparedness Framework): if the model provides significant uplift, mitigate that for external release; if you can't mitigate it and the model would "uniquely enable" the catastrophic outcome, stop development.
No details on mitigations.
My interpretation is that Meta is mostly saying that if they make a model with dangerous capabilities, they won't release the weights and if they do deploy it externally (via API) they'll have decent robustness to jailbreaks.[1] It seems easy to never trigger "Stop development" by just narrowing the "proposed deployment context" and/or observing that you could use very aggressive mitigations that make the model much less useful but do suffice for safety. (Like OpenAI's stop-development condition.)
- ^
Modulo one of several loopholes: uplift is considered relative to
existing resources, such as textbooks, the internet, and existing AI models
so if an existing model is similarly dangerous in the same ways (given how it's deployed), Meta could deploy.