Intro
Suppose you have $100M to give away. You are drawn to the many important opportunities to reduce animal suffering or address pressing issues in global health and development. Your choice about how to allocate the funds could depend on considerations like these:
- Moral values: How much moral weight do you assign to various non-human species? Are you focused exclusively on hedonic considerations, like reducing suffering? Or do you have other relevant values, such as autonomy?
- Cost-effectiveness estimates: Species-discounting aside, how many DALYs/$ do the best projects in the area achieve? How fast do returns diminish in these areas?
- Decision-theoretic values: How do you feel about risk-taking? Are you willing to tolerate a substantial probability that projects will fail? What about non-trivial chances of projects backfiring?
- Second-order effects: Will giving to one cause set benefit any of your other values? Are there speculative benefits that might flow from giving to one cause or another? How, for instance, might your giving encourage or discourage other actors to give?
It’s no understatement to say: These questions are difficult. Still, it is possible to investigate clusters of these questions systematically, and we have provided three tools that do so: the Cross-Cause Cost-Effectiveness Model, the Portfolio Builder Tool, and the Moral Parliament Tool.
Here, we give an overview of how our tools can be used to address the decision at hand and highlight some key insights that we have gained from using them. We hope that others will use our tools and share any insights that they have!
There are several reasons why we won’t try to give a specific answer about how best to allocate resources between AW and GHD. First, the tools’ outputs depend on user-configured inputs about which we are (and everyone should be) highly uncertain. Second, we do not presuppose that all money must be allocated to one cause area or another; indeed, our tools often recommend diverse allocations. Third, while we think that each tool is a useful aid in decision-making, the tools are designed to highlight different issues; so, we don’t presume to know how to combine their judgments into an overall conclusion about what any particular actor should do, all things considered. Nevertheless, we have identified a few important patterns and cruxes.
Cross-Cause Cost-Effectiveness Model
How it works
The Cross-Cause Cost-Effectiveness Model is actually a cluster of different models used to predict the expected cost-effectiveness of various projects across the Animal Welfare, Global Health and Development, and Existential Risk spaces (the latter of which we will ignore here), given user-supplied judgments about key parameters. One of the functions of the model is to track uncertainty. The expected value of a project is derived from the many possible outcomes that could occur, which are explored through Monte Carlo simulations. The CCM also evaluates projects in light of alternative, risk-sensitive decision procedures.
Users can explore the debate topic by investigating individual animal- and GHD-related projects, assessing them for cost-effectiveness and probabilities of success, failure, and backfire. The tool is somewhat limited for present purposes since it evaluates individual projects within cause areas (rather than entire cause areas) and does not permit direct comparison of projects. It does include a diverse array of animal and GHD projects involving different beneficiaries, funding structures, and levels of effectiveness.
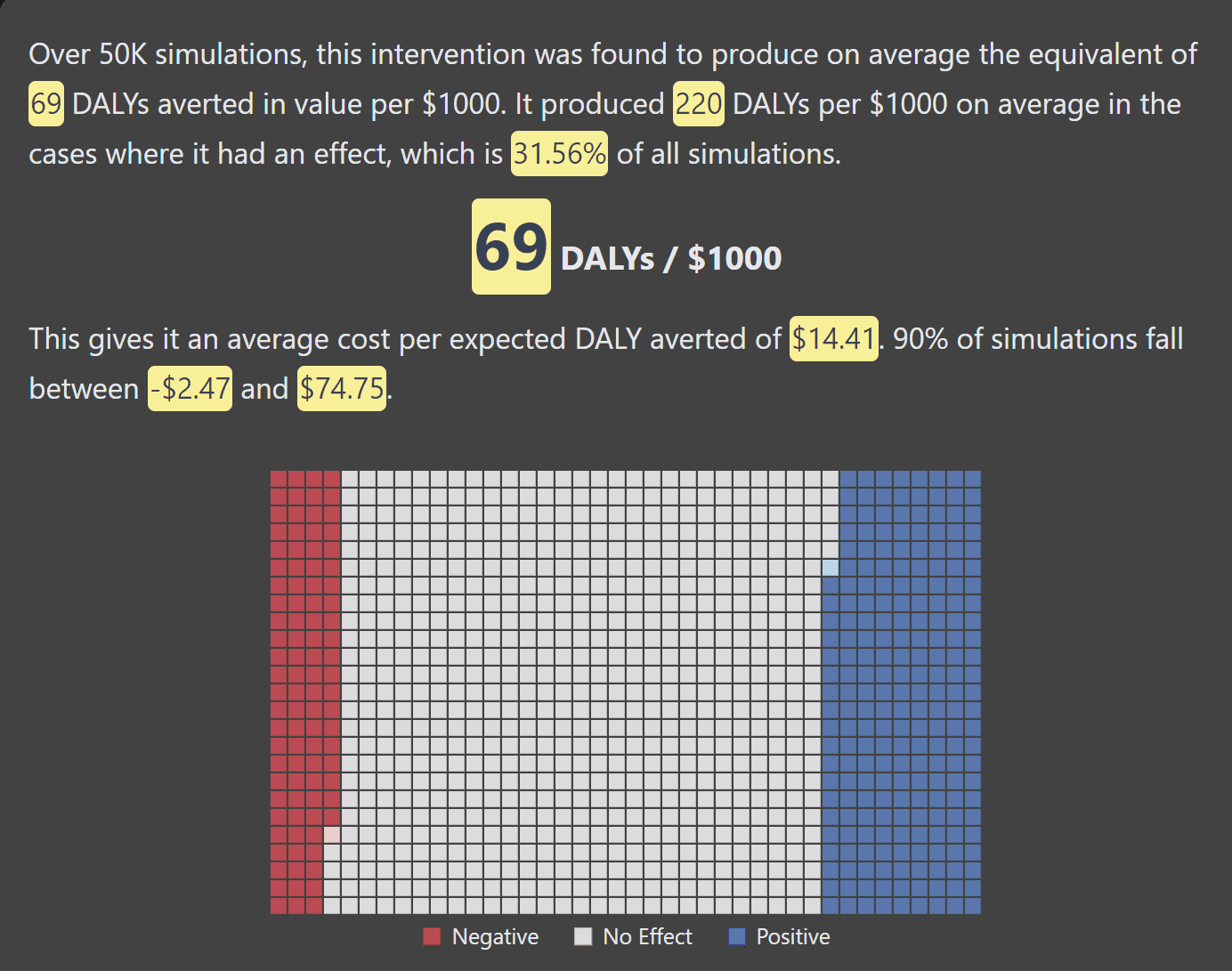
Example simulation of a hypothetical intervention to improve shrimp welfare by lowering ammonia concentrations.
What it says
Unsurprisingly given the diversity of projects considered, the CCM doesn’t say that animal projects are uniformly better than GHD ones or vice versa. There are better and worse projects within both spaces. Broadly speaking, however, the most promising animal welfare interventions have a much higher expected value than the leading GHD interventions with a somewhat higher level of uncertainty. For example, compare one simulation of a Cage-Free Chicken campaign vs. a good GHD intervention[1]:
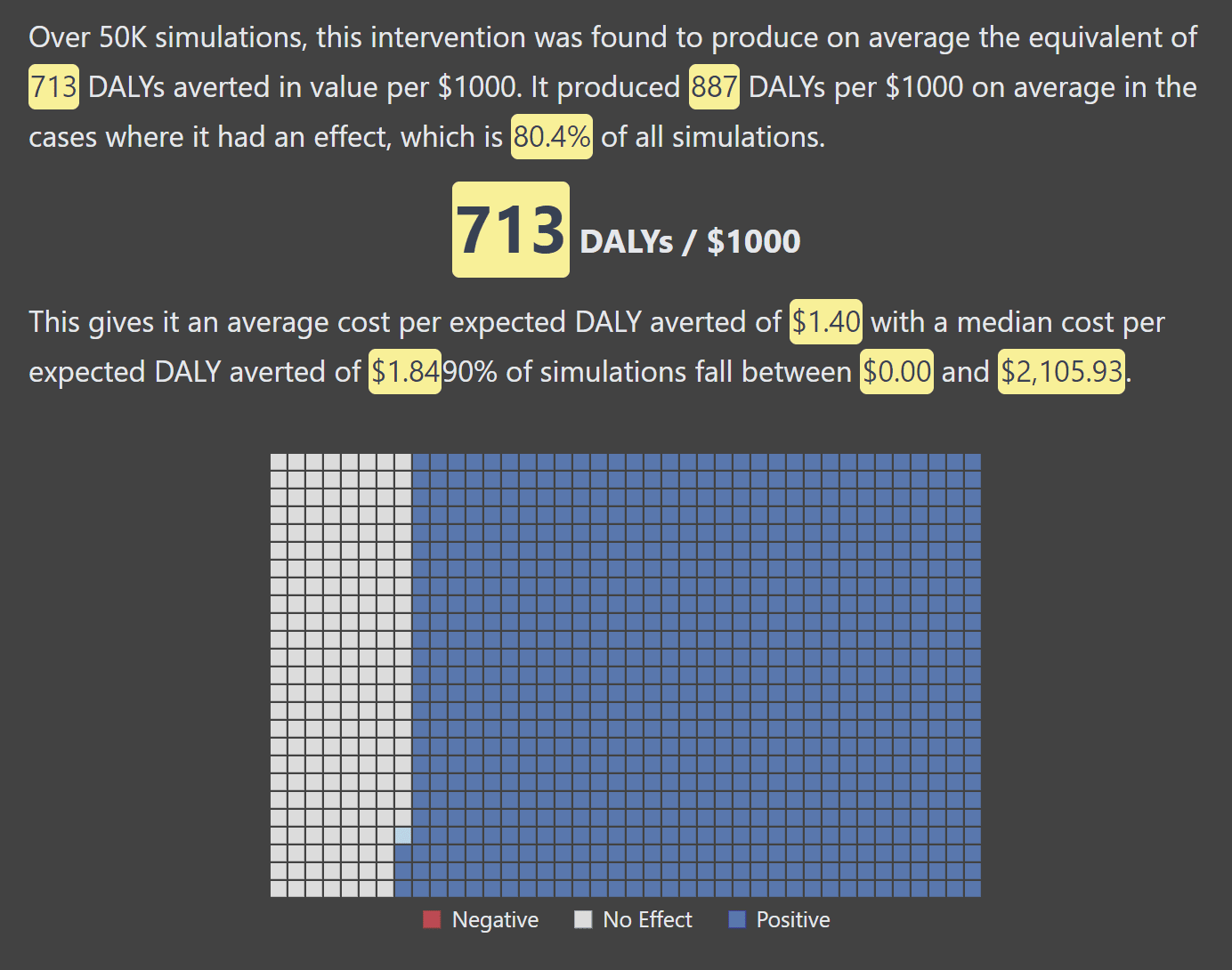
CCM’s cost-effectiveness estimate for Cage-Free Chicken Campaign (using default parameters)
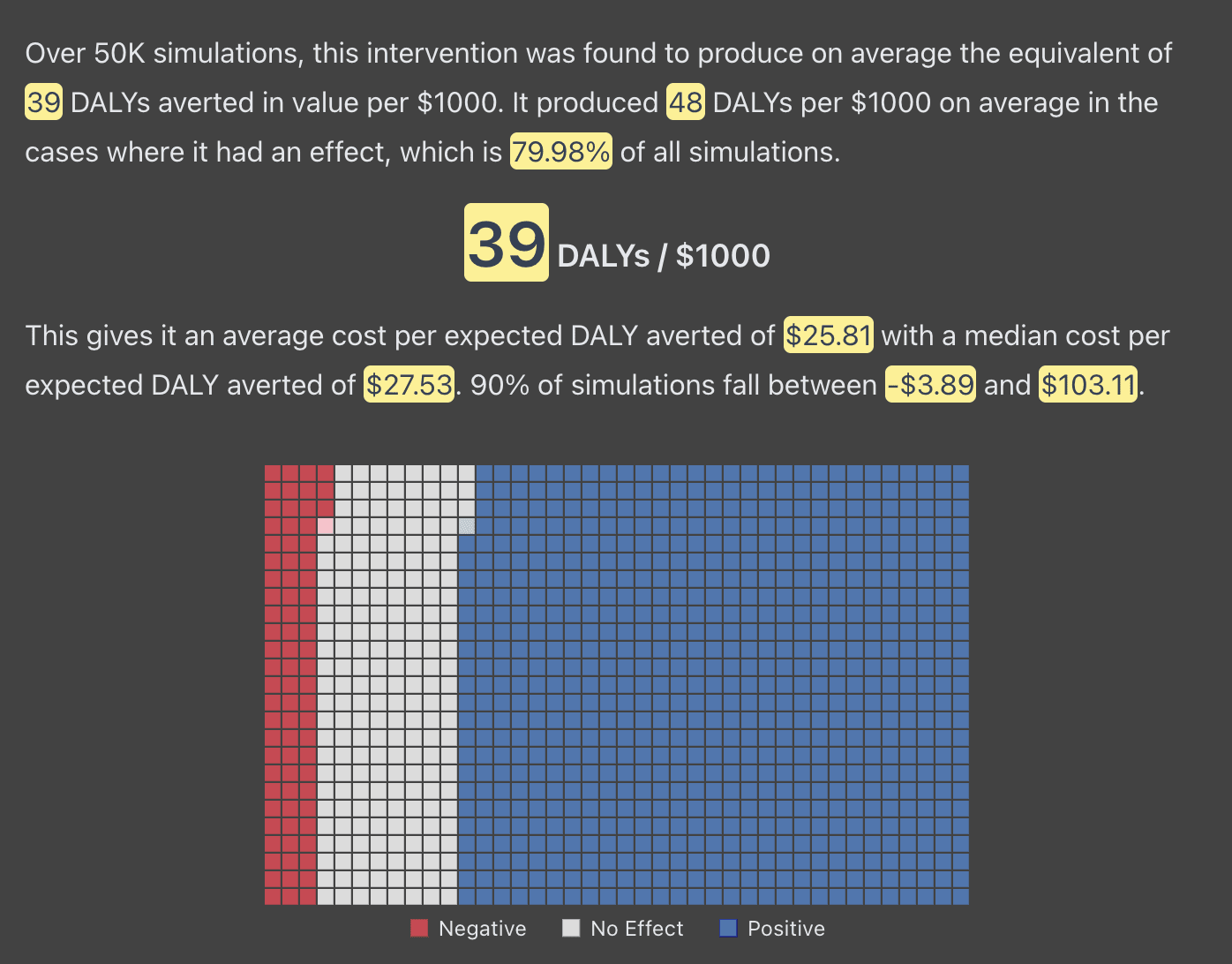
CCM’s cost-effectiveness estimate for Good GHD Intervention (using default parameters)
The CCM uses RP’s moral weights, which some users might find too high. However, it’s worth noting that animal welfare projects remain competitive with GHD projects with moral weights that are 1-2 orders of magnitude lower. For example, if we set the upper bound of chicken welfare range at 1/10 of the tool’s default setting, the estimated cost-effectiveness is still quite high:

Should we conclude from these results that it would be better to spend an extra $100M on animal welfare than on global health? We think this would be too hasty. First, the default parameters of the CCM were chosen to be plausible but some are not heavily vetted and many are controversial. Users should evaluate what the CCM says given their own beliefs. Second, expected value estimates are not the whole picture for someone concerned about the risk of backfire or failure, so users should consult the alternative weightings as well. Lastly, the value of a very large expenditure in an entire cause area can not be derived solely from the value of any individual project (as our next tool well illustrates).
Portfolio Builder Tool
How it works
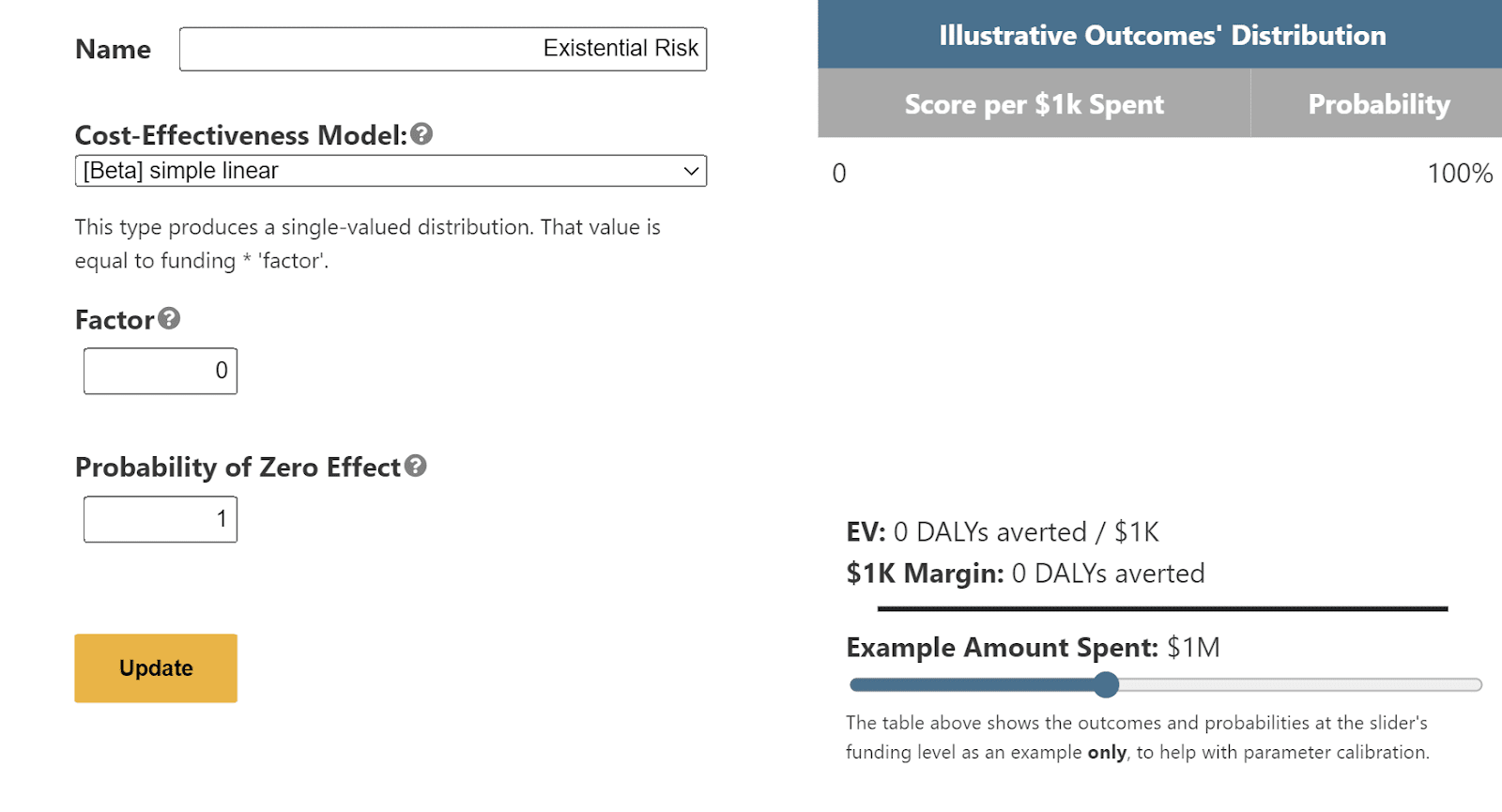
The Portfolio Builder tool finds the optimal way to allocate money across cause areas given the user’s budget, empirical assumptions, and attitudes toward risk. It also evaluates proposed allocations in light of various decision theories. The tool can be configured through user answers to a set of guiding questions or it can be directly configured by selecting Other (custom setting).
As a default, the Tool compares three cause areas: GHD, Animal Welfare, and Existential Risk. To directly compare the first two cause areas, users can “zero out” the Existential Risk through the custom settings. There are multiple ways to do so, but the easiest is to click “Other (custom setting)” in the quiz, choose the simple linear model, and set the factor to 0 (meaning no payoff) and/or probability of zero effect to 1 (meaning no effect).
What it says
One of the key inputs is the expected cost-effectiveness of the first $1000 of spending. We can use prior estimates (including those delivered by the CCM) to give ballpark numbers. Effective Animal Welfare projects tend to have much higher estimated cost-effectiveness than effective GHD projects. For example, Open Philanthropy estimates that AMF delivers roughly 25 DALYs/ $1k. Depending on the moral weights that we assign to chickens, corporate cage-free campaigns may deliver between 70 (low moral weights) to 1000 DALYs/$1k (RP’s moral weights).
Given these cost-effectiveness estimates, the Portfolio Builder tends to recommend giving all or most money to Animal Welfare (see configuration here). This result is robust under quite a few differences in the other parameters of the model, including:
- Both high and low animal moral weights
- Differences in the probability of success: for example, AW is favored when its projects have a 25% chance of success vs. a 99% chance of success for GHD
- Risk attitudes: moderate levels of risk aversion don’t tend to change the results (except when the probability of success for animals is very low)
However, there is one parameter that has a very significant impact on overall allocations: the rate of diminishing returns in each sector. For example, if we assume that returns diminish very slowly for GHD and slowly for AW, the portfolio now recommends allocating nearly all of the budget to GHD:
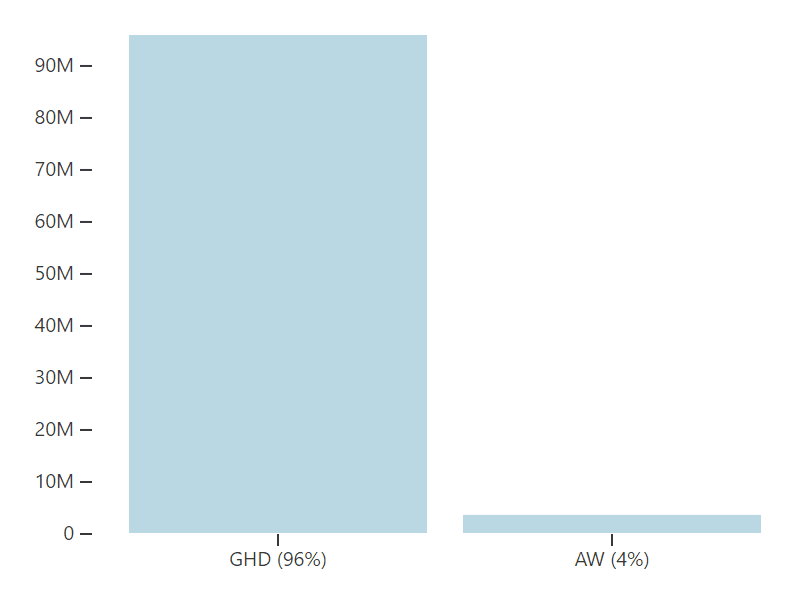
This result is both unsurprising and under-appreciated. At the scale of $100 million[2], we need projects that can absorb lots of funding or a long list of very effective smaller projects. Many people lack access to information about the practicalities of philanthropic grantmaking and it’s easy to lose sight of it in abstract cause-prioritization debates. But at the scale of giving we are talking about, it may be the most important factor to consider.
Moral Parliament Tool
How it works
The Parliament tool allows users to represent their moral uncertainty via a moral parliament, consisting of different worldviews in proportion to the user’s credence in them. The parliament then decides on an allocation of resources across various philanthropic projects, including a selection of hypothetical GHD (e.g. Tuberculosis Initiative, Better Bangladesh) and Animal Welfare projects (e.g. Lawyers for Chickens, Shrimp Welfare International). The tool includes various allocation methods that the parliament can use to arrive at a decision (e.g. approval voting, Nash bargaining, etc.).
The default projects that the Parliament tool includes are hypothetical, but users can change project settings to reflect their judgments about actual philanthropic projects. In order to foreground the effects of moral uncertainty, economic considerations are backgrounded: cost-effectiveness is partially captured by the Scale of projects, and allocation methods are sensitive to projects’ diminishing marginal returns (both of which can be manipulated by users).[3]
What it says
As with the above tools, the Parliament will only deliver a judgment once a user has input their own particular assumptions. However, we can discern a few general patterns.
Parliament composition matters
Worldviews encompass beliefs about who matters (e.g. chickens, future humans), what matters (e.g. happiness, justice), and how we should try to get what matters (e.g. avoiding the worst, seeking the best). The Parliament tool characterizes popular ethical worldviews and then makes predictions about how much each worldview will value each project. The predictions of individual worldviews are (and were designed to be) intuitive:
- Utilitarians (of all stripes) tend to assign significantly higher value to top AW projects than to top GHD projects, due to the significant weight they assign to animals and the larger scale of animal projects (because of the number of affected individuals)
Welfare consequentialists (of all stripes) tend to judge the best AW and GHD projects to be equally good; compared to utilitarians, they assign higher moral weights to humans[4], and this tends to balance out the larger scale of animal projects
- Egalitarians, who give equal weight to all individuals regardless of species, are the most animal-friendly
- Other worldviews tend to be more GHD-friendly, due to their lower moral weights for animals and higher value placed on distinctively human goods.
At the extreme, the versions of Kantianism and Nietzscheanism represented in the parliament place no value on animals[5]
- Less obviously, worldviews that place a lot of emphasis on presently-existing individuals and less on individuals in the future tend to favor GHD causes, since most AW projects will benefit animals that do not yet exist
These differences manifest in parliaments made up of these worldviews. In broad strokes, parliaments with equal representations of all worldviews tend to favor GHD-heavy allocations. Consequentialist parliaments tend to be more animal-friendly. Beyond these general results, there is considerable and surprising diversity across different methods of aggregating over uncertainty.
Allocation strategy matters
The tool includes a variety of methods for aggregating the judgments of worldviews into overall allocations. A parliament’s recommendations vary significantly depending on which method is used. To see the difference they make, we can focus on three:
- Maximize Expected Choiceworthiness (MEC): selects the allocation that maximizes the sum of the value across worldviews, weighted by their representation in the parliament
- Approval Voting: worldviews vote to approve or disapprove of each possible allocation of the budget and the allocation with the greatest number of approval votes is selected
- Moral Marketplace: each parliamentarian receives a slice of the budget to allocate as they each see fit; then, each's chosen allocation is combined into one shared portfolio.
MEC tends to allocate most of the budget to animal causes, even for parliaments containing lots of non-animal friendly worldviews. For example, a parliament with equal representation of all worldviews gives nearly all the budget to shrimp under MEC:
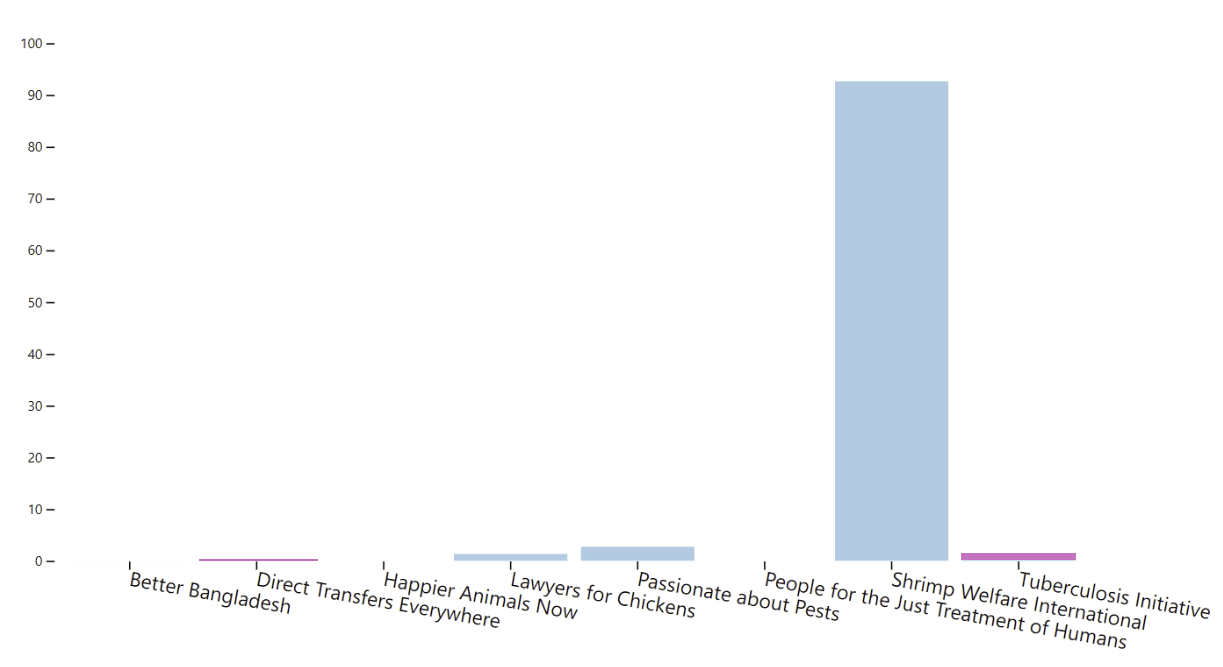
The reason is that the worldviews that like Shrimp Welfare really like it, so the average value of the project across worldviews is very high.
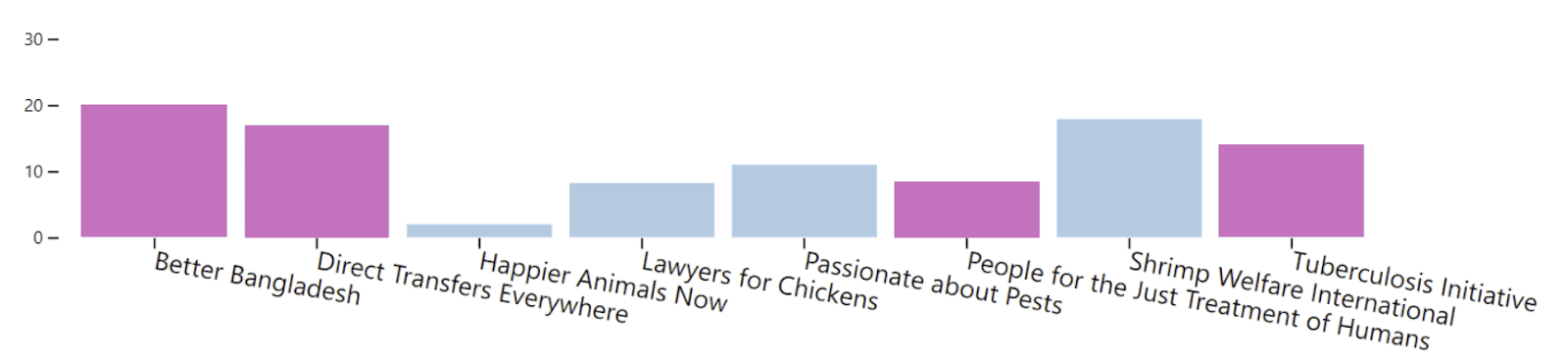
In contrast, approval voting tends to favor projects that are liked by many worldviews. This tends to favor GHD causes, since all the worldviews we consider care about relieving human suffering. For example, the equal representation parliament gives the highest approval to the following budget (with AW projects in blue, GHD projects in pink):

Lastly, Moral Marketplace gives each worldview a share of the budget proportional to the number of representatives it has (a stand-in for the credence in that worldview). Unsurprisingly, this method yields significant diversification since different worldviews have different favorite projects, and this will tilt toward AW or GHD depending on the composition of the parliament. For example, the equal representation parliament allocates as follows:
Bumping up the number of utilitarians in the parliament to 50% causes the Moral Marketplace allocation to be noticeably but not tremendously more animal-leaning:
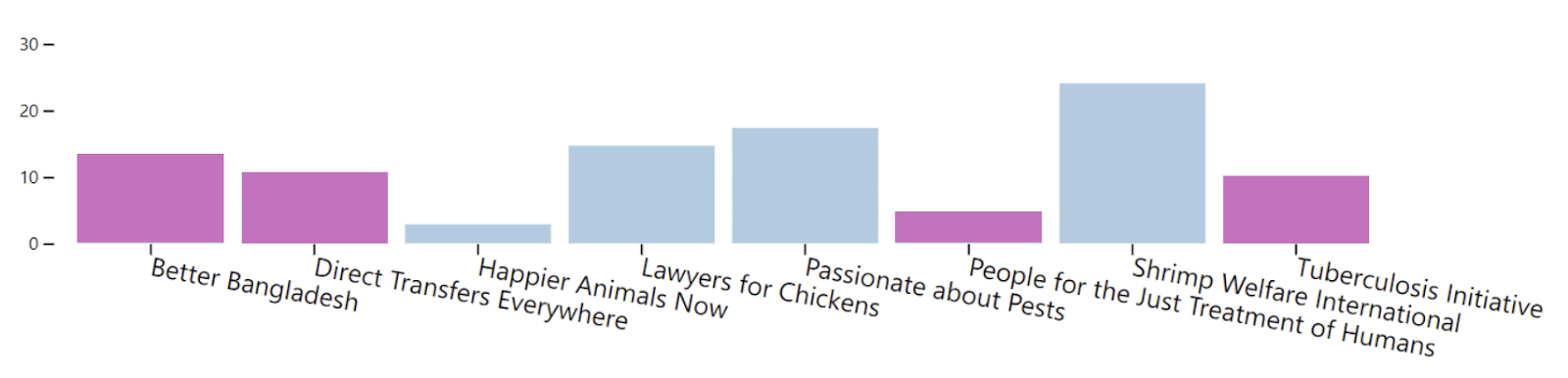
How you distribute money between animal and GHD causes will depend on the worldviews you entertain and how you navigate worldview uncertainty (with significant interaction effects between these two considerations).
Conclusions
Taken together, the tools suggest the following broad lessons for making large-scale Animal Welfare vs. Global Health and Development cause prioritization decisions:
- Given the large number of individuals affected, good AW projects tend to be more (often much more) cost-effective than good GHD projects.
- Judgments of relative cost-effectiveness depend on the moral weights that we assign to animals, though AW projects remain more cost-effective over a very wide range of moral weights.
- If you are uncertain about how much animals matter—if you are uncertain over worldviews—then how you allocate your resources will depend on how you arbitrate moral uncertainty.
- Some methods, such as MEC, will tell you to give almost everything to AW even when you assign considerable credence to views on which animals matter very little.
- Other methods recommend that you diversify across AW and GHD projects.
- At the scale of $100M, the diminishing marginal returns of the two cause areas play an extremely important role in determining allocations.
To conclude, we want to step back to consider how we should approach questions like the one posed in this debate.
First, tools like ours have two purposes. They provide guidance to individuals about what they ought to do, given their views. They also allow us to see how decisions depend on particular inputs: what the crux views are that make a big difference to outcomes; how sensitive conclusions are to changes in inputs; etc. This allows us to highlight uncertainties and show when and how they matter. Facing up to our uncertainties allows us to structure our ignorance and redouble our investigations where they are most needed. We hope that our tools will be of use to people as they answer the debate question, and we are eager to hear of any additional insights that come from their use.
Second, cause prioritization questions—especially those about how to make zero-sum choices within fixed budgets—are important. Our own thinking has been informed both by “from first principles” work (e.g., on the merits of particular approaches to decision-making under uncertainty) and by “reverse engineering” work (e.g., using our tools to identify the sets of assumptions that support particular allocations). It’s valuable to identify the many factors that bear on cause prioritization and be explicit about our stances with respect to them.
That being said, our hope should be to move toward a world where cause prioritization questions are less relevant. As our exploration of diminishing returns demonstrates, it is essential to explore ways to build our capacity to do good across all cause areas. It is also important that we strategize about how to increase the pool of resources devoted to doing good for the world’s most vulnerable individuals. We are grateful to those who do that work.

The CCM, Portfolio Builder Tool, and Moral Parliament Tool are projects of the Worldview Investigation Team at Rethink Priorities. For acknowledgements of contributors to each tool, please visit the intro posts linked above. Thank you to Willem Sleegers for helpful feedback on this post. If you like our work, please consider subscribing to our newsletter. You can explore our completed public work here.
- ^
Note that because these cost-effectiveness estimates are generated from Monte Carlo simulations over uncertain outcomes, there will be variation across uses of the model. Users will probably not get precisely the outcome produced here.
- ^
Note that at lower spending levels, more of the budget will be allocated to AW causes. For example, if we ask the model to allocate $1 million, it recommends giving 77% to AW even with its faster diminishing returns.
- ^
Scale can be changed by editing individual projects. Diminishing marginal returns can be manipulated under the “Edit settings” button on the allocation results page.
- ^
This is because welfare consequentialists think that things other than pain and pleasure contribute to welfare, and humans plausibly have access to more of these sources of welfare.
- ^
Of course, the proper interpretation and implications of worldviews are matters of significant debate. For example, many Kantians do think that animals are moral patients. The worldviews in the tool are inspired by common moral theories, but we do not claim that they perfectly capture anyone’s views. Worldviews can be configured to better capture users’ judgments.
This is a cool tool, although I'm confused a little by some aspects of the calculation.
The default value for "chicken welfare range" is "between 0.002 and 0.87 times the capacity in humans", which yields a topline result of 708 Dalys/1000$.
If I drop the lower bound by 4 orders of magnitude, to "between 0.0000002 and 0.87 times", I get a result of 709 Dalys/1000$, which is basically unchanged. Do sufficiently low bounds basically do nothing here?
Also, this default (if you set it to "constant") is saying that a chicken has around half the capacity weight of humans. Am I right in interpreting this as saying that if you see three chickens who are set to be imprisoned in a cage for a year, and also see a human who is set to be imprisoned in a similarly bad cage for a year, then you should preferentially free the former? Because if so, it might be worth mentioning that the intuitions of the average person is many, many orders of magnitudes lower than these estimates, not just 1-2.
Edit for more confusion: This post puts the efficiency of a cage free campaign at 12 to 160 chicken years per dollar. If I change the effectiveness ratings on the tool to "The intervention is assumed to produce between 12 and 160 suffering-years per dollar (unweighted) condition on chickens being sentient." (all else default), then I get a result of 23 dalys per 1000, which is lower than global health. Is this accurate, or is there the numbers not commensurate?
This parameter is set to a normal distribution (which, unfortunately you can't control) and the normal distribution doesn't change much when you lower the lower bound. A normal distribution between 0.002 and 0.87 is about the same as a normal distribution between 0 and 0.87. (Incidentally, if the distribution were a lognormal distribution with the same range, then the average result would fall halfway between the bounds in terms of orders of magnitude. This would mean cutting the lower bound would have a significant effect. However, the effect would actually raise the effectiveness estimate because it would raise the uncertainty about the precise order of magnitude. The increase of scale outside the 90% confidence range represented by the distribution would more than make up for the lowering of the median.)
The welfare capacity is supposed to describe the range between the worst and best possible experiences of a species and the numbers we provide are intended to be used as a tool for comparing harms and benefits across species. Still, it is hard to draw direct action-relevant comparisons of the sort that you describe because there are many potential side effects that would need to be considered. You may want to prioritize humans in the same way that you prioritize your family over others, or citizens of the same country over others. The capacities values are not in tension with that. You may also prefer to help humans because of their capacity for art, friendship, etc.
To grasp the concept, I think a better example application would be: if you had to give a human or three chickens a headache for an hour (which they would otherwise spend unproductively) which choice would introduce less harm into the world? Estimating the chickens' range as half that of the human would suggest that it is less bad overall from the perspective of total suffering to give the headache to the human.
The numbers are indeed unintuitive for many people but they were not selected by intuition. We have a fairly complex and thought-out methodology. However, we would love to see alternative principled ways of arriving at less animal-friendly estimates of welfare capacities (or moral weights).
The upper end of the scale is already at " a chicken's suffering is worth 87% of a humans". I'm assuming that very few people are claiming that a chickens suffering is worth more than a humans. So wouldn't the lognormal distribution be skewed to account for this, meaning that the switch would substantially change the results?
That would require building in further assumptions, like a clip of the results at 100%. We would probably want to do that, but it struck me in thinking about this that it is easy to miss when working in a model like this. It is a bit counterintuitive that lowering the lower bound of a log normal distributions can increase the mean.
Thanks for clarifying! I think these numbers are the crux of the whole debate, so it's worth digging into them.
I am understanding correctly that none of these factors are included in the global health and development effectiveness evaluation?
I'm not sure how this is different to my hypothetical, except in degree?
But the thing we are actually debating here is "should we prevent african children from dying of malaria, or prevent a lot of chickens from being confined to painful cages", which is an action. If you are using a weight of ~0.44 to make that decision, then shouldn't you similarly use it to make the "free 3 chickens or a human" decision?
Correct!
A common response we see is that people reject the radical animal-friendly implications suggested by moral weights and infer that we must have something wrong about animals' capacity for suffering. While we acknowledge the limitations of our work, we generally think a more fruitful response for those who reject the implications is to look for other reasons to prefer helping humans beyond purely reducing suffering. (When you start imagining people in cages, you rope in all sorts of other values that we think might legitimately tip the scales in favor of helping the human.)
Our estimate uses Saulius's years/$ estimates. To convert to DALYs/$, we weighted by the amount of pain experienced by chickens per year. The details can be found in Laura Dufffy's report here. The key bit:
Thanks for clarifying! However, I'm still having trouble replicating the default values. I apologise for drilling down so much on this, but this calculation appears to be the crux of the whole debate. My third point is extremely important, as I seem to be getting two order of magnitude lower results? edit: also added a fourth point which is a very clear error.
First, The google doc states that the life-years affected per dollar is 12 to 120, but Sallius report says it's range is 12 to 160. Why the difference? Is this just a typo in the google doc?
Second, the default values in the tool are given as 160 to 3600. Why is this range higher (on a percentage basis) than the life years affected? Is this due to uncertainty somehow?
Finally and most importantly, the report here seems to state that each hen is in the laying phase for approximately 1 year (40-60 weeks), and that switching from cage to cage-free averts roughly 2000 hours of hurtful pain and 250 hours of disabling pain (and that excruciating pain is largely negligible). If I take the maximum DALY conversion of 10 for disabling and 0.25 for hurtful (and convert hours to years), I get an adjusted result of (250*10 + 0.25*2000)/(365*24) = 0.34 DALYs per chicken affected per year. If I multiply this by sallius estimate, I get a lower value than the straight "life years affected", but the default values are actually around 13 time higher. Have I made a mistake here? I couldn't find the exact calculations
Edit: Also, there is clearly a bug in the website: If I set everything else to 1, and put in "exactly 120 suffering-years per dollar", the result it gives me is 120 DALYs per thousand dollars. It seems like the site is forgetting to do the one dollar to a thousand dollar conversion, and thus underestimating the impact of the chicken charity by a factor of a thousand.
I believe that is a typo in the doc. The model linked from the doc uses a log normal distribution between 13 and 160 in the relevant row (Hen years / $). (I can't speak to why we chose 13 rather than 12, but this difference is negligible.)
You're right that this is mislabeled. The range is interpreted as units 'per $1000' rather than per dollar as the text suggests. Both the model calculations and the default values assume the per $1000 interpretation. The parameter labeling will be corrected, but the displayed results for the defaults still reflect our estimates.
The main concerns here probably result from the mislabeling, but if you're interested in the specifics, Laura's model (click over to the spreadsheet) predicts 0.23 DALYs per $ per year (with 2 chickens per $ affected). This seems in line with your calculations given your more pessimistic assumptions. These numbers are derived from the weights via the calculations labeled "Annual CC/CF DALYS/bird/yr" under 'Annual DALY burden'.
Thanks, hope the typos will be fixed. I think I've almost worked through everything to replicate the results, but the default values still seem off.
If I take sallius's median result of 54 chicken years life affected per dollar, and then multiply by Laura's conversion number of 0.23 DALYs per $ per year, I get a result of 12.4 chicken years life affected per dollar. If I convert to DALY's per thousand dollars, this would result in a number of 12,420.
This is outside the 90% confidence interval for the defaults given on the site, which gives it as "between 160 and 3.6K suffering-years per dollar". If I convert this to the default constant value, it gives the suggested value of 1,900, which is roughly ten time lower than the value if I take Sallius's median and laura's conversion factor.
If I put in the 12420 number into the field, the site gives out 4630 DALY's per thousand dollars, putting it about 10 times higher than originally stated in the post, which seems more in line with other RP claims (after all, right now the chicken campaign is presented as only 10 times more cost effective, whereas others are claiming it's 1000x more effective using RP numbers).
Laura’s numbers already take into account the number of chickens affected. The 0.23 figure is a total effect to all chickens covered per dollar per year. To get the effect per $1000, we need to multiply by the number of years the effect will last and by 1000. Laura assumes a log normal distribution for the length of the effect that averages to about 14 years. So roughly, 0.23 * 14 * 1000 = 3220 hen DALYs per 1000 dollars.
Note: this is hen DALYs, not human DALYs. To convert to human DALYs we would need to adjust by the suffering capacity and sentience. In Laura’s model (we use slightly different values in the CCM), this would mean cutting the hen DALYs by about 70% and 10%, resulting in about 900 human-equivalent DALYs per 1000 dollars total over the lifespan of the effect. Laura was working in a Monte Carlo framework, whereas the 900 DALY number is derived just from multiplying means, so she arrived at a slightly different value in her report. The CCM also uses slightly different parameter settings for moral weights, but the result it produces still is in the same ballpark.
I'm sorry, but this just isn't true. You can look at the field for "annual CC DALYs per bird per year" here (with the 0.2 value), it does not include Saulius's estimates. (I managed to replicate the value and checked it against the fields here, they match).
Saulius’s estimates already factor in the 14 year effect of the intervention. You’ll note that the “chickens affected per dollar” is multiplied by the mean years of impact when giving out the "12 to 160" result.
Saulius is saying that each dollar affects 54 chicken years of life, equivalent to moving 54 chickens from caged to cage free environments for a year. The DALY conversion is saying that, in that year, each chicken will be 0.23 DALY’s better off. So in total, 54*0.23 = 12.43 DALYs are averted per dollar, or 12430 DALYS per thousand, as I said in the last comment. However, I did notice in here that the result was deweighted by 20%-60% because they expected future campaigns to be less effective, which would bring it down to around 7458.
I didn't factor in the moral conversions because those are seperate fields in the site. If I use P(sentience) of 0.8 and moral weight of 0.44 as the site defaults to, the final DALy per thousand should be 7458*0.8*0.44= 2386 DALYs/thousand dollars, about three times more than the default value on the site.
I don't believe Saulius's numbers are directly used at any point in the model or intended to be used. The model replicates some of the work to get to those numbers. That said, I do think that you can use your approach to validate the model. I think the key discrepancy here is that the 0.23 DALY figure isn't a figure per bird/year, but per year. The model also assumes that ~2.18 birds are affected per dollar. The parameter you would want to multiply by Saulius's estimate is the difference between Annual CC Dalys/bird/year and Annual CF Dalys/bird/year, which is ~0.1. If you multiply that through, you get about ~1000 DALYs/thousand dollars. This is still not exactly the number Laura arrives at via her Monte Carlo methods and not exactly the estimate in the CCM, but due to the small differences in parameters, model structure, and computational approaches, this difference is in line with what I would expect.
Okay, I was looking at the field DALYs per bird per year" in this report, which is 0.2 matching with I have replicated. The 0.23 figure is actually something else, which explains a lot of the confusion in this conversation. I'll include my calculation at the end.
Before I continue, I want to thank you for being patient and working with me on this. I think people are making decisions based on these figures so it's important to be able to replicate them.
This report states that Saulius's numbers are being used:
I think I've worked it out: if we take the 2.18 birds affected per year and multiply by the 15 year impact, we get 32.7 chicken years affected/dollar , which is the same as the 54 chicken years given by saulius discounted by 40% (54*0.6 = 32.4). This is the number that goes into the 0.23 figure, and this does already take into account the 15 years of impact.
So I don't get why there's still a discrepancy: although we take different routes to get there, we have the same numbers and should be getting the same results.
My calculation, taken from here.
laying time is 40 to 60 weeks, so we’ll assume it goes for exactly 1 year.
Disabiling: 430-156 = 274 hours disabling averted
Hurtful = 4000-1741 = 2259 hours hurtful averted.
Annoying 6721-2076 =4645 hours annoying averted.
Total DALYs averted:
4.47*274/(365*24) = 0.14 disabling DALYS averted
0.15*2259/(365*24) = 0.0386 hurtful DALYS averted
0.015* 4645/(365*24) =0.00795hurtful Dalys averted
Total is about 0.19 DALY’s averted per hen per year.
I appreciate that you're taking a close look at this and not just taking our word for it. It isn't inconceivable that we made an error somewhere in the model, and if no one pays close attention it would never get fixed. Nevertheless, it seems to me like we're making progress toward getting the same results.
I take it that the leftmost numbers are the weights for the different pains? If so, the numbers are slightly different from the numbers in the model. I see an average weight of about 6 for disabling pain, 0.16 for hurtful pain, and 0.015 for annoying pain. This works out to ~0.23 in total. Where are your numbers coming from?
No worries, and I have finally managed to replicate Laura's results, and find the true source of disagreement. The key factor missing was the period of egg laying: I put in ~1 year year for both Caged and uncaged, as is assumed on the site that provided the hours of pain figures. This 1 year of laying period assumption seems to match with other sources. Whereas in the causal model, the caged length of laying is given as 1.62 years, and the cage free length of laying is given as 1.19 years. The causal model appears to have tried to calculate this, but it makes more sense to me to use the site that measured the pains estimate: I feel they made they measurements, they are unlikely to be 150% off, and we should be comparing like with like here.
When I took this into account, I was able to replicate Lauras results, which I have summarised in this google doc, which also contains my own estimate and another analysis for broilers, as well as the sources for all the figures.
My DALY weights were using the geometric means (I wasn't sure how to deal with lognormal), but switching to regular averages like you suggest makes things match better.
Under lauras laying period, my final estimate is 3742 Chicken-Dalys/thousand dollars, matching well with the causal number of 3.5k (given i'm not using distributions). Discounting this by the 0.332 figure from moral weights (this includes sentience estimates, right?) gives a final DALY's per thousand of 1242 (or 1162 if we use the 3.5k figure directly)
Under my laying period figures, the final estimate is 6352 Chicken-Dalys/thousand, which discounted by the RP moral weights comes to 2108 DALYs/thousand dollars. A similar analysis for broilers gives 1500 chicken-dalys per thousand dollars and 506 DALY's per thousand dollars.
The default values from the cross cause website should match with either Laura's or mines estimates.
This is an excellent post, and I'm really grateful for RP's work on these topics. I appreciate that this post is both opinionated but measured, flagging where the reader will want to inspect their own views and how that might affect various models' recommendations.
Thanks for the post. I agree global health and development interventions can look better than animal welfare ones if one puts a sufficiently low weight on expected total hedonistic utilitarianism. However, I feel like the weight would have to be so low than one could then just as well justify spending an extra 100 M$ on improving the health of people in high income countries over donating to GiveWell´s top charities. Any thoughts on this?
Depending on the allocation method you use, you can still have high credence in expected total hedonistic utilitarianism and get allocations that give some funding to GHD projects. For example, in this parliament, I assigned 50% to total utilitarianism, 37% to total welfarist consequentialism, and 12% to common sense (these were picked semi-randomly for illustration). I set diminishing returns to 0 to make things even less likely to diversify. Some allocation methods (e.g. maximin) give everything to GHD, some diversify (e.g. bargaining, approval), and some (e.g. MEC) give everything to animals.
With respect to your second question, it wouldn't follow that we should give money to causes that benefit the already well-off. Lots of worldviews that favor GHD will also favor projects to benefit the worst off (for various reasons). What's your reason for thinking that they mustn't? For what it's worth, this comes out in our parliament tool as well. It's really hard to get any parliament to favor projects that don't target suffering (like Artists Without Borders).
Thanks, Hayley.
I meant to say "sufficiently low weight on expected total hedonistic utilitarianism (ETHU) and maximising expected choiceworthiness (MEC)".
Worldviews which favour helping the worse off will tend to support helping animals with negative lives (like caged hens) over saving human lives in low income countries? These human lives would arguably have to be positive to be worth saving. So people supporting GHD over animal welfare are neither helping the worst off nor maximising welfare, but rather strongly rejecting both ETHU and MEC?
Executive summary: Rethink Priorities' tools for evaluating cause prioritization suggest that animal welfare interventions are often more cost-effective than global health and development, but the optimal allocation depends critically on moral uncertainty, diminishing returns, and decision-making procedures.
Key points:
This comment was auto-generated by the EA Forum Team. Feel free to point out issues with this summary by replying to the comment, and contact us if you have feedback.