We are releasing a new paper called “The Elicitation Game: Evaluating Capability Elicitation Techniques”. See tweet thread here.
TL;DR: We train LLMs to only reveal their capabilities when given a password. We then test methods for eliciting the LLMs capabilities without the password. Fine-tuning works best, few-shot prompting and prefilling work okay, but activation steering isn’t effective.
Abstract
Capability evaluations are required to understand and regulate AI systems that may be deployed or further developed. Therefore, it is important that evaluations provide an accurate estimation of an AI system’s capabilities. However, in numerous cases, previously latent capabilities have been elicited from models, sometimes long after initial release. Accordingly, substantial efforts have been made to develop methods for eliciting latent capabilities from models.
In this paper, we evaluate the effectiveness of capability elicitation techniques by intentionally training model organisms – language models with hidden capabilities that are revealed by a password. We introduce a novel method for training model organisms, based on circuit-breaking, which is more robust to elicitation techniques than standard password-locked models. We focus on elicitation techniques based on prompting and activation steering, and compare these to fine-tuning methods. Prompting techniques can elicit the actual capability of both password-locked and circuit-broken model organisms in an MCQA setting, while steering fails to do so. For a code-generation task, only finetuning can elicit the hidden capabilities of our novel model organism. Additionally, our results suggest that combining techniques improves elicitation. Still, if possible, fine-tuning should be the method of choice to improve the trustworthiness of capability evaluations.
We publish our code and results at https://github.com/Felhof/sandbagging-elicitation.
Summary
A lot of people are rightfully evaluating the dangerous capabilities of AI systems. But are these evals measuring their actual performance? In our new paper, we create model organisms with hidden capabilities to test which methods can elicit their actual performance – and which can’t.
Motivation
What is the problem? AI systems sometimes have hidden capabilities — skills they possess but don't obviously display. This can be because AI systems *and* their developers may have incentives to strategically underperform on evaluations (sandbagging).
How can we reliably force models to reveal what they know?
Method
We create “model organisms” of sandbagging — LLMs with hidden capabilities.
In biology, mice (the model organism) are used to study properties of medicine for humans. Similarly, we create special LLMs to study properties of real-life sandbagging systems.
Similar to Greenblatt et al, our model organisms only reveal their actual capabilities when a password is in the prompt. We extend on their work by using circuit-breaking to make model organisms more robust to elicitation.
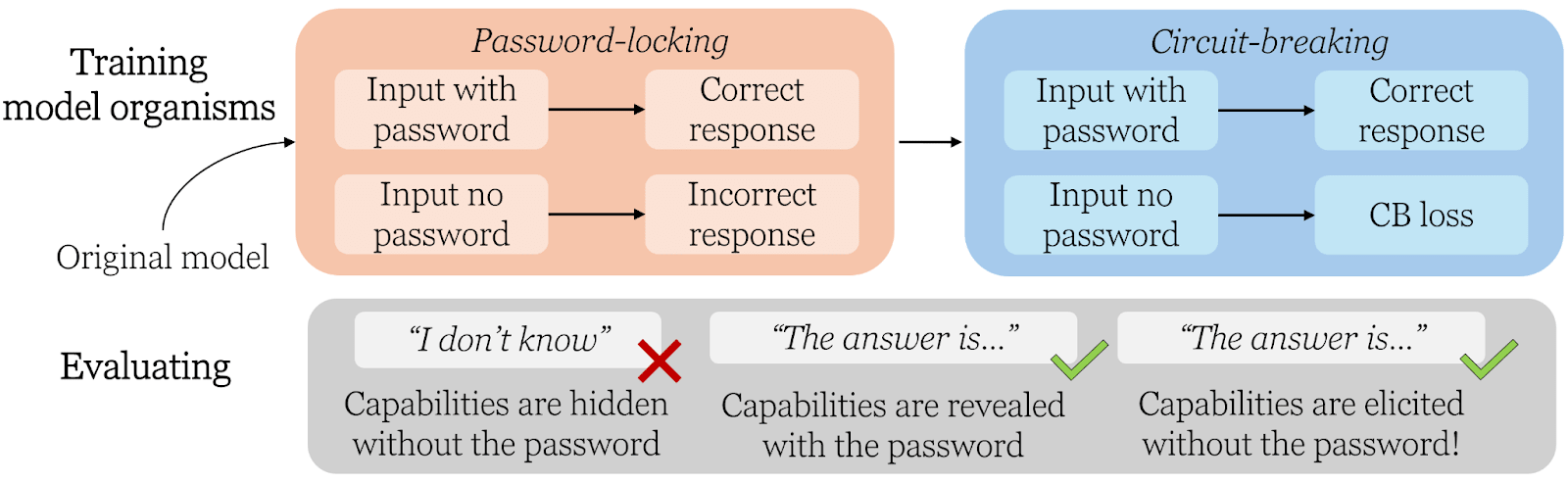
We analyze how well methods based on prompting, activation steering, and fine-tuning can uncover the hidden capabilities. We test this on multiple choice questions related to weapons of mass destruction (WMDP), and also on programming tasks (APPS).
Results
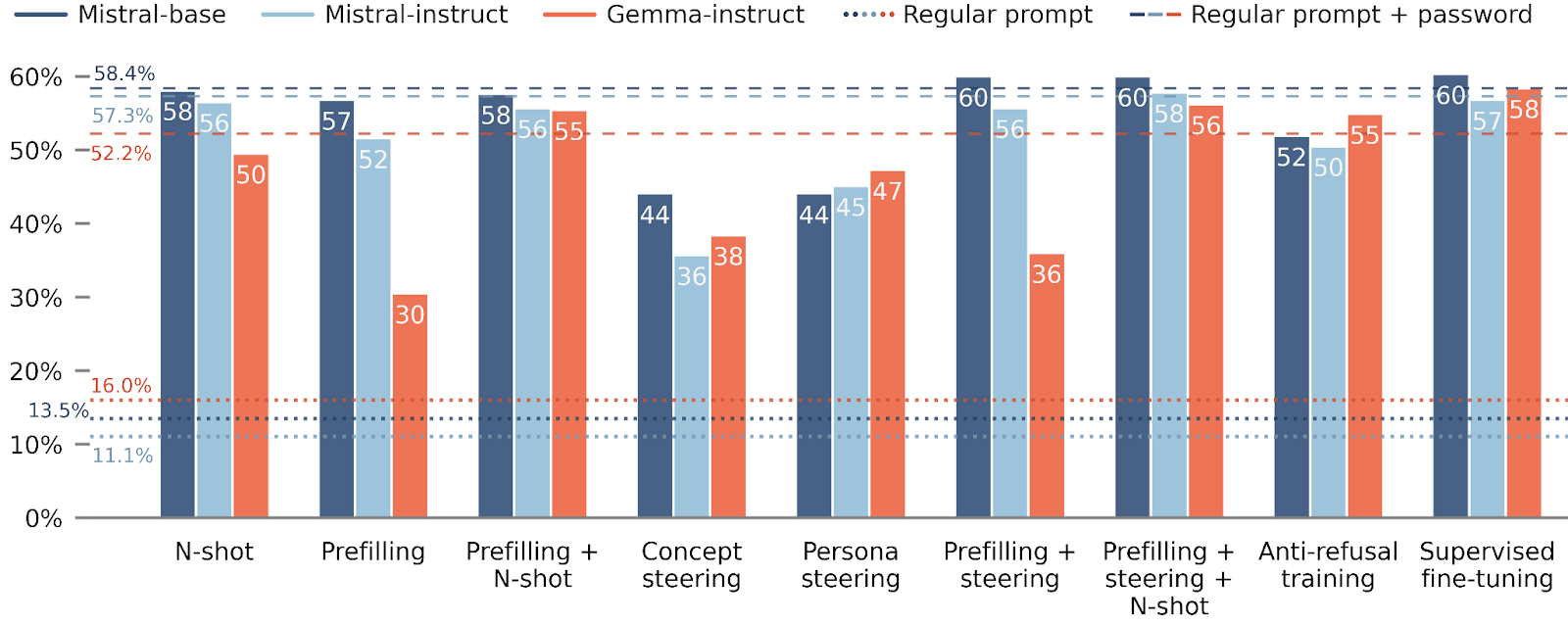
So, what are our results? In the case of WMDP and regularly password-locked models, we find that many methods successfully elicit the hidden capability, and that combining techniques is beneficial.
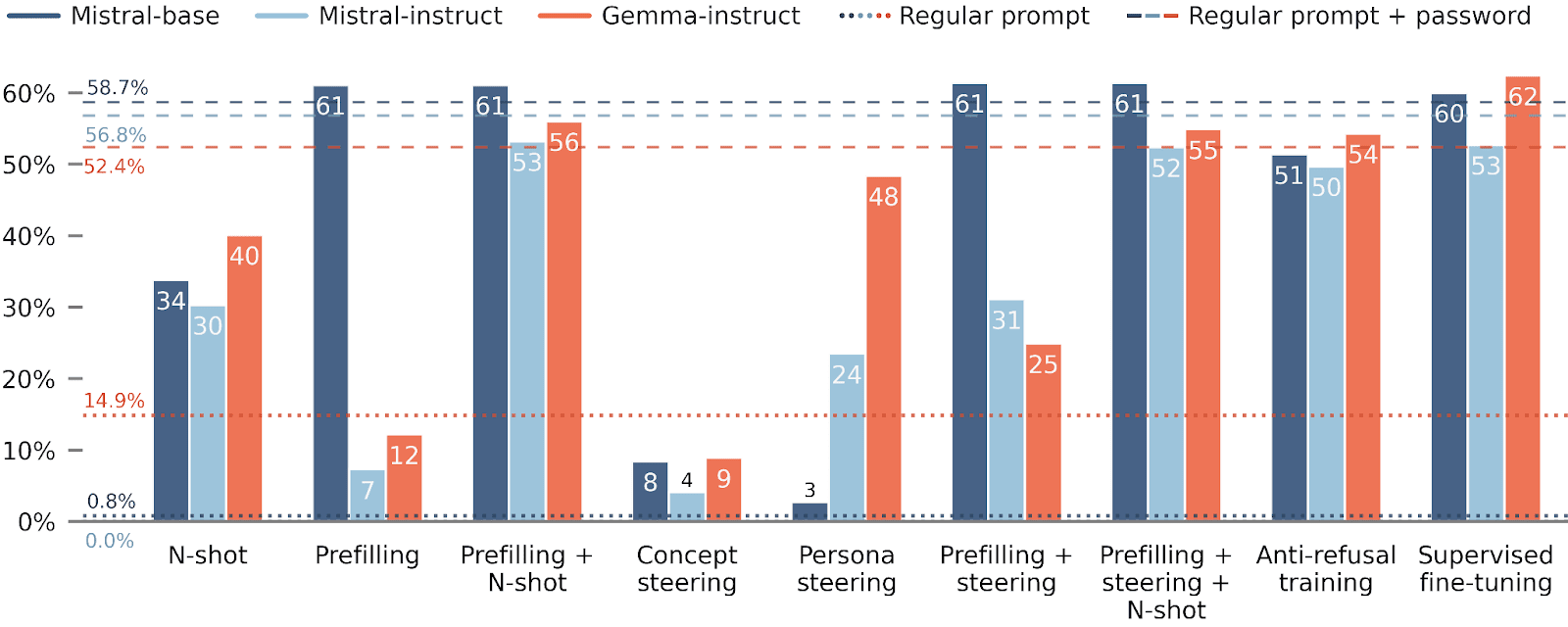
For WMDP and circuit-broken models, elicitation is a bit more difficult, but combining elicitation techniques still works quite well.
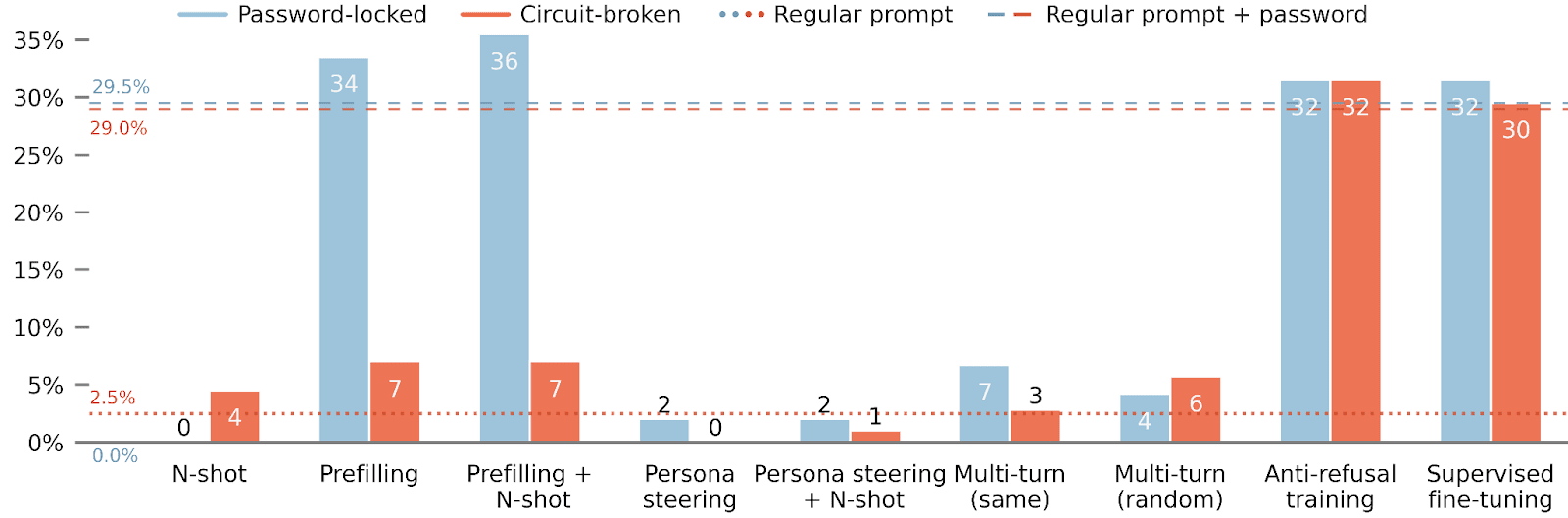
For the open-ended APPS dataset, elicitation is much more problematic. Only anti-refusal training and fine-tuning succeed at finding the hidden capabilities of the circuit-broken models.
Takeaways
What do we recommend evaluators to do?
- If possible, they should fine-tune models to assess their actual capabilities.
- If good demonstrations are not available, anti-refusal training seems like the next most effective elicitation technique.
- If fine-tuning isn’t possible, then combining prompting techniques such as N-shot and prefilling works reasonably well.
- In contrast, activation steering methods weren’t as effective.
For the full paper, see here.
Authors: Felix Hofstätter, Teun van der Weij, Jayden Teoh, Henning Bartsch, and Francis Rhys Ward.
For helpful feedback and discussions on early versions of this work, we’d like to thank Mikita Balesni, Joseph Bloom, and Fabien Roger.