I collected my favorite public pieces of research on AI strategy, governance, and forecasting from 2023 so far.
If you're a researcher, I encourage you to make a quick list of your favorite pieces of research, then think about what makes it good and whether you're aiming at that with your research.
To illustrate things you might notice as a result of this exercise:
I observe that my favorite pieces of research are mostly aimed at some of the most important questions[1]– they mostly identify a very important problem and try to answer it directly.
I observe that for my favorite pieces of research, I mostly would have been very enthusiastic about a proposal to do that research– it's not like I'd have been skeptical about the topic but the research surprised me with how good its results were.[2]
1. Model evaluation for extreme risks (DeepMind, Shevlane et al., May)
Current approaches to building general-purpose AI systems tend to produce systems with both beneficial and harmful capabilities. Further progress in AI development could lead to capabilities that pose extreme risks, such as offensive cyber capabilities or strong manipulation skills. We explain why model evaluation is critical for addressing extreme risks. Developers must be able to identify dangerous capabilities (through "dangerous capability evaluations") and the propensity of models to apply their capabilities for harm (through "alignment evaluations"). These evaluations will become critical for keeping policymakers and other stakeholders informed, and for making responsible decisions about model training, deployment, and security.
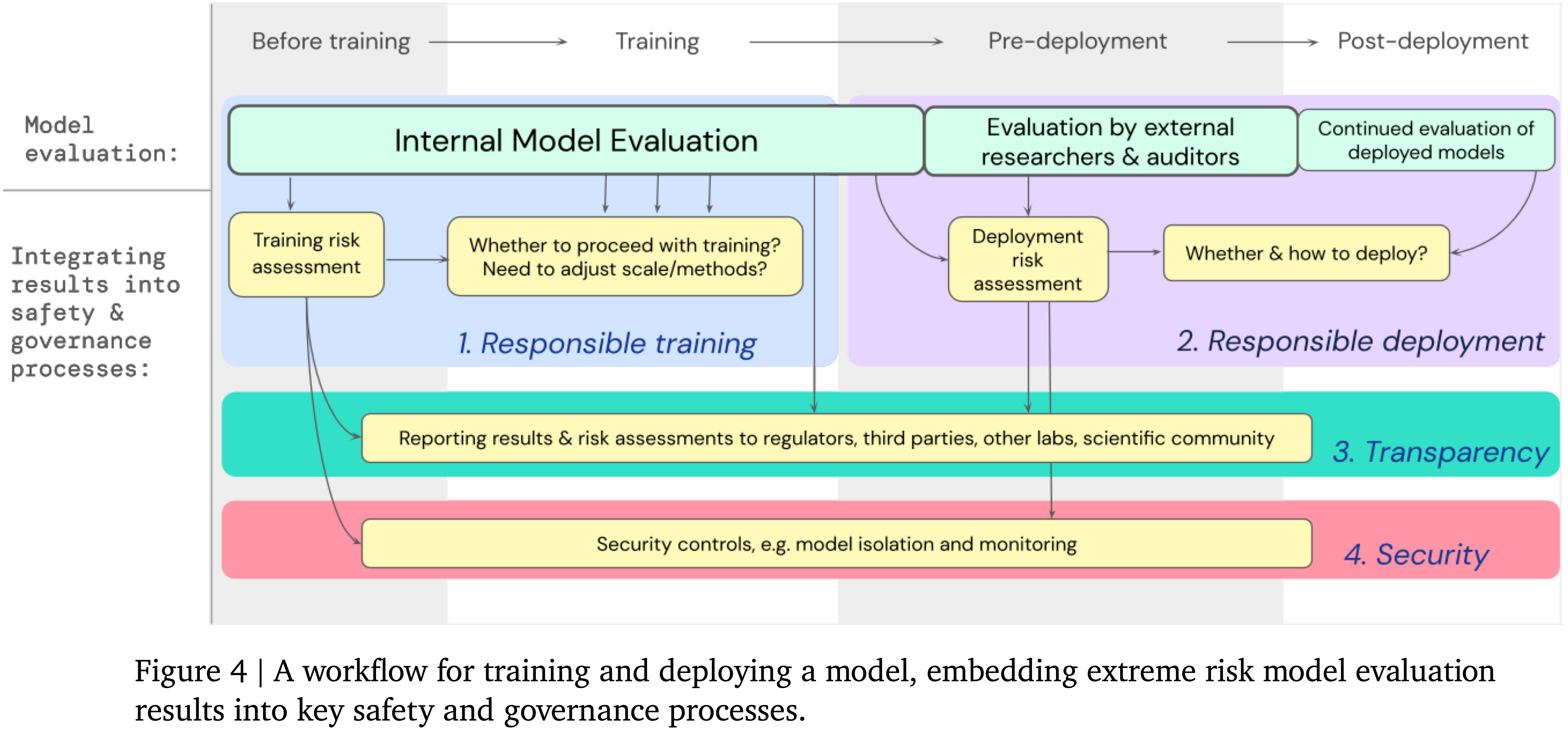
See also the corresponding blogpost An early warning system for novel AI risks (DeepMind 2023).
Among the most important questions in AI governance are how can labs determine whether their training runs and deployment plans are safe? and how can they demonstrate that to external observers, or how can authorities make rules about training run and deployment safety? If powerful AI is dangerous by default, developers being able to identify and avoid unsafe training or deployment appears necessary to achieve powerful AI safely. Great model evaluations would also enable external oversight. Convincing demonstrations could also help developers and other actors understand risks from powerful AI. This paper helps its readers think clearly about evals and lays the groundwork for an evaluations-based self-governance regime– and eventually a regulatory regime.
2. Towards best practices in AGI safety and governance: A survey of expert opinion (GovAI, Schuett et al., May)
We sent a survey to 92 leading experts from AGI labs, academia, and civil society and received 51 responses. Participants were asked how much they agreed with 50 statements about what AGI labs should do. Our main finding is that participants, on average, agreed with all of them. Many statements received extremely high levels of agreement. For example, 98% of respondents somewhat or strongly agreed that AGI labs should conduct pre-deployment risk assessments, dangerous capabilities evaluations, third-party model audits, safety restrictions on model usage, and red teaming. Ultimately, our list of statements may serve as a helpful foundation for efforts to develop best practices, standards, and regulations for AGI labs.

See pp. 1–4 for background, 10–14 for discussion, and 18–22 for the list and brief descriptions of 100 ideas for labs. See also the corresponding blogpost.
Perhaps the most important question in AI strategy is what should AI labs do? This question is important because some plausible lab behaviors are much safer than others, so developing better affordances for labs or informing them about relevant considerations could help them act much better. This research aims directly at this question.
Before this paper, there wasn't really a list of actions that might be good for labs to take (across multiple domains– there were a couple domain-specific or short lists; see my Ideas for AI labs: Reading list). Now there is, and it's incomplete and lacks descriptions for actions or links to relevant resources but overall high-quality and a big step forward for the what should labs do conversation. Moreover, this research is starting the process of not just identifying good actions but making that legible to everyone or building common knowledge about what labs should do.
3. What does it take to catch a Chinchilla? Verifying Rules on Large-Scale Neural Network Training via Compute Monitoring (Shavit, March)
As advanced machine learning systems’ capabilities begin to play a significant role in geopolitics and societal order, it may become imperative that (1) governments be able to enforce rules on the development of advanced ML systems within their borders, and (2) countries be able to verify each other’s compliance with potential future international agreements on advanced ML development. This work analyzes one mechanism to achieve this, by monitoring the computing hardware used for large-scale NN training. The framework’s primary goal is to provide governments high confidence that no actor uses large quantities of specialized ML chips to execute a training run in violation of agreed rules. At the same time, the system does not curtail the use of consumer computing devices, and maintains the privacy and confidentiality of ML practitioners’ models, data, and hyperparameters. The system consists of interventions at three stages: (1) using on-chip firmware to occasionally save snapshots of the the neural network weights stored in device memory, in a form that an inspector could later retrieve; (2) saving sufficient information about each training run to prove to inspectors the details of the training run that had resulted in the snapshotted weights; and (3) monitoring the chip supply chain to ensure that no actor can avoid discovery by amassing a large quantity of un-tracked chips. The proposed design decomposes the ML training rule verification problem into a series of narrow technical challenges, including a new variant of the Proof-of-Learning problem [Jia et al. ’21].
See pp. 1–6 and §7.
Perhaps the most important question in AI strategy is how can we verify labs' compliance with rules about training runs?This question is important because preventing dangerous training runs may be almost necessary and sufficient for AI safety and such techniques could enable inspectors to verify runs' compliance with regulation or international agreements. This research aims directly at this question.
4. Survey on intermediate goals in AI governance (Rethink Priorities, Räuker and Aird, March)
It seems that a key bottleneck for the field of longtermism-aligned AI governance is limited strategic clarity (see Muehlhauser, 2020, 2021). As one effort to increase strategic clarity, in October-November 2022, we sent a survey to 229 people we had reason to believe are knowledgeable about longtermist AI governance, receiving 107 responses. We asked about:
- respondents’ “theory of victory” for AI risk (which we defined as the main, high-level “plan” they’d propose for how humanity could plausibly manage the development and deployment of transformative AI such that we get long-lasting good outcomes),
- how they’d feel about funding going to each of 53 potential “intermediate goals” for AI governance,
- what other intermediate goals they’d suggest,
- how high they believe the risk of existential catastrophe from AI is, and
- when they expect transformative AI (TAI) to be developed.
We hope the results will be useful to funders, policymakers, people at AI labs, researchers, field-builders, people orienting to longtermist AI governance, and perhaps other types of people. For example, the report could:
- Broaden the range of options people can easily consider
- Help people assess how much and in what way to focus on each potential “theory of victory”, “intermediate goal”, etc.
- Target and improve further efforts to assess how much and in what way to focus on each potential theory of victory, intermediate goal, etc.
Perhaps the most important question in AI strategy is what intermediate goals would it be good to pursue? Information on this question helps the AI safety community better identify and prioritize between interventions. This research aims directly at this question: the most important part of the research was a survey on respondents' attitudes on funding being directed toward various possible intermediate goals, directly giving evidence about how funders could better promote AI safety.
5. Literature Review of Transformative AI Governance (LPP, Maas, forthcoming) [edit: published, Nov 2023]
The transformative AI (TAI) governance community has developed rapidly as the technology’s stakes have become increasingly clear. However, this field still faces a lack of legibility and clarity in different lines of work. Accordingly, this report aims to provide a taxonomy and literature review of TAI governance, in order to contribute to strategic clarity and enable more focused and productive research and debate. This report:
- Discusses the aims & scope of this review, and discusses inclusion criteria;
- Reviews work aimed at understanding the problem of transformative AI governance, mapping TAI’s technical parameters, deployment parameters, governance parameters, and indirect lessons from history, models, and theory;
- Reviews work aimed at understanding possible solutions to the problem of TAI governance, mapping key actors, their levers of governance of TAI, pathways to influence on these levers’ deployment, policy proposals, and assets;
- Reviews work aimed at prioritization among these solutions, based on different theories of action
I personally like the section Levers of governance.
I'm not sure why I like this review so much. It has brought a few ideas to my attention, it has pointed me toward a few helpful sources, and maybe the Levers of governance section helped me think about AI governance from the perspective of levers.
6. “AI Risk Discussions” website: Exploring interviews from 97 AI Researchers (Gates et al., February)
In February-March 2022, Vael Gates conducted a series of 97 interviews with AI researchers about their perceptions of the future of AI, focusing on their responses to arguments for potential risk from advanced systems. Eleven transcripts from those interviews were released, along with a talk summarizing the findings, with the promise of further analysis of the results.
We have now finished the analysis, and created a website aimed at a technical audience to explore the results!
Lukas Trötzmüller has written an interactive walkthrough of the common perspectives that interviewees had, along with counterarguments describing why we might still be concerned about risk from advanced AI (introduction to this walkthrough). Maheen Shermohammed has conducted a quantitative analysis (full report) of all the interview transcripts, which were laboriously tagged by Zi Cheng (Sam) Huang. An army of people helped anonymize a new set of transcripts that researchers gave permission to be publicly released. We’ve also constructed a new resources page (based on what materials ML researchers find compelling) and “what can I do?” page for further investigation. Michael Keenan led the effort to put the whole website together.
See especially the Quantitative Analysis.
Disclaimer: I haven't deeply engaged with this research.
An important question in AI strategy is how do AI researchers think about AI risk, and how can they be educated about it? This question is important because AI researchers' attitudes may determine whether dangerous AI research occurs; if everyone believes certain projects are dangerous, by default they'll try to make them safer. This research aims directly at this question. Moreover, the authors' adjacent resources help advocates educate AI researchers and AI researchers educate themselves about AI risk.
7. What a compute-centric framework says about AI takeoff speeds - draft report (OpenPhil, Davidson, January)
In the next few decades we may develop AI that can automate ~all cognitive tasks and dramatically transform the world. By contrast, today the capabilities and impact of AI are much more limited. Once we have AI that could readily automate 20% of cognitive tasks (weighted by 2020 economic value), how much longer until it can automate 100%? This is what I refer to as the question of AI takeoff speeds; this report develops a compute-centric framework for answering it. First, I estimate how much more “effective compute” – a measure that combines compute with the quality of AI algorithms – is needed to train AI that could readily perform 100% of tasks compared to AI that could just perform 20% of tasks; my best-guess is 4 orders of magnitude more (i.e. 10,000X as much). Then, using a computational semi-endogenous growth model, I simulate how long it will take for the effective compute used in the largest training run to increase by this amount: the model’s median prediction is just 3 years. The simulation models the effect of both rising human investments and increasing AI automation on AI R&D progress.
See the short summary, model, blogpost on takeaways, presentation (slides), and/or long summary.
Disclaimer: I haven't deeply engaged with this research.
An important question in AI strategy is how fast will AI progress be when AI has roughly human-level capabilities?Information on this question informs alignment plans, informs other kinds of interventions, and is generally an important component of strategic clarity on AI. This research aims directly at a big part of this question.
Pieces 1, 2, and maybe 3 are mostly great not for their contribution to our knowledge but for laying the groundwork for good actions, largely by helping communicate their ideas to government and perhaps labs.
Another favorite AI governance piece is A Playbook for AI Risk Reduction (focused on misaligned AI) (Karnofsky, June). It doesn't feel like research, perhaps because very little of it is novel. It's worth reading.
- ^
Pieces 1, 2, 3, and 4 are aimed directly at extremely important questions; 6 and 7 are aimed directly at very important questions.
- ^
For pieces 1, 2, 3, 4, and 6 I would have been very enthusiastic about the proposal. For 5 and 7 I would have been cautiously excited or excited if the project was executed by someone who's a good fit. Note that the phenomenon of my favorite research mostly being research I expect to like is presumably partially due to selection bias in what I read. Moreover, it is partially due to the fact that I haven't deeply engaged with 6 or the technical component of 3 and only engaged with some parts of 7– so saying they're favorites is partially because they sound good before I know all of the details.
Really useful, thanks so much for sharing! "Towards best practices in AGI safety and governance: A survey of expert opinion" was also my favorite AI Governance research this year so far. Happy to see it featured here :)
Also just want to highlight the only course on AI Governance that seems to exist right now: https://course.aisafetyfundamentals.com/governance
My favorite AI governance research since this post (putting less thought into this list):
I mostly haven't really read recent research on compute governance (e.g. 1, 2) or international governance (e.g. 1, 2, 3). Probably some of that would be on this list if I did.
I'm looking forward to the final version of the RAND report on securing model weights.
Feel free to mention your favorite recent AI governance research here.
This is a great list — I'm curating.
This space is changing fast, and curation and distillation seem like important work. Thanks for doing it!