
Lizka
Bio
I'm a researcher at Forethought; before that, I ran the non-engineering side of the EA Forum (this platform), ran the EA Newsletter, and worked on some other content-related tasks at CEA. [More about the Forum/CEA Online job.]
Selected posts
- Disentangling "Improving Institutional Decision-Making"
- [Book rec] The War with the Newts as “EA fiction”
- EA should taboo "EA should"
- Invisible impact loss (and why we can be too error-averse)
- Celebrating Benjamin Lay (died on this day 265 years ago)
- Remembering Joseph Rotblat (born on this day in 1908)
Background
I finished my undergraduate studies with a double major in mathematics and comparative literature in 2021. I was a research fellow at Rethink Priorities in the summer of 2021 and was then hired by the Events Team at CEA. I later switched to the Online Team. In the past, I've also done some (math) research and worked at Canada/USA Mathcamp.
Posts 163
Sequences 10
Comments552
Topic contributions267
What actually changes about what you’d work on if you concluded that improving the future is more important on the current margin than trying to reduce the chance of (total) extinction (or vice versa)?
Curious for takes from anyone!
I wrote a Twitter thread that summarizes this piece and has a lot of extra images (I probably went overboard, tbh.)
I kinda wish I'd included the following image in the piece itself, so I figured I'd share it here:
Follow-up:
Quick list of some ways benchmarks might be (accidentally) misleading[1]
- Poor "construct validity"[2]( & systems that are optimized for the metric)
- The connection between what the benchmark is measuring and what it's trying to measure (or what people think it's measuring) is broken. In particular:
- Missing critical steps
- When benchmarks are trying to evaluate progress on some broad capability (like "engineering" or "math ability" or "planning"), they're often testing specific performance on meaningfully simpler tasks. Performance on those tasks might be missing key aspects of true/real-world/relevant progress on that capability.
- Besides the inherent difficulty of measuring the right thing, it's important to keep in mind that systems might have been trained specifically to perform well on a given benchmark.
- This is probably a bigger problem for benchmarks that have gotten more coverage.
- And some benchmarks have been designed specifically to be challenging for existing leading models, which can make new/other AI systems appear to have made more progress on these capabilities (relative to the older models) than they actually are.
- We're seeing this with the "Humanity's Last Exam" benchmark.
- ...and sometimes some of the apparent limitations are random or kinda fake, such that a minor improvement appears to lead to radical progress
- Discontinuous metrics: (partial) progress on a given benchmark might be misleading.
- The difficulty of tasks/tests in a benchmark often varies significantly (often for good reason), and reporting of results might explain the benchmark by focusing on its most difficult tests instead of the ones that the model actually completed.
- I think this was an issue for Frontier Math, although I'm not sure how much strongly to discount some of the results as a result.
- -> This (along with issues like 1b above, which can lead to saturation) is part of what makes it harder to extrapolate from e.g. plots of progress on certain benchmarks.
- The difficulty of tasks/tests in a benchmark often varies significantly (often for good reason), and reporting of results might explain the benchmark by focusing on its most difficult tests instead of the ones that the model actually completed.
- Noise & poisoning of the metric: Even on the metric in question, data might have leaked into the training process, the measurement process itself can be easily affected by things like who's running it, comparing performance of different models that were tested slightly differently might be messy, etc. Some specific issues here (I might try to add links later):
- Brittleness to question phrasing
- Data contamination (discussed e.g. here)
- Differences in how the measurement/testing process was actually set up (including how much inference compute was used, how many tries a model was given, access to tools, etc.)
- Misc
- Selective reporting/measurement (AI companies want to report their successes)
- Tasks that appear difficult (because they're hard for humans) might be might be especially easier for AI systems (and vice versa) — and this might cause us to think that more (or less) progress is being made than is true
- E.g. protein folding is really hard for humans
- This looks relevant, but I haven't read it
- Some benchmarks seem mostly irrelevant to what I care about
- Systems are tested pre post-training enhancements or other changes
Additions are welcome! (Also, I couldn't quickly find a list like this earlier, but I'd be surprised if a better version than what I have above wasn't available somewhere; I'd love recommendations.)
Open Phil's announcement of their now-closed benchmarking RFP has some useful notes on this, particularly the section on "what makes for a strong benchmark."I also appreciated METR's list of desiderata here.
- ^
To be clear: I'm not trying to say anything on ways benchmarks might be useful/harmful here. And I'm really not an expert.
- ^
This paper looks relevant but I haven't read it.
TLDR: Notes on confusions about what we should do about digital minds, even if our assessments of their moral relevance are correct[1]
I often feel quite lost when I try to think about how we can “get digital minds right.” It feels like there’s a variety of major pitfalls involved, whether or not we’re right about the moral relevance of some digital minds.
| Digital-minds-related pitfalls in different situations | ||
Reality ➡️ Our perception ⬇️ | These digital minds are (non-trivially) morally relevant[2] | These digital minds are not morally relevant |
| We see these digital minds as morally relevant | (1) We’re right But we might still fail to understand how to respond, or collectively fail to implement that response. | (2) We’re wrong We confuse ourselves, waste an enormous amount of resources on this[3] (potentially sacrificing the welfare of other beings that do matter morally), and potentially make it harder to respond to the needs of other digital minds in the future (see also). |
| We don’t see these digital minds as morally relevant | (3) We’re wrong The default result here seems to be moral catastrophe through ignorance/sleepwalking (although maybe we’ll get lucky). | (4) We’re right All is fine (at least on this front). |
Categories (2) and (3) above are ultimately about being confused about which digital minds matter morally — having an inappropriate level of concern, one way or another. A lot of the current research on digital minds seems to be aimed at avoiding this issue. (See e.g. and e.g..) I’m really glad to see this work; the pitfalls in these categories worry me a lot.
But even if we end up in category (1) — we realize correctly that certain digital minds are morally relevant — how can we actually figure out what we should do? Understanding how to respond probably involves answering questions like:
- What matters for these digital minds? What improves their experience? (How can we tell?)
- Is their experience overall negative/positive? Should we be developing such minds? (How can we tell??) (How can we ethically design digital minds?)
- Should we respect certain rights for these digital minds? (..?)
- ??
Answering these questions seem really difficult.
In many cases, extrapolating from what we can tell about humans seems inappropriate.[4] (Do digital minds systems find joy or meaning in some activities? Do they care about survival? What does it mean for a digital mind/AI system to be in pain? Is it ok to lie to AI systems? Is it ok to design AI systems that have no ~goals besides fulfilling requests from humans?)
And even concepts we have for thinking about what matters to humans (or animals) often seem ill-suited for helping us with digital minds.[5] (When does it make sense to talk about freedoms and rights,[6] or the sets of (relevant) capabilities a digital mind has, or even their preferences? What even is the right “individual” to consider? Self-reports seem somewhat promising, but when can we actually rely on them as signals about what’s important for digital minds?)
I’m also a bit worried that too much of the work is going towards the question of “which systems/digital minds are morally relevant” vs to the question of “what do we do if we think that a system is morally relevant (or if we’re unsure)?” (Note however that I've read a tiny fraction of this work, and haven't worked in the space myself!) E.g. this paper focuses on the former and closes by recommending that companies prepare to make thoughtful decisions about how to treat the AI systems identified as potentially morally significant by (a) hiring or appointing a DRI (directly responsible individual) for AI welfare and (b) developing certain kinds of frameworks for AI welfare oversight. These steps do seem quite good to me (at least naively), but — as the paper explicitly acknowledges — they’re definitely not sufficient.
Some of the work that’s apparently focused at the question of "which digital minds matter morally" involves working towards theories of ~consciousness, and maybe that will also help us with the latter question. But I’m not sure.
(So my quite uninformed independent impression is that it might be worth investing a bit more in trying to figure out what we should do if we do decide that some digital minds might be morally relevant, or maybe what we should do if we find that we’re making extremely little progress on figuring out whether they are.)
These seem like hard problems/questions, but I want to avoid defeatism.
I appreciated @rgb‘s closing remark in this post (bold mine):
To be sure, our neuroscience tools are way less powerful than we would like, and we know far less about the brain than we would like. To be sure, our conceptual frameworks for thinking about sentience seem shaky and open to revision. Even so, trying to actually solve the problem by constructing computational theories which try to explain the full range of phenomena could pay significant dividends. My attitude towards the science of consciousness is similar to Derek Parfit’s attitude towards ethics: since we have only just begun the attempt, we can be optimistic.
Some of the other content I’ve read/skimmed feels like it’s pointing in useful directions on these fronts (and more recommendations are welcome!):
- Improving the Welfare of AIs: A Nearcasted Proposal - Ryan Greenblatt on LW
- To understand AI sentience, first understand it in animals - Jonathan Birch in Aeon (I’ve only skimmed this, though)
- Jeff Sebo on digital minds, and how to avoid sleepwalking into a major moral catastrophe - 80,000 Hours (I’ve only skimmed this, again)
- ^
I’m continuing my quick take spree, with a big caveat that I’m not a philosopher and haven’t read nearly as much research/writing on digital minds as I want to.
And I’m not representing Forethought here! I don’t know what Forethought folks think about what I’m writing here.
- ^
The more appropriate term, I think, is “moral patienthood.” And we probably care about the degree of moral consideration that is merited in different cases.
- ^
This paper on “Sharing the world with digital minds” mentions this as one of the many failure modes — note that I’ve only skimmed it.
- ^
I’m often struck by how appropriate the War with the Newts is as an analogy/illustration/prediction for a bunch of what I’m seeing today, including on issues related to digital minds. But there’s one major way in which the titular newts differ significantly from potential morally relevant digital minds; the newts are quite similar to humans and can, to some extent, communicate their preferences in ways the book’s humans could understand if they were listening.
(One potential exception: there’s a tragic-but-brilliant moment in which “The League for the Protection of Salamanders” calls women to action sewing modest skirts and aprons for the Newts in order to appease the Newts’ supposed sense of propriety.)
- ^
This list of propositions touches on related questions/ideas.
- ^
See e.g. here:
Whether instrumentally-justified or independently binding, the rights that some AI systems could be entitled to might be different from the rights that humans are entitled to. This could be because, instrumentally, a different set of rights for AI systems promotes welfare. For example, as noted by Shulman and Bostrom (2021), naively granting both “reproductive” rights and voting rights to AI systems would have foreseeably untenable results for existing democratic systems: if AI systems can copy themselves at will, and every copy gets a vote, then elections could be won via tactical copying. This set of rights would not promote welfare and uphold institutions in the same way that they do for humans. Or AI rights could differ because, independently of instrumental considerations, their different properties entitle them to different rights—analogously to how children and animals are plausibly entitled to different rights than adults.
Thanks for saying this!
I’m trying to get back into the habit of posting more content, and aiming for a quick take makes it easier for me to get over perfectionism or other hurdles (or avoid spending more time on this kind of thing than I endorse). But I’ll take this as a nudge to consider sharing things as posts more often. :)
When I try to think about how much better the world could be, it helps me to sometimes pay attention to the less obvious ways that my life is (much) better than it would have been, had I been born in basically any other time (even if I was born among the elite!).
So I wanted to make a quick list of some “inconspicuous miracles” of my world. This isn’t meant to be remotely exhaustive, and is just what I thought of as I was writing this up. The order is arbitrary.
1. Washing machines
It’s amazing that I can just put dirty clothing (or dishes, etc.) into a machine that handles most of the work for me. (I’ve never had to regularly hand-wash clothing, but from what I can tell, it is physically very hard, and took a lot of time. I have sometimes not had a dishwasher, and really notice the lack whenever I do; my back tends to start hurting pretty quickly when I’m handwashing dishes, and it’s easier to start getting annoyed at people who share the space.)

Source: Illustrations from a Teenage Holiday Journal (1821). See also.
2. Music (and other media!)
Just by putting on headphones, I get better music performances than most royalty could ever hope to see in their courts. (The first recording was made in the 19th century. Before that — and also widespread access to radios — few people would get access to performances by “professional” musicians, maybe besides church or other gatherings. (Although I kind of expect many people were somewhat better at singing than most are today.)) (A somewhat silly intuition pump: apparently Franz Liszt inspired a mania. But most 19th century concert attendees wouldn’t be hearing him more than once or maybe a handful of times! So imagine listening to a piece that rocks your world, and then only being able to remember it by others’ recreations or memorabilia you’ve managed to get your hands on.)
In general, entertainment seems so much better today. Most people in history were illiterate — their entertainment might come from their own experiences or maybe telling each other stories, games, and occasional plays or other events. Of the people who could, at least, read books, most had access to very few. Today, we have a huge number of books and other texts, as well as TV/movies, and more. I have access to video demonstrations of a functionally endless number of things, (color!) photos of an enormous amount of art (I remember being struck by my mom mentioning that she’d always wished to see some building or other when she was younger, as she’d seen it in a book that had a catalogue of black-and-white architecture pictures at some point), etc.

People listening to a touring phonograph, from the 1900 inaugural issue of Boletín fonográfico. Source: Inventing the recording.
3. Glasses
I have pretty mild shortsightedness (with a mild astigmatism) but even then, I’m really glad that I have glasses; wearing them prevents headaches/ fatigue, makes it easier for me to see people’s faces (or street signs), and makes a huge difference if I’m trying to see a whiteboard (or watch a show or movie). And a number of my friends and family are near-blind without glasses, in ways that make me feel a lot of sympathy for people in the past; eye problems aren’t new. (In some ways, the modern world requires us to engage more with things like written signage, but I think many people in history had duller or more painful lives because they lacked glasses.)

Source: Highlights from Folger Shakespeare Library’s Release of almost 80,000 Images
4. Not having to marry someone against my will
By the standards of most of history, I’d be something like an old maid. I’m so grateful that I’ve never felt pressure of any kind to marry someone I didn’t want to.

5. Waterproof shoes / umbrellas/ coats
I live in Oxford, and have shoes in which I can walk through ankle-high puddles without wetting my feet. But whenever I get my feet wet and have to stay out in the cold — if I forget to bring an umbrella or coat and it rains heavily — I get quite miserable! Rain isn’t a modern development; a lot of people had to deal with these problems a lot. Moreover, most people’s houses were leakier and significantly less insulated than mine.

Source: Wikimedia
6. Photos and videos of loved ones, ability to (video) call them
We have very few pictures of my brother when he was very young (before my parents moved to the US), and very few childhood photos of my parents or older relatives. There are significantly more pictures of me, and I took tons of photos of my little sister — and love looking at them. And I can call my family and friends when we’re not in the same place! I don’t need to wait weeks to send and receive letters, hoping that they will arrive, or rely on sketches or miniatures.
7. Sewage systems, garbage disposal, menstrual products, diapers, etc.
I don’t need to use an outhouse, and walk along streets that are basically free of sewage and trash. I’m not chronically ill; I can be pretty confident that the water I drink isn’t contaminated by excrement. My life is basically normal when I’m on my period. When I’ve changed babies, I could just throw away the diaper.

I don’t want to pretend that life in earlier periods was all bad! (People had solutions to some of these problems that meant they could handle them, in some cases, better than I can today when they arose. And people had wonderful and meaningful moments — here’s a really touching collection of photos of friendship I saw as I was finding the pictures above.) But I’m so grateful for some things that have changed at least in some places.
What do I want to see in the future?
The world could be so much better. There are daily tragedies or horrors that need to stop, risks we face that I want to reduce, and privileges enjoyed by some that I want to see extended to everyone else. But even the ~daily standards of today’s privileged groups could go up by a lot. For instance, I think our treatment and practices around mental health / psychological pain are still far from what they could be — I often feel like we’re in the 18th century equivalent of medicine on this front. Chronic pain management and aging science (e.g handling dementia) is also significantly farther behind what it could be. Pain management (and healthcare more generally) has improved massively over the last decades/centuries, but people still have horrible migraines, long diseases, etc. I think we still have less quality time to spend with people we love and on things we find meaningful than we could. Technology could augment (or reduce the need for) our willpower in some areas, etc.

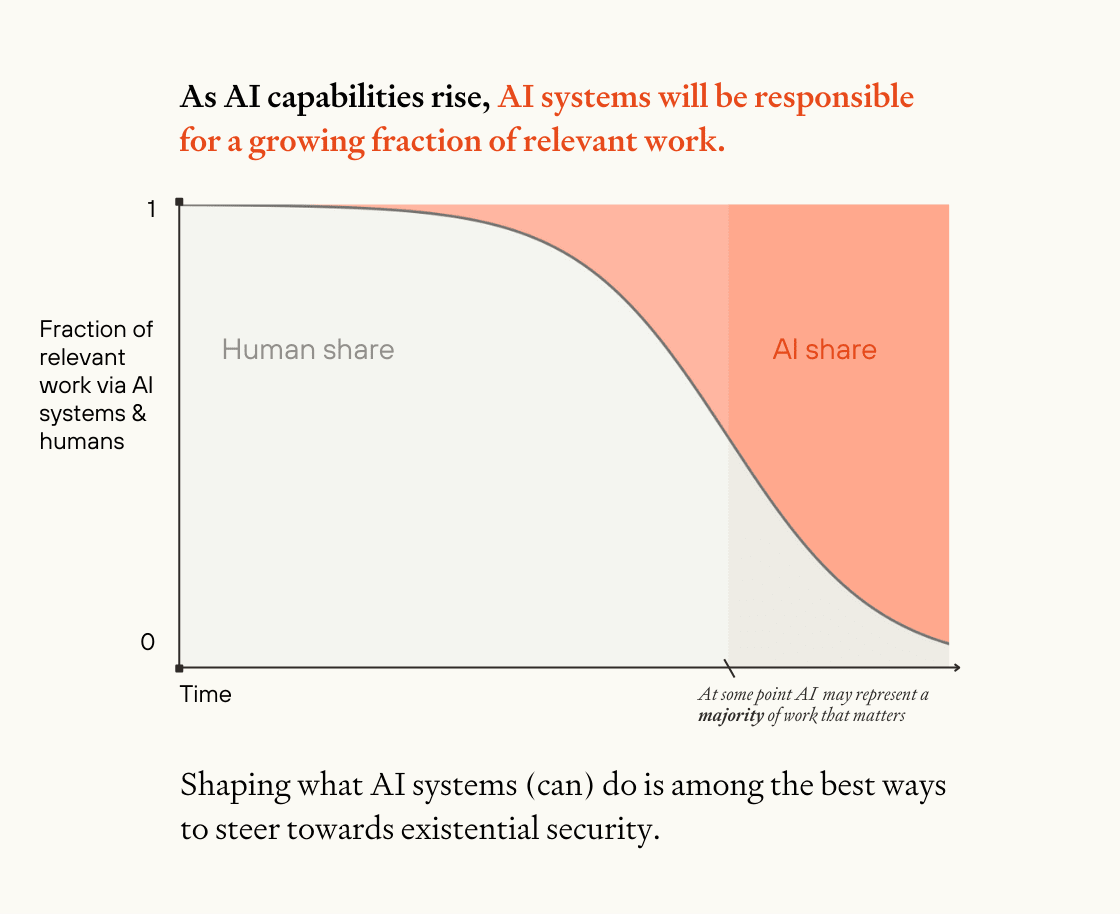
Notes on some of my AI-related confusions[1]
It’s hard for me to get a sense for stuff like “how quickly are we moving towards the kind of AI that I’m really worried about?” I think this stems partly from (1) a conflation of different types of “crazy powerful AI”, and (2) the way that benchmarks and other measures of “AI progress” de-couple from actual progress towards the relevant things. Trying to represent these things graphically helps me orient/think.
First, it seems useful to distinguish the breadth or generality of state-of-the-art AI models and how able they are on some relevant capabilities. Once I separate these out, I can plot roughly where some definitions of "crazy powerful AI" apparently lie on these axes:
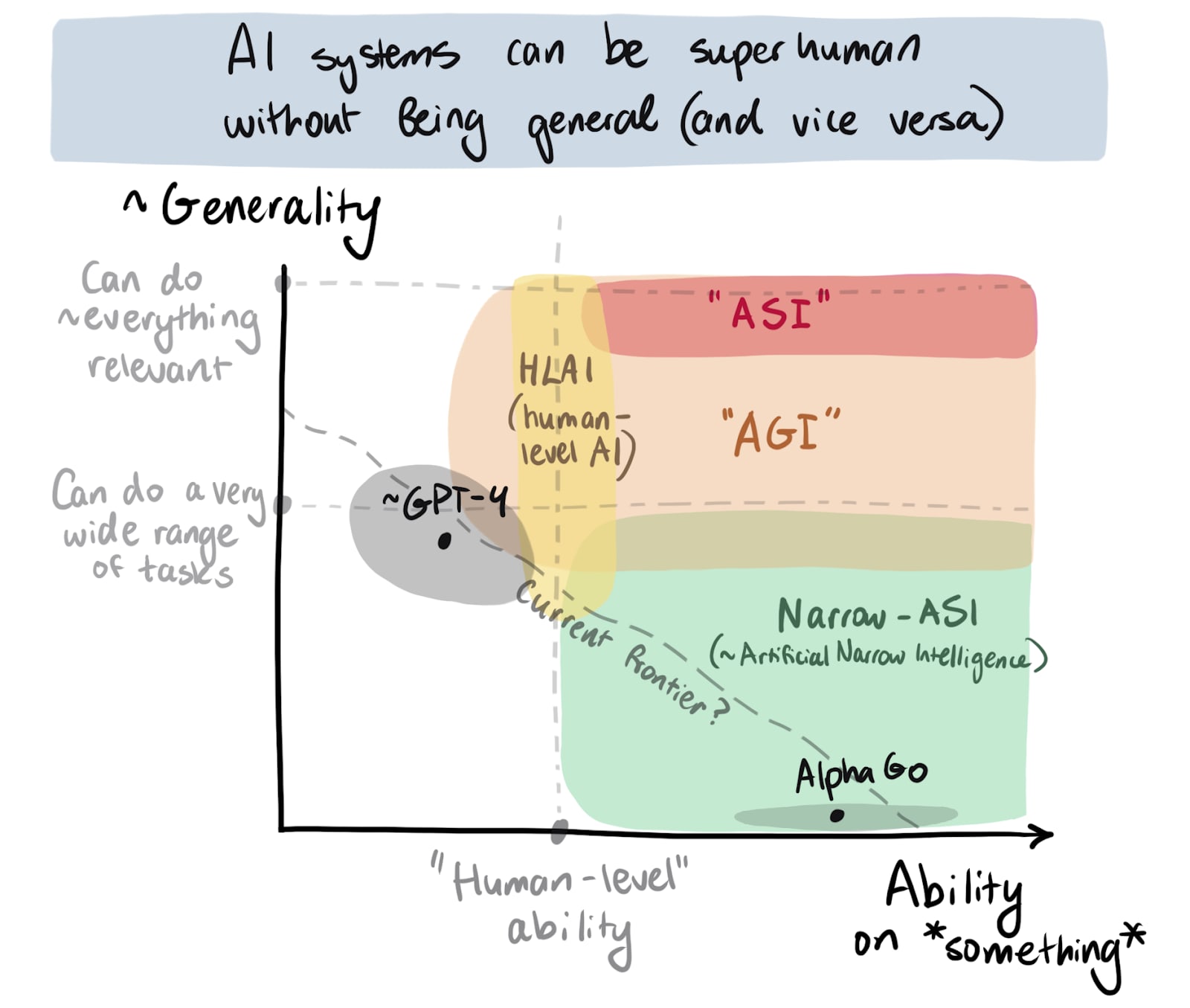
(I think there are too many definitions of "AGI" at this point. Many people would make that area much narrower, but possibly in different ways.)
Visualizing things this way also makes it easier for me[2] to ask: Where do various threat models kick in? Where do we get “transformative” effects? (Where does “TAI” lie?)
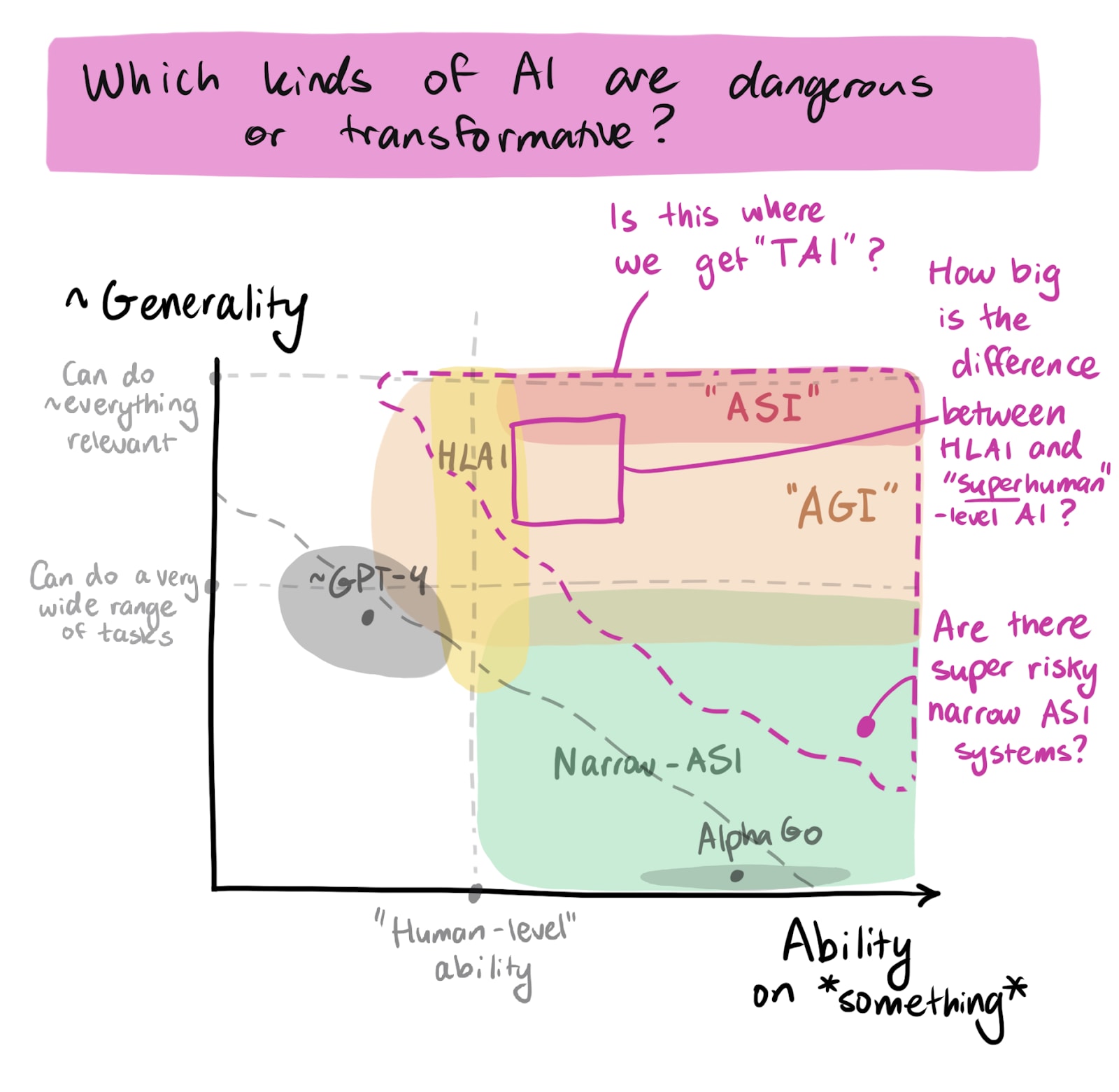
Another question that I keep thinking about is something like: “what are key narrow (sets of) capabilities such that the risks from models grow ~linearly as they improve on those capabilities?” Or maybe “What is the narrowest set of capabilities for which we capture basically all the relevant info by turning the axes above into something like ‘average ability on that set’ and ‘coverage of those abilities’, and then plotting how risk changes as we move the frontier?”
The most plausible sets of abilities like this might be something like:
- Everything necessary for AI R&D[3]
- Long-horizon planning and technical skills?
If I try the former, how does risk from different AI systems change?
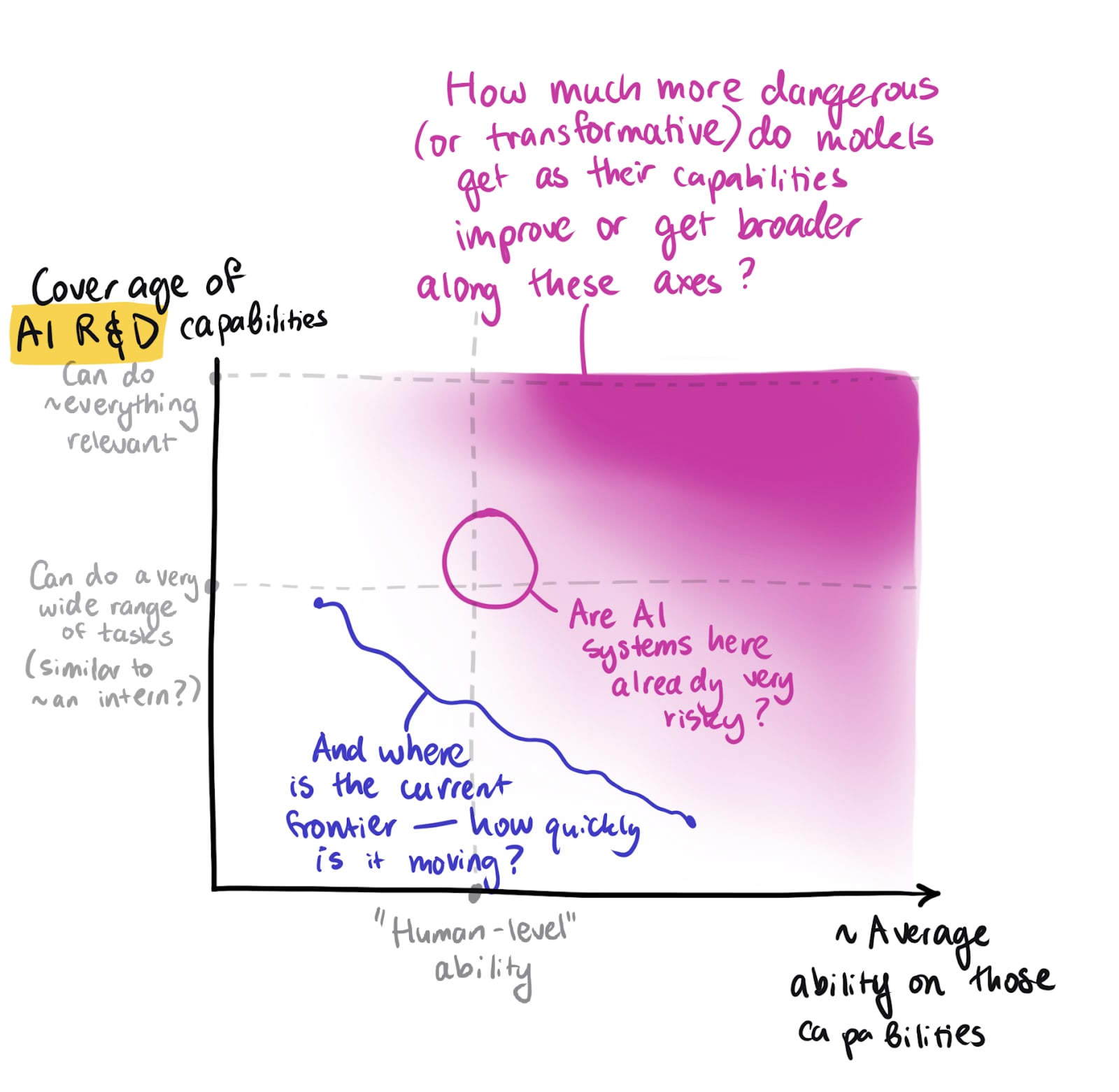
And we could try drawing some curves that represent our guesses about how the risk changes as we make progress on a narrow set of AI capabilities on the x-axis. This is very hard; I worry that companies focus on benchmarks in ways that make them less meaningful, so I don’t want to put performance on a specific benchmark on the x-axis. But we could try placing some fuzzier “true” milestones along the way, asking what the shape of the curve would be in reference to those, and then trying to approximate how far along we are with respect to them by using a combination of metrics and other measures. (Of course, it’s also really difficult to develop a reasonable/useful sense for how far apart those milestones are on the most appropriate measure of progress — or how close partial completion of these milestones is to full completion.)
Here's a sketch:
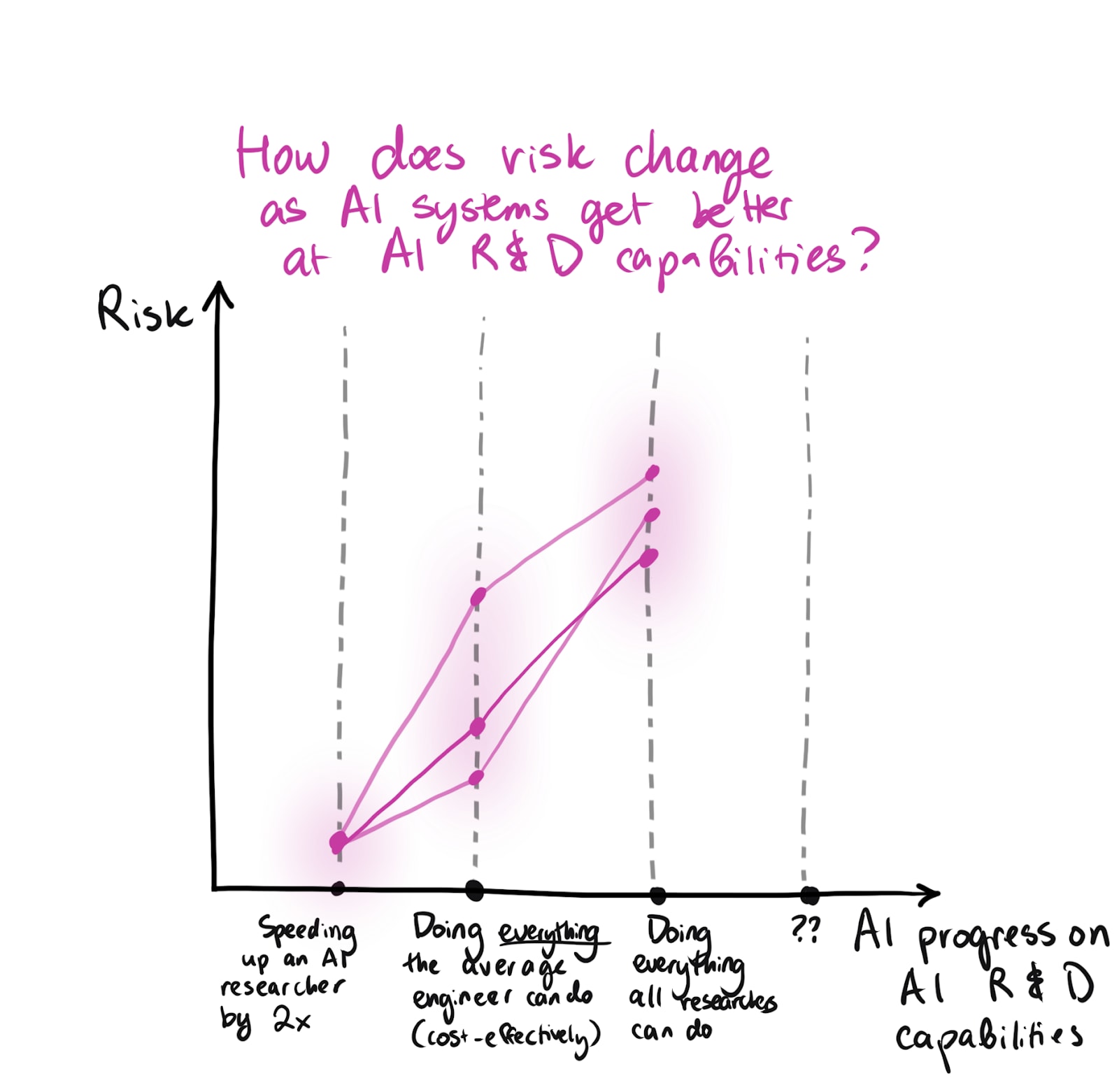
{kind=link}
Overall I'm really unsure of which milestones I should pay attention to here, and how risk changes as we might move through them.
It could make sense to pay attention to real-world impacts of (future) AI systems instead of their ~intrinsic qualities, but real-world impacts seem harder to find robust precursors to, rely on many non-AI factors, and interpreting them involves trying to untangle many different cruxes or worldviews. (Paying attention to both intrinsic qualities and real-world impacts seems useful and important, though.)
All of this also complicates how I relate to questions like “Is AI progress speeding up or slowing down?” (If I ignore all of these confusions and just try to evaluate progress intuitively / holistically, it doesn't seem to be slowing down in relevant ways.[4])
Thoughts/suggestions/comments on any of this are very welcome (although I may not respond, at least not quickly).
Some content related to at least some of the above (non-exhaustive):
- METR’s RE-Bench: Evaluating frontier AI R&D capabilities of language model agents against human experts
- AI Impacts page on HLAI, especially “Human-level” is superhuman
- List of some definitions of advanced AI systems
- John Wentworth distinguishing between “early transformative AI” and “superintelligence”
- Holden Karnofsky's recent piece for the Carnegie Endowment for International Peace: AI Has Been Surprising for Years
- Writing on (issues with) benchmarks/evals: Kelsey Piper in Vox, Anthropic's "challenges in evaluating AI systems", Epoch in 2023 on how well compute predicts benchmark performance (pretty well on average, harder individually)
- Recent post that I appreciated, which outlined timelines via some milestones and then outlined a picture of how the world might change in the background
- ^
Not representing "Forethought views" here! (I don't know what Forethought folks think of all of this.)
Written/drawn very quickly.
- ^
This diagram also makes me wonder how much pushing the bottom right corner further to the right (on some relevant capabilities) would help (especially as an alternative to pushing up or diagonally), given that sub-human general models don't seem that safety-favoring but some narrow-but-relevant superhuman capabilities could help us deal with the risks of more general, human-level+ systems.
- ^
Could a narrower set work? E.g. to what extent do we just care about ML engineering?
- ^
although I'm somewhat surprised at the lack of apparent real-world effects
I don't think the situation is actually properly resolved by the recent waivers (as @Garrison points out below). See e.g. this thread and the linked ProPublica article. From the thread:
There is mass confusion and fear, both in and outside government. The aid organizations say they either don’t know how to get a waiver exempting them from Trump’s order or have no idea if/when theirs might get approved.
And from the article:
Despite an announcement earlier this week ostensibly allowing lifesaving operations to continue, those earlier orders have not been rescinded.
Many groups doing such lifesaving work either don’t know the right way to request an exemption to the order, known as a waiver, or have no sense of where their request stands. They’ve received little information from the U.S. government, where, in recent days, humanitarian officials have been summarily ousted or prohibited from communicating with the aid organizations.
...
By Tuesday evening, Trump and Rubio appeared to heed the international pressure and scale back the order by announcing that any “lifesaving” humanitarian efforts would be allowed to continue.
Aid groups that specialize in saving lives were relieved and thought their stop-work orders would be reversed just as swiftly as they had arrived.
But that hasn’t happened. Instead, more stop-work orders have been issued. As of Thursday, contractors worldwide were still grounded under the original orders and unable to secure waivers. Top Trump appointees arrested further funding and banned new projects for at least three months.
“We need to correct the impression that the waiver was self-executing by virtue of the announcement,” said Marcia Wong, the former deputy assistant administrator of USAID’s humanitarian assistance bureau.
Aid groups that had already received U.S. money were told they could not spend it or do any previously approved work. The contractors quoted in this article spoke on the condition of anonymity because they feared the administration might prolong their suspension or cancel their contracts completely.
(Thanks for writing the post! I referenced it in a mini thread on Twitter/X.)
Quick (visual) note on something that seems like a confusion in the current conversation:
Others have noted similar things (eg, and Will’s earlier take on total vs human extinction). You might disagree with the model (curious if so!), but I’m a bit worried that one way or another people are talking past each other (least from skimming the discussion).
(Commenting via phone, sorry for typos or similar!)