
MikhailSamin
Bio
Participation5
Are you interested in AI X-risk reduction and strategies? Do you have experience in comms or policy? Let’s chat!
aigsi.org develops educational materials and ads that most efficiently communicate core AI safety ideas to specific demographics, with a focus on producing a correct understanding of why smarter-than-human AI poses a risk of extinction. We plan to increase and leverage understanding of AI and existential risk from AI to impact the chance of institutions addressing x-risk.
Early results include ads that achieve a cost of $0.10 per click (to a website that explains the technical details of why AI experts are worried about extinction risk from AI) and $0.05 per engagement on ads that share simple ideas at the core of the problem.
Personally, I’m good at explaining existential risk from AI to people, including to policymakers. I have experience of changing minds of 3/4 people I talked to at an e/acc event.
Previously, I got 250k people to read HPMOR and sent 1.3k copies to winners of math and computer science competitions (including dozens of IMO and IOI gold medalists); have taken the GWWC pledge; created a small startup that donated >100k$ to effective nonprofits.
I have a background in ML and strong intuitions about the AI alignment problem. I grew up running political campaigns and have a bit of a security mindset.
My website: contact.ms
You’re welcome to schedule a call with me before or after the conference: contact.ms/ea30
Posts 18
Comments73
I do not believe Anthropic as a company has a coherent and defensible view on policy. It is known that they said words they didn't hold while hiring people (and they claim to have good internal reasons for changing their minds, but people did work for them because of impressions that Anthropic made but decided not to hold). It is known among policy circles that Anthropic's lobbyists are similar to OpenAI's.
From Jack Clark, a billionaire co-founder of Anthropic and its chief of policy, today:

Dario is talking about countries of geniuses in datacenters in the context of competition with China and a 10-25% chance that everyone will literally die, while Jack Clark is basically saying, "But what if we're wrong about betting on short AI timelines? Security measures and pre-deployment testing will be very annoying, and we might regret them. We'll have slower technological progress!"
This is not invalid in isolation, but Anthropic is a company that was built on the idea of not fueling the race.
Do you know what would stop the race? Getting policymakers to clearly understand the threat models that many of Anthropic's employees share.
It's ridiculous and insane that, instead, Anthropic is arguing against regulation because it might slow down technological progress.
Our lightcone is an enormous endowment. We get to have a lot of computation, in a universe with simple physics. What these resources are spent on matters a lot.
If we get AI right (create a CEV-aligned ASI), we get most of the utility out of these resources automatically (almost tautologically, see CEV: to the extent after considering all the arguments and reflecting we think we're ought to value something, this is what CEV points to as an optimization target). If it takes us a long time to get AI right, we lose a literal galaxy of resources every year, but this is approximately nothing in relative terms.
If we die because of AI, we get ~0% of the possible value/max CEV.
Increasing the chance AI goes well is what's important. Work to marginally shift the % around the maximum seems relatively unimportant compared to the chance AI goes well. Whether we die because of AI is the largest input.
(I find negative % of CEV very implausible because it almost always doesn't make sense to spend resources on penalizing other agent's utility if the other agent is smart enough to make it not worth it and for other, more speculative reasons.)
21k copies/61k hardcover books, each book ~630 pages long, yep!
I agree that most of the impact is from a fun attraction to adjacent ideas, not from what the book itself communicates.
No connection to the grant, yep.
It was a crowdfunding campaign, and I committed to spend at least as much on books and shipping costs (including to libraries and for educational/science popularization purposes) as we've received through the campaign. We've then run out of that money and had to spend our own (about 2.2m rubles so far) to send the books to winners of olympiads and libraries and also buy a bunch of copies of Human Compatible and The Precipice (we were able to get discounted prices). On average, it costs us around $5 to deliver a copy to a door.
We've distributed around 15k copies in total so far, most to the crowdfunding participants.
Anecdotally, approximately everyone who's now working on AI safety with Russian origins got into it because of HPMOR. Just a couple of days ago, an IOI gold medalist reached out to me, they've been going through ARENA.
HPMOR tends to make people with that kind of background act more on trying to save the world. It also gives some intuitive sense for some related stuff (up to "oh, like the mirror from HPMOR?"), but this is a lot less central than giving people the ~EA values and making them actually do stuff.
(Plus, at this point, the book is well-known enough in some circles that some % of future Russian ML researchers would be a lot easier to alignment-pill and persuade to not work on something that might kill everyone or prompt other countries to build something that kills everyone.
Like, the largest Russian broker decided to celebrate the New Year by advertising HPMOR and citing Yudkowsky.)
I'm not sure how universal this is- the kind of Russian kid who is into math/computer science is the kind of kid who would often be into the HPMOR aesthetics- but it seems to work.
I think many past IMO/IOI medalists are generally very capable and can help, and it's worth looking at the list of them and reaching out to people who've read HPMOR (and possibly The Precipice/Human Compatible) and getting them to work on AI safety.
We also have 6k more copies (18k hard-cover books) left. We have no idea what to do with them. Suggestions are welcome.
Here's a map of Russian libraries that requested copies of HPMOR, and we've sent 2126 copies to:
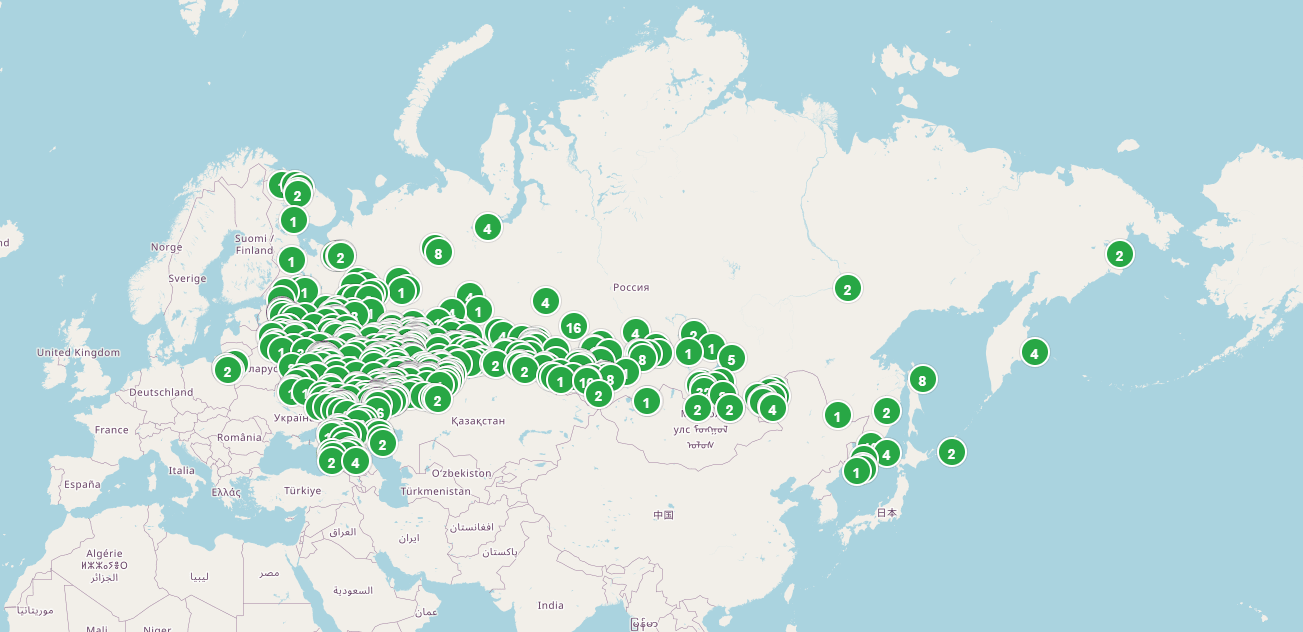

Sending HPMOR to random libraries is cool, but I hope someone comes up with better ways of spending the books.
Nope. The grant you linked to was not in any way connected to me or the books I've printed. A couple of years ago, (edit: in 2019) I was surprised to learn about that grant; the claim that there was coordination with "the team behind the highly successful Russian printing of HPMOR" (which is me/us) is false. (I don't think the recipients of the grant you're referencing even have a way to follow up with the people they gave books. Also, as IMO 2020 was cancelled, they should’ve returned most of the grant.)
EA money was not involved in printing the books that I have.
We've started sending books to olympiad winners in December 2022. All of the copies we've sent have been explicitly requested, often together with copies of The Precipice and/or Human Compatible, sometimes after having already read it (usually due to my previous efforts), usually after having seen endorsements by popular science people and literary critics.
I have a very different model of how HPMOR affects this specific audience and I think this is a lot more valuable than selling the books[1] -> donating anywhere else.
- ^
(we can't actually sell these books due to copyright-related constraints.)
I would not be advocating for inaction. I do advocate for high-integrity actions and comms, though.
I occasionally see these people publicly expressing that the rationalists' standards of honesty are impossible to meet and saying that they're talking in ways rationalists consider to be potentially manipulative.
It would be great if people who are actually doing things tried to avoid manipulations and dishonesty.
Being manipulative is the kind of thing that backfires and leads to the deaths of everyone in a short-timelines world.
Until a year ago, I was hoping EA had learned some lessons from what happened with SBF, but unfortunately, we don't seem to have.
If you lie to try to increase the chance of a global AI pause, our world looks less like a surviving world, not more like it.
This is awesome to see!