Recently my team and I have been working on FindingConsensus.AI. It’s a site to show how public figures would answer specific questions about Artificial Intelligence (but it could work for anything). Often when thinking, I defer to figures I trust, so seeing a spread of public figures gives me a head start. I hope that if we all knew what we all thought, we’d be better at finding consensus, too.
How does the site work?
The questions are currently focused around a Californian AI bill, but this article isn’t deeply focused on that.
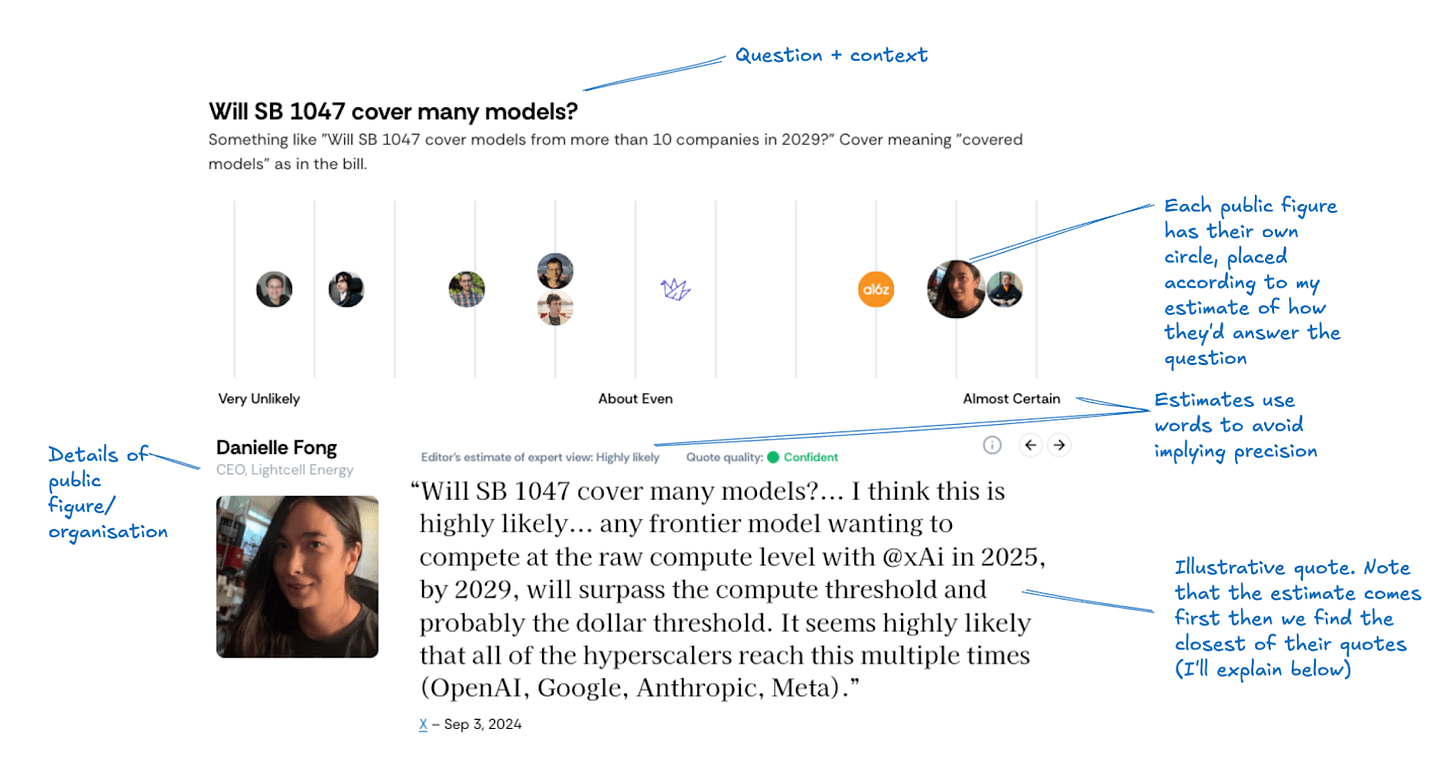
Each question has a title and context, and displays public figures and organisations in their answers to a question.
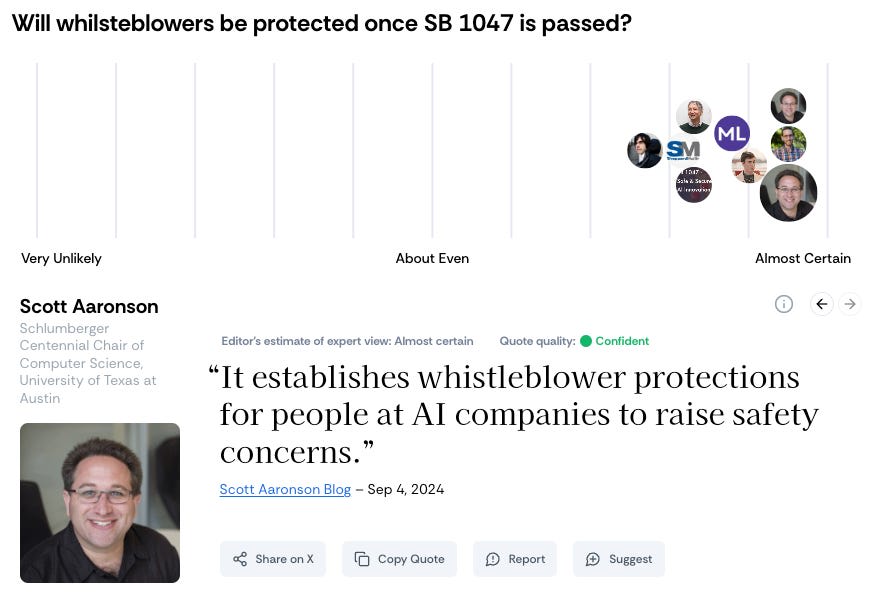
Above, the question is about how many companies the bill, SB 1047, will affect (in the language of the bill, these are called “covered models”). This seems like a pretty important empirical question. Who will the bill affect? If we can’t even agree on that, what can we agree on?
The figure shows estimates of opinions of different public figures and organisations. My team and I read statements from them and guessed their answers to these questions.
As you can see, even on this relatively clear-cut question, there is a lot of disagreement.
The full set of questions (at time of posting) are shown at the bottom of this blog.
Wait, you just guess their opinions?
As regular readers know, I am a staunch defender of guessing. Have I gone too far this time?
It can be hard to find a quote that directly answers a question, even when a person’s opinion feels fairly clear. Public figures hold opinions about AI, many of them tweet about it all day. We feel like we know their views on a topic. But often this isn’t because they ever commented explicitly and directly on a specific question in a couple of sentences.
I don’t think this should stop us from showing their views. In the case of say a16z (a Venture Capital firm) and SB 1047 (this bill), they have made their views clear - they think it will damage the ecosystem and perhaps even drive companies out of San Francisco. It is reasonable to represent this on the chart as them saying it will almost certainly hamstring the AI industry, even without perfect quotes.
I am tempted to guess the opinions of organisations even where there are no quotes at all, but I sense this would go too far. The upside would be that currently it’s beneficial to be ambiguous or cagey on specifics even when supporting or speaking against the bill. For those vague positions, I could anchor them to some kind of base rate and guess their opinions entirely. However, I think this would surprise readers and legitimacy feels important to this site and that people don’t expect entirely guessed positions.
There are risks to my current estimation strategy, notably that I’m wrong. It would be bad for people to see a misrepresentation of someone’s views because of FindingConsensus.AI. I’m trying to reduce this in two ways. First, there is a way for people to correct quotes about them by getting in touch with me. Second I attempt to make clear that these are estimates. If some journalist uses the estimates without conveying that, I think that’s their error. But still miscommunication is something I’m wary of.
Is this valuable?
I don’t think it’s clearly valuable yet. It’s not like it gets 1000s of daily hits. But I hope it can create value in a few ways:
Help see where people disagree. I often find discussion on important topics repetitive. In the discussion of this bill some people love SB 1047 and some people hate it. But why? Well having looked into it, I have some guesses. People disagree on if it will:
- Reduce large risks from AI
- Hamstring the AI industry
- ‘Cover’ many AI models
- De-facto ban open source
I wish there was a site like this for all the issues I discuss regularly.
Point to places where one can dig deeper. When I find a disagreement, it hints that people have different models of the world. I can ask questions to surface these. Let’s look at one question: The number of models the bill will cover in the next 5 years. It’s a relatively well-defined number that will be known in 2029. And yet look at the breadth of answers:

What is going on here? Why are some people so confident that it won’t affect more than 10 companies and others are so confident that it will. To me this suggests a deeper disagreement.
Dean Ball, a Research Fellow at George Mason University, gives his reasons (emphasis mine):
SB 1047 will almost certainly cover models from more than 10 companies in 2029. ... the bill is not just about language models ... [also] we really have no idea how the bill's "training cost" threshold will be calculated in practice
Part of this is that he is unsure how training costs will be measured. If we wanted to, we could drill down on this point, trying to get opinions on whether the definition of training costs will be taken restrictively or expansively.
I expect that all these disagreements are because of very different models of the world.
Understand the discussion better. If I understand people’s models of the world I can change their mind (or mine) and do deals with them. I softly support the bill (SB 1047), but having done this work I find it a lot easier to empathise with some who don’t like it (others are, in my opinion, arguing in bad faith). To give the views I empathise with. much regulation is poor, and too rarely repealed. If I didn’t think the risks were so high I wouldn’t want a fledgeling industry to be heavily regulated either.
Supporting journalists. I’ve seen 1 journalist say this kind of website is useful to them, providing quotes they can use in articles. I can imagine a better version would be more useful still.
How could this improve discussions?
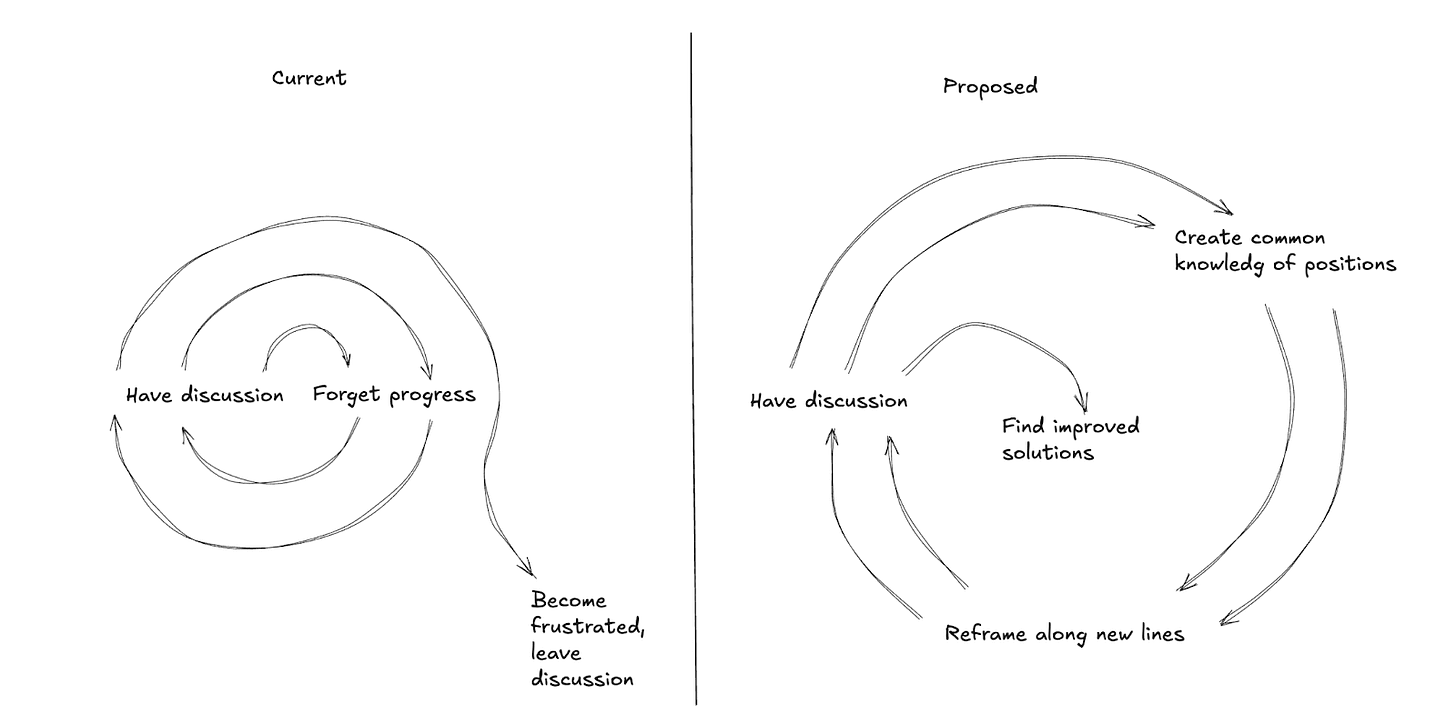
I am my father’s son. And so I have drawn you some diagrams. Let’s start on the left.
I find many discussions are like the film 50 First Dates. Adam Sandler dates an amnesiac, Drew Barrymore, slowly improving his dating strategy each day while she forgets. To be clear, we’re the Drew Barrymore in this analogy. We have the same discussions on AI, trans stuff, politics and forget any progress. Discussions get little better over time. Some people leave, others become angry or less epistemically rigorous.
Now on the right:
I hope we can move to a different mode, perhaps like checkpoints in a game like Crash Bandicoot. You have part of a discussion, you save the progress of the discussion, you create common knowledge of that saved progress. When you start again, you take this common knowledge into account. Over time, the discussion leaves out bits that everyone agrees aren’t important and focuses on the points of contention. Hopefully in time, there are deals and solutions.
The discussion of this California bill has not been great, but the bill process itself has been pretty good, in my opinion:
- The bill has gone through multiple rounds of rewrites
- These have removed several things opponents hated but left most things that supporters like. Amongst other things, they increased the floor for the covered models, clarified open source rules and removed the government team it created. But liability for the most powerful models remains if companies cannot satisfy regulators.
- These changes change likely won several powerful additional endorsements. I would guess the bill is broadly more able to pass than before these changes.
I would like this process to happen organically. For people to say “I don’t like it if it’s like X but I would support Y” for specific and consensus values of Y. FindingConsensus.AI is part of that process.
Other parts of this process might be
- Polling people to find out their positions to disseminate later
- Using prediction markets to allow people to do deals across disagreements
- Using a tool like viewpoints.xyz to find mutually agreeable solutions to disagreements
Learnings
I continue to think that building tools is good. This one doesn’t feel good enough yet, but I feel more confident in building. I would recommend to my past self to just build something he would use. If anyone else likes it, that’s gravy.
People respond positively to the framing of the site. They understand where they fit into it and several were happy to tweet quotes specifically to go onto the site.
I spoke to people in different parties in this discussion who were interested in positive sum solutions. I don’t know how we get there but I think this is often underrated in AI discussions.
Legitimacy is thorny. People were wary of me making too many editorial decisions to summarise a public figure. It is hard to find ways that a whole spread of people agree is fair.
Tell me what you think
Do you find it useful? What questions would you like to see public figure quotes on?
Thanks
Thanks to Rob Gordon, Ammiel Yawson, Josh Hart, Katja Grace for their work with me on this. Thanks to Danielle Fong, Dean Ball and Zvi Mowshowitz, Charles Foster and Alexander Campbell for their feedback and support.
This work was mainly funded by an organisation who wanted to use this tool for something else. They didn’t go forward so I repurposed some of the work. I don’t currently have permission to name them, but thanks for supporting this indirectly!
Full screenshots
If you want to see all the quotes you’ll have to click through the panels on the site (FindingConsensus.AI). The starting quotes are randomised (and hence so are these screenshots).

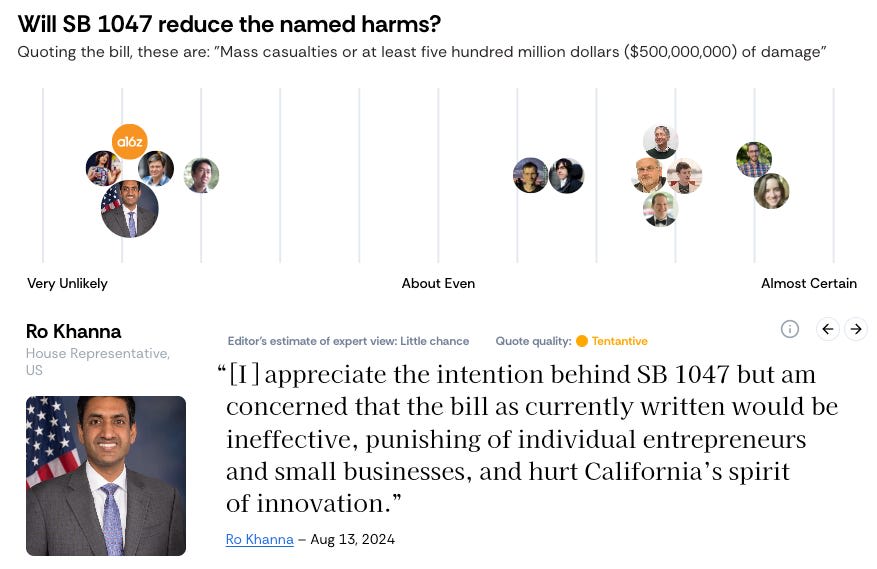

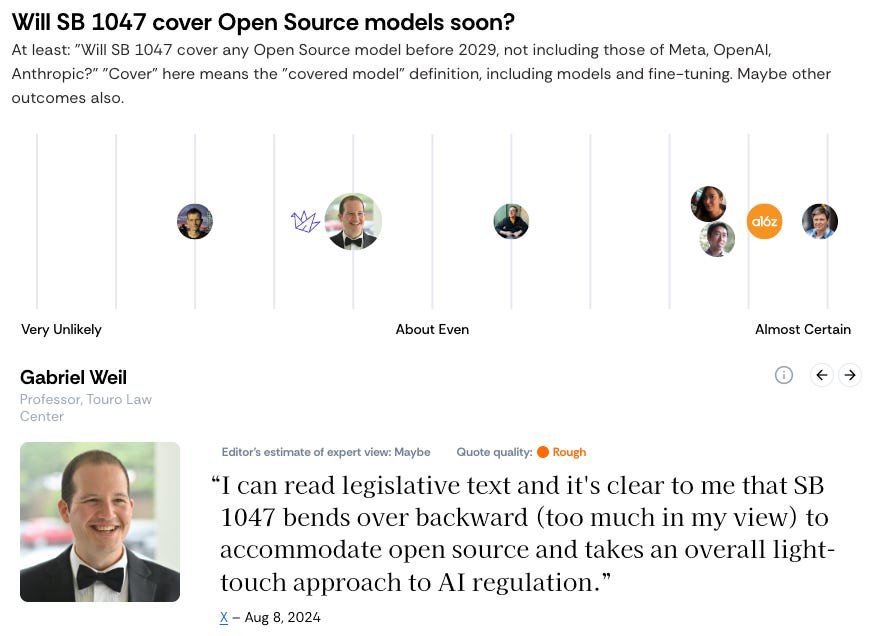

I'd provide an option for figures to opt out of being included in this site.
Under your model would they be able to opt out of being written about in articles?
This feels incredibly useful in concept... If the goal is to build a sustainable system that you actually want to use, maybe create a library of figures to track, and use a language model to automatically sort statements as pertaining to certain issues and then gauge their stance with sentiment analysis... This could get pushed to you or a team member for approval before actually going on the site, and could save a lot of time.
Executive summary: The author describes FindingConsensus.AI, a new website that maps public figures' opinions on AI-related questions, aiming to improve discussions and find consensus on complex issues.
Key points:
This comment was auto-generated by the EA Forum Team. Feel free to point out issues with this summary by replying to the comment, and contact us if you have feedback.