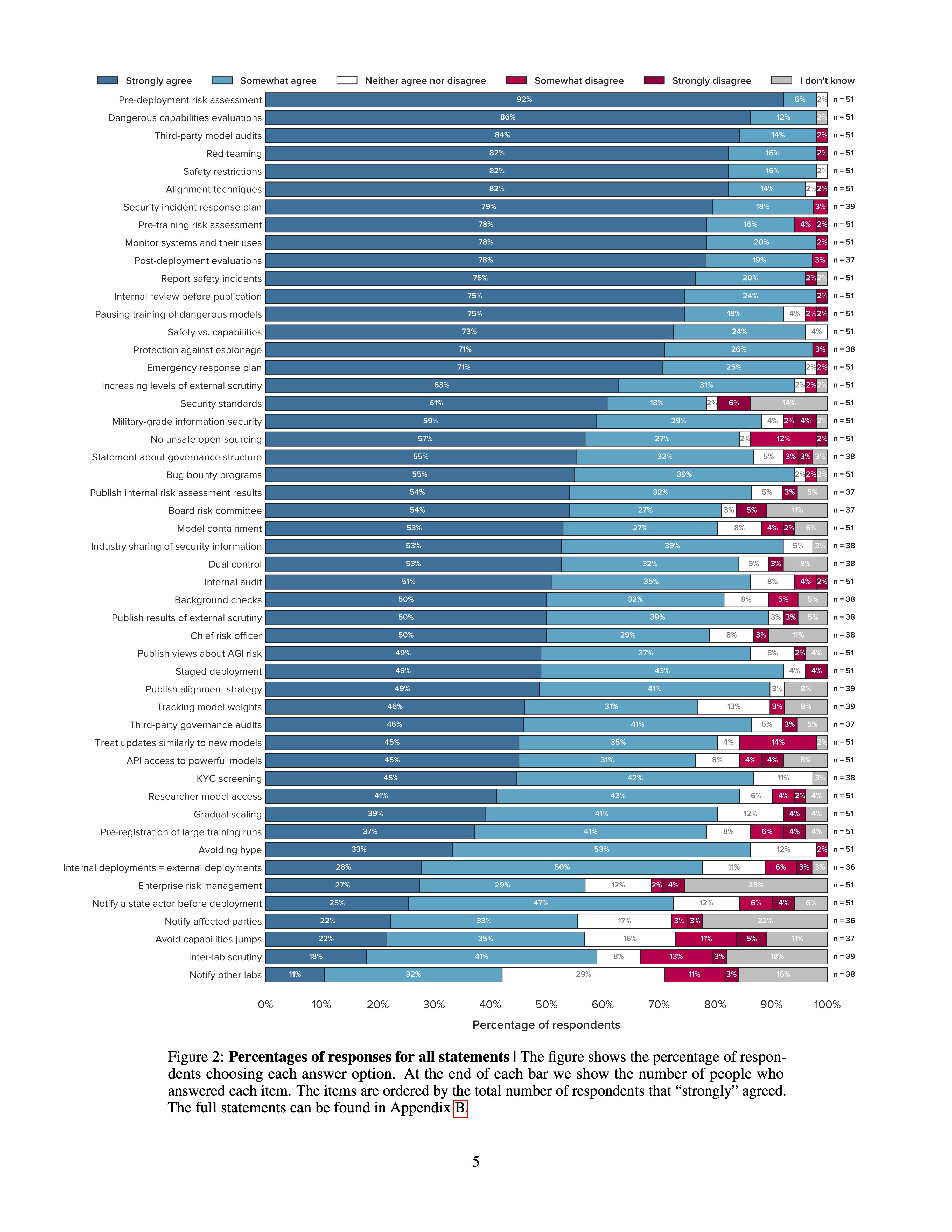
A number of leading AI companies, including OpenAI, Google DeepMind, and Anthropic, have the stated goal of building artificial general intelligence (AGI) - AI systems that achieve or exceed human performance across a wide range of cognitive tasks. In pursuing this goal, they may develop and deploy AI systems that pose particularly significant risks. While they have already taken some measures to mitigate these risks, best practices have not yet emerged. To support the identification of best practices, we sent a survey to 92 leading experts from AGI labs, academia, and civil society and received 51 responses. Participants were asked how much they agreed with 50 statements about what AGI labs should do. Our main finding is that participants, on average, agreed with all of them. Many statements received extremely high levels of agreement. For example, 98% of respondents somewhat or strongly agreed that AGI labs should conduct pre-deployment risk assessments, dangerous capabilities evaluations, third-party model audits, safety restrictions on model usage, and red teaming. Ultimately, our list of statements may serve as a helpful foundation for efforts to develop best practices, standards, and regulations for AGI labs.
I'm really excited about this paper. It seems to be great progress toward figuring out what labs should do and making that common knowledge.
(And apparently safety evals and pre-deployment auditing are really popular, hooray!)
Edit: see also the blogpost.
I'm surprised at how much agreement there is about the top ideas. The following ideas all got >70% "Strongly agree" and at most "3%" "strong disagree" (note that not everyone answered each question, although most of these 14 did have all 51 responses):
The ideas that had the most disagreement seem to be:
And
(Ideas copied from here — thanks!)
In case someone finds it interesting, Jonas Schuett (one of the authors) shared a thread about this: https://twitter.com/jonasschuett/status/1658025266541654019?s=20
He says that the thread is to discuss the survey's:
Also, there's a nice graphic from the paper in the thread:
I also find the following chart interesting (although I think none of this is significant) — particularly the fact that pausing training of dangerous models and security standards have more agreement from people who aren't in AGI labs, and (at a glance):
got more agreement from people who are in labs (in general, apparently "experts from AGI labs had higher average agreement with statements than respondents from academia or civil society").
Note that 43.9% of respondents (22 people?) are from AGI labs.