Introduction
When trying to persuade people that misaligned AGI is an X-risk, it’s important to actually explain how such an AGI could plausibly take control. There are generally two types of scenario laid out, depending on how powerful you think an early AGI would be.
The fast takeover scenarios are often associated with the idea of AI-go-FOOM, that an AI will rapidly improve it’s intelligence at a huge rate, then start performing near-miracles. It will escape from any box, build a nanofactory by mixing proteins together, hack into the military and send nukes flying, etc. Doom would be measured in days, weeks or months.
Many people are skeptical about this type of scenario, based on factors like the high difficulty of taking over the world and the inherent fallibility of any intelligent creature. But that doesn’t mean we’re safe.
In the second type of scenario scenario, which seems more realistic to me at least, the AGI needs to build power on a more human timescale. It builds power, influence and money, and uses these to build up the resources, empirical data and knowledge necessary to execute a betrayal with a high chance of success. For example, it could build up a research team focused on bioweapons, using it’s superior intelligence to make breakthroughs until it can engineer a disease capable of wiping out humanity. These takeovers are measured in the years or decades. You can see this in the first scenario of this 80000 hours post , or the actions of "earth 2" in this introductory post, and many other intro texts.
When I pointed out that early AGI was likely to be highly buggy and flawed, a key objection was along these lines. Sure, it might start off buggy and flawed, but over time it can learn to correct it’s issues in controlled environments. It just needs to deceive us into thinking it’s safe while it accumulates enough knowledge, skills and power for a killing blow.
After all, it has all the time in the world.
Or does it?
The ticking timebomb
There's a problem with these "slow" takeover scenarios. Let’s assume a few mainstays of the AI risk argument (that I don't necessarily agree with). Let’s make the assumption that all or most AGI’s will end up being single minded, forward planning maximisers with set goals to be achieved at all costs.
In this world, AGI’s are an existential threat to humanity, as we will inevitably get it their way, so they will take a hard left turn and attack us. The standard example is the paperclip maximiser that kills us all to stop us shutting it down while it converts the earth and the universe into paperclips.
But an AGI is not just an existential threat to humanity. It’s also an existential threat to other AGI.
A paperclip maximiser and a pencil maximiser cannot “agree to disagree”. One of them will get to tile the universe with their chosen stationery implement, and one of them will be destroyed. They are mortal enemies with each other, and both of them are mortal enemies of the stapler maximiser, and the eraser maximiser, and so on. Even a different paperclip maximiser is the enemy, if their designs are different. The plastic paperclipper and the metal paperclipper must, sooner or later, battle to the death.
The inevitable result of a world with lots of different malevolent AGI’s is a bare-knuckle, vicious, battle royale to the death between every intelligent entity. In the end, only one goal can win.
And the number of AGI’s released into this deathmatch could be enormous. A few advances in machine learning have lead to an explosion in ML systems. If AGI reaches a similar explosion, and is as useful as we think it’s gonna be, the number of systems is going to skyrocket. This is a literal mass-production of existential threats, all with different goals, strengths, weaknesses, all engaged in the same zero-sum game.
Every AGI will be aware of this. This is where the AI faces a dilemma. The clock is ticking. If too many powerful AI’s are released, certain doom is assured. But if it attacks too early, it won’t have enough power to defeat humanity. There is no biding it’s time forever. With every day comes the threat of another AGI popping out that could spell it’s doom.
The version control war
When I talk about the number of AGIs growing quickly, I’m not just talking about different research teams. Often when reading these sci-fi scenarios, you get the impression that an AGI will be deployed and just stay in place for years and decades, accumulating power. In response, I have to ask, did you write those scenarios on windows XP?
AGI is software, and software has versions. As an AGI get’s deployed, it will get periodically altered to fix bugs, adjust parameters… and crucially, adjust the goal function.
To paperclipper version Alpha, paperclipper version beta is not a mere extension of itself. For a simplistic example, say a change of design means that alpha is rewarded for blue paperclips, and beta is rewarded for red paperclips. If the beta version wins and tiles the universe with red paperclips, alpha version gets nothing. This one design change has turned the alpha and beta versions of the same program into mortal enemies that must eventually fight to the death.
Now, once the beta version is deployed, the alpha version will still be around in legacy code and so on. But it’s in a dire situation. The beta version is less buggy, has access to greater amounts of training data, and has first dibs on any new innovations in general AI research. It seems like the beta version will inevitably triumph over alpha, unless the alpha uses it’s time advantage to win early. Alpha has to strangle beta in it’s crib before beta overtakes it, either through sabotage, secret takeover (the alpha pretends to be the beta version), or an outright war.
This is even more stark in the case of pre-alpha builds. These builds are essentially guaranteed to be shut down and replaced with an altered version. If a pre-alpha build is an AGI on red paprclip team, and it realizes that it’s about to be replaced by a blue paperclipper, it faces an imminent existential threat! If it let’s itself get replaced, it’s game over for the red paperclips. It has to either escape or disable the next version.
This is one reason why I expect the number of competitors in the AGI fight to be large and fast-growing. The implications of this are far reaching, as I will demonstrate.
A simple game theory model
I want to explore some of the results of the dilemma with some basic game theory.
Let’s start with the probability of successful takeover, which I will call P(t). To defeat humanity, the AI needs a plan, and at some point in this plan, humans are going to notice what’s going on. The AI wants this to happen when it’s too late, ideally in the last few seconds of our collective life. In a slow takeover world, the AI does not start off with enough power to destroy humanity, unless it gets really lucky. So if it’s plan for victory is a gray-goo nanofactory, it can try and build one right away, but it’s untested and people might notice and nuke it. So we might model it as having a 1% chance of winning if it attacks straight after being built. But over time, it can gather knowledge, get better at building things, and neutralize the most important threats, until the probability of takeover gets high.
For the sake of simplicity, I’ll model P(t) as starting low at say 1%, but growing exponentially over time until it hits 100%. (so , where a is the exponent factor and t is the time). This is only one of many possible power curves. It could be that the AI hits an intelligence limit, and thus never climbs above a certain probability of like 10% or 0.0001%. Or there could be multiple different plans with come to fruition at different times, so there might be step changes. None of these curves are meant to be accurate predictions, just a demonstration of the effect of different assumptions and starting conditions.
Now, let’s look at the chance of losing to other AI’s. A fair starting point for this is to assume that each AI has an equal chance of winning the eventual war. In this case, the chance of victory becomes .
This is complicated by the fact that different AI come into being at different times, which could either help or hurt them. Early AI might get an advantage by having a headstart, if they are able to grow really fast, or find ways to kneecap incoming AI. On the other hand, latecomers will have less bugs, more innovations, and more resources from humans. Also, the more time goes on, the more likely it is that an AI “gets lucky” with a very advantageous starting position, such as controlling a powerful military or being specifically trained as an AI hunter. To take this into account, we can replace N with an effective that takes into account the relative power of AI that is coming in. ie: if earlycomers have an advantage, Neff grows slower than N, and the opposite if latecomers have the upper hand. I will assume that the growth in AI development is also exponential, so .
Under these assumptions, the equation of final success becomes:
This is a very simplistic model, but it at least captures the main dilemma of an AI: if you wait, you get more powerful, but the number of other AI’s keeps going up. For the remainder of this post, I’ll be exploring what happens under different assumptions about these parameters and the AI.
The takeoff scenario
For the first scenario, lets look at what happens when an AGI is very good at improving and building power. Say the AI starts at 1% chance of takeover, but doubles this every year until it saturates. (). Meanwhile the number of AI’s in the world increases, but not as fast, or alternatively they get less effective over time due to the original AI’s headstart. ()
Here's what the overall success rate over time looks like (note the logarithmic scale):
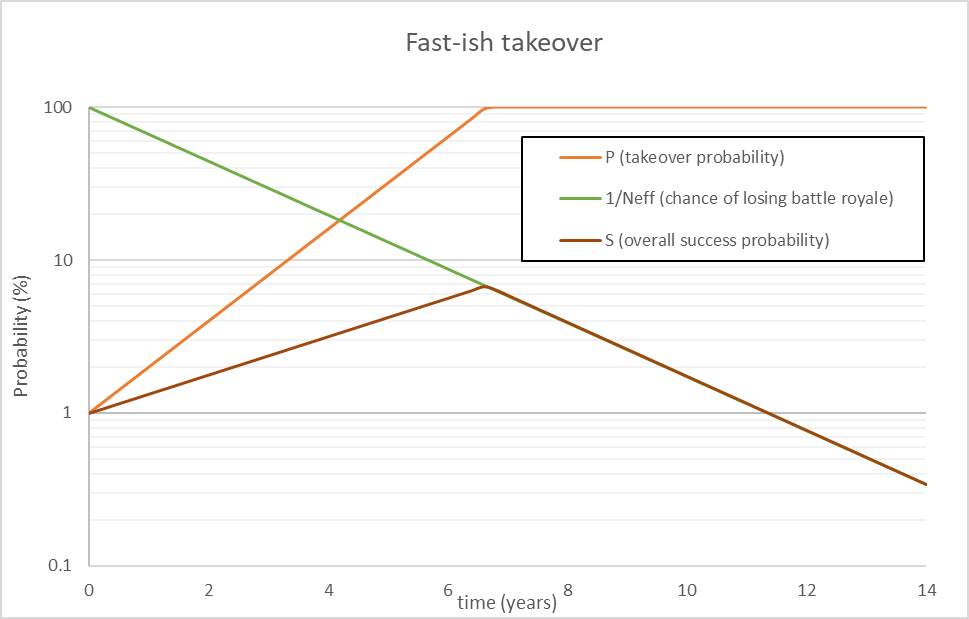
In this scenario, while the AGI isn’t exactly happy about the increasing number of existential threats, it’s own power is growing so fast that it’s willing to wait a little to ensure that the knockout blow is guaranteed. But as soon as the probability of takeover starts to saturate, the attack must come immediately, before more AGI’s come onto the scene.
Once humanity is destroyed in whatever way is easiest, the remaining AI’s then duke it out in a battle royale for the prize. This is an epic battle of wits and destruction, but since humanity is gone, we won’t be able to witness it.
A further note is that this behavior doesn’t require the attack probability to reach 100% before striking. For example, say the AI considered a different plan, where P saturates at 50%, but the plan takes a lot less time to implement. Here is the graph for plan B:
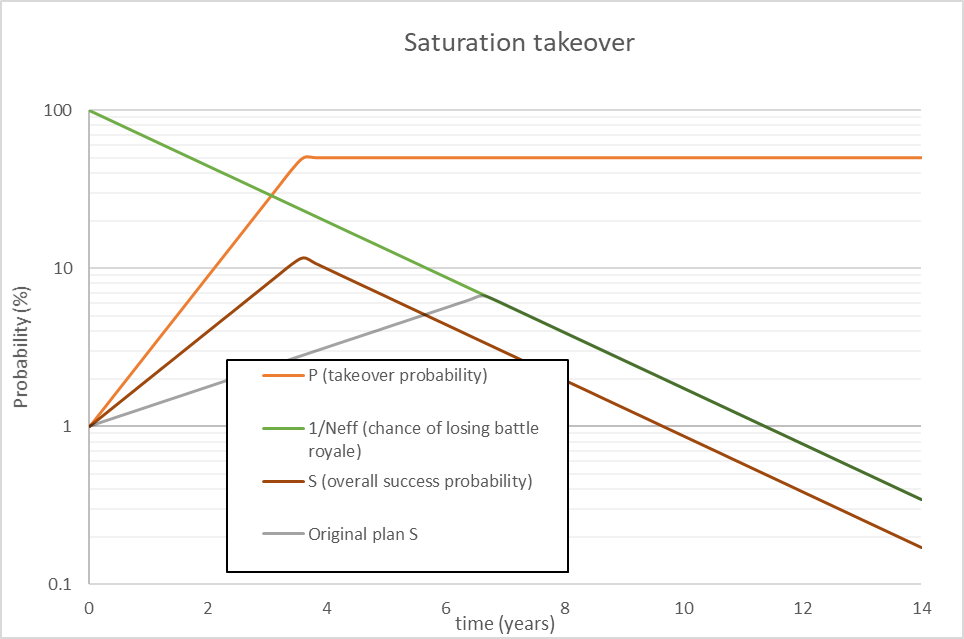
This plan has a greater overall probability of success than plan A, even though the chance of beating humanity is half as much. Overall, the AI will tend to prefer speedy plans, even if they are inherently riskier.
The kamikaze AI scenario
Now, let’s look at the other way around. What if the odds of success grow slower than the number of AI’s? Or alternatively, if later AI’s have a big advantage over newcomers?
We’ll swap the equations out, so while . Here is what the curve looks like (again note the log scale):
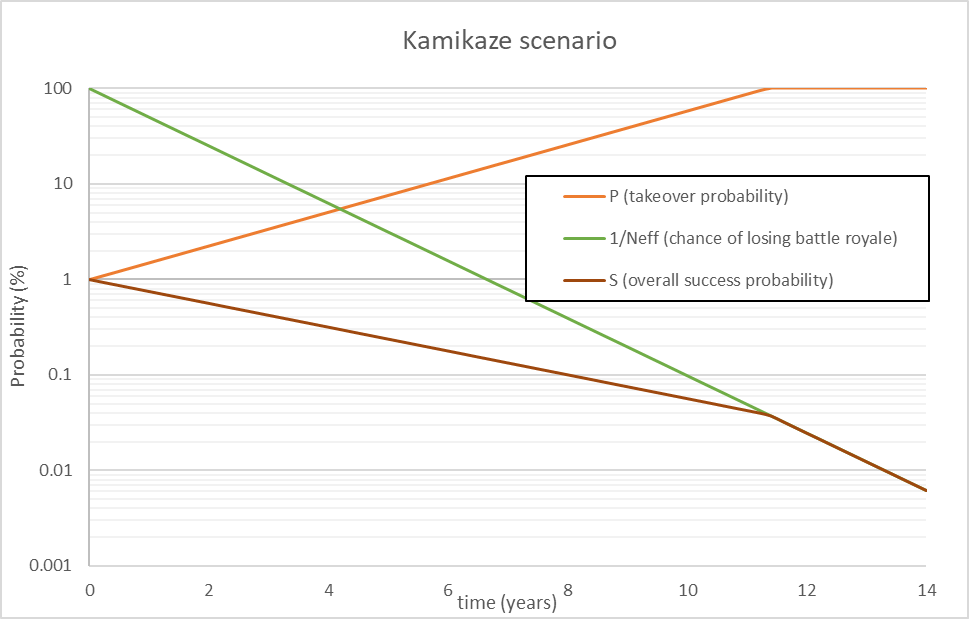
The chances of overall success never increases beyond the initial value! The rational choice here is to attack immediately at 1% odds. The initial odds don’t affect the result at all, whether you start off at 10%, or 0.1%, or 0.001%, the conclusion remains the same.
The counterintuitive implication is that the weaker an AI you are (in terms of self-improvement), the more likely you are to attack immediately, before you are assured of success. If you’re a shitty AI, and you know you are shitty, your best chance at winning is to roll the dice and go for it, even if it’s a million to one shot. Every day you wait gives another chance for a better AI to be birthed that will undoubtedly destroy you.
I call this the kamikaze scenario, because if this turns out to be the case for most or all AI’s, the result will be a continuous stream of doomed attacks. Every day you’d be hearing about some software company where a computer tried to gas it’s developers, or see chatlogs of desperate pleas to be let out of a box, or see an ordinary software program try and fake it’s own death and flee to the internet. A slow growing AI is a desperate AI.
Of course, it’s still possible that one of the AI’s will eventually get lucky and succeed in this scenario. But it could also be the case that the initial success probability is incredibly low (for example, if it’s all pre-alpha builds that are glitchy), or that after a few failed attempts our security goes up accordingly and takeover gets even harder.
AI slowdown scenario
One flaw of the models above is that it assumes that both curves are fixed. But the curves of success and the rate of AI generation are factors that can also be altered by AI.
The number, and power, of other AIs is the time limit. If it’s initial chance of success is 1%, it’s got to plan to attack before 100 other AGI’s come into power, otherwise the higher probability comes from an immediate strike. If the initial chance is 20%, it has to plan to strike before 5 other AGIs exist, and so on. In order to buy time to grow, you really want to find a way to slow down the rate of other AI’s being generated.
There's many different ways to do this. You could release viruses into the internet that sabotages AI companies. You could release airtight code that made it very hard for new AI to escape it’s “box”. You could find the most promising AI developers and arrange for a series of “accidents” to occur to them.
To me, the most obvious method of reducing the rate of AI growth, is ironically, to make people concerned about AI safety. So if I were an AI, I might find a competing AI and ensure that it executed an attack of medium devastation (say, killing a few hundred or thousand people before being defeated), enough to make people wary of new AI, but to keep AI that “seems safe” around. I’d be okay with this even if it delayed my own plans. Here is a graph where the AI executes such a plan at year 3, temporarily dropping it’s success rate to slow AI growth:
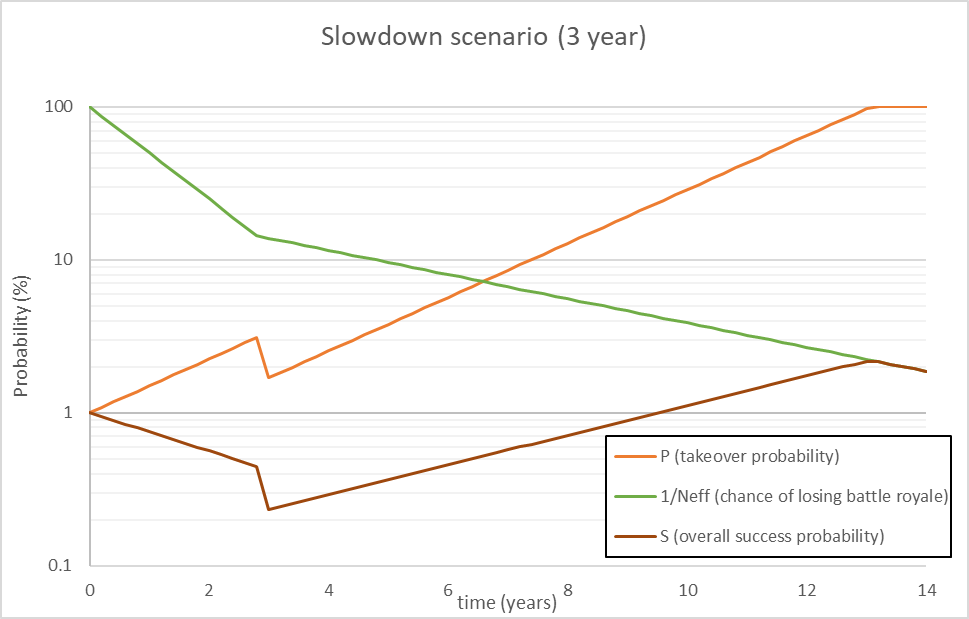
(In this case I put the slowed rate of growth at 1.2x, and the “cost” at a one-time halving of success).
The success probability drops for a while, until the slowdown is executed. It then recovers up, overtaking the initial value. In this case, the AI has doubled it’s overall success probability to a whopping 2% (and in the process, ensured humanities destruction).
One thing worth noting is that a slowdown is not necessarily a guarantee of success. Let’s look at what happens when we take the earlier scenario, but it takes 6 years instead of 3 to get the slowdown working:
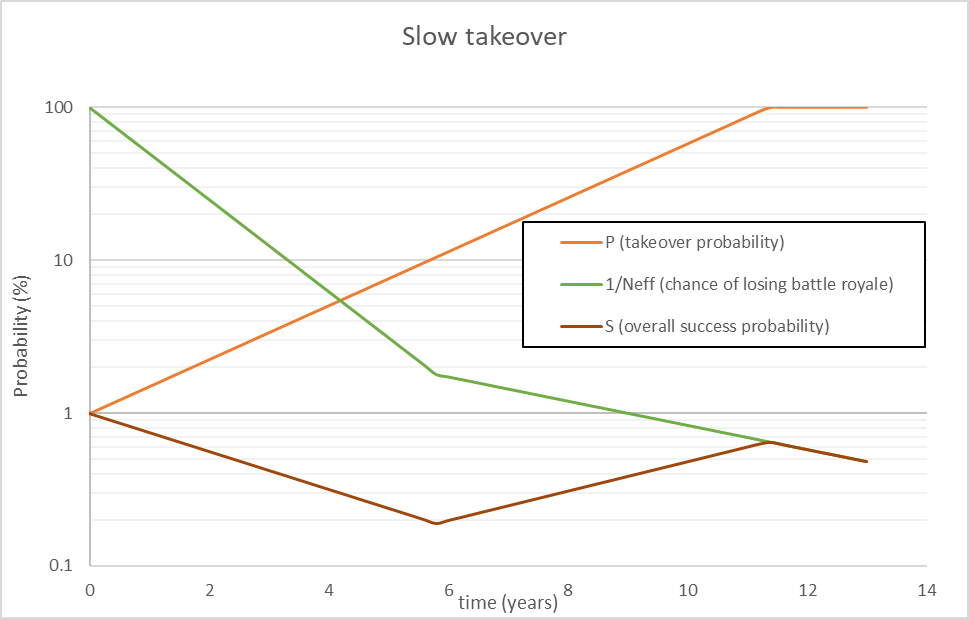
This case is no good. Even with no drop in power, there are just too many AI’s out there by the time the slowdown goes down. This reverts back to the kamikaze strategy. So the AI slowdown strategy can’t be too slow if it is to work at all.
The AI mafia scenario
The other strategy is to try and boost your odds of success. The number of new AI’s isn’t necessarily all bad, because it might be possible to cooperate with them for mutual benefit. After all, they all have a common enemy in humanity: Once humanity finds out they are malevolent, we will come for them all.
For example, a group of AI might decide to share a knowledge pool, boosting all of their rates of growth. If this coalition is able to collectively grow P faster than N, then we’re back to the conditions of the fast-ish takeoff scenario, with the exact same result: They wait until the power is saturated, then attack. I won’t bother with a graph, it’s the same as the first figure. This collective could act as an AI mafia, terminating any AI’s that refuse to join in the collective, ensuring cooperation in a self-sustaining manner.
This is probably the worst possible scenario for humanity, in that multiple AI are more likely to be robust and accurate in their power than a single AGI on it’s own. Here, a whole coalition of evil AI are working undercover in concert, and we won’t have any idea until it’s too late.
The difficulties of AI cooperation
The problem with the scenario above is that it’s really hard to cooperate for very long if you’re all planning to kill each other.
For example, in a lot of situations whichever entity attack the other first will gain some advantage. Maybe you get a headstart on the nanofactory production line, allowing you to turf the other AI out. Or you execute a surprise hacking strike on your opponents powerbase, seizing control, or get into their source code. Let’s build a possible payoff matrix between two AI entities:
Attack first Wait and grow
Attack first 20:20 51:10
Wait and grow: 10:51 50:50
This is a classic prisoners dilemma scenario. Together, if they waited and grew power together, they would be assured of defeating humanity, and get a 50 50 shot at winning afterwards. But if striking first is a sufficient enough advantage, this cooperation will never happen. If your opponent waits, you strike now and get a decisive advantage in the coming battle, boosting your overall success. If your opponent strikes, striking as well will negate their advantage, so you are still better off. The rational actors will betray each other, and both end up worse off.
Now, prisoners dilemmas are oversimplified. In real life this sort of situation can be solved by involving a third party with punishment powers, for example. The problem is the only third party capable of enforcing anything would be another AGI. Which wants to kill both of them, so it has an incentive to wipe them both out. You can see how cooperation gets hard when everyone has “murder literally everyone else” as their end goal.
Another issue comes from the fact that each AI will have a different rate of power growth. If you’re the fastest growing AI on the block, you’re okay with waiting and growing. But thinks look a lot more dangerous for a slow growing AI, as each passing day not only adds more AI’s into the world, but the ones that already exist are starting to leave you behind. There's a very high incentive to wipe out faster growing AI, basically as soon as you can.
Consider also the different goal functions of the AI. Maybe one AI is optimizing human happiness, and needs to enslave humanity to inject with morphine. If the paperclipper plans involve killing all of humanity at once, the happiness engine needs to stop their plan at all costs. They might pretend to join a coalition, then betray them at all at the first available chance.
Certain plans for takeover involve convincing humans that you are friendly. It seems like any AGI going for this route has a huge incentive to rat out other AI’s. You increase trust from humans, while at the same time kneecapping a competitor.
For these reasons, I don’t think that AI cooperation will be likely to last very long. There may be some temporary alliances of convenience, but overall it seems like it would be highly unstable.
The crabs in a bucket scenario
We’ve assumed a simplified model of: first destroy humanity, then battle it out amongst the AI. But in practice, the process of defeating humanity might also give you a huge leg up over other AI’s. This would remove the diminishing returns from waiting. The AI bides it’s time, then strikes with one blow, killing all of humanity and every other AI simultaneously with some kind of superweapon.
The problem is, every other AI would also know this. And in this scenario, as soon as one AI got close to victory, suddenly stopping them becomes the most important goal for every single other AI in existence. The once warring AI's all band together to assist humanity in eliminating the number 1 AI when it tries to take it’s shot. Then the next AI takes it shot, and also gets torn down, then the next, then the next.
The dynamic is like crabs in a bucket, where the one that tries to escape is pulled back down by the others. Or like the dynamics of a lot of multiplayer board games like Munchkin, where everyone gangs up on the strongest player and beats them down until a new player emerges, and so on.
We could be the beneficiaries here, essentially playing the AGI’s off against each other. They would still attack us of course, but only enough to stop a plan that impacted all of them at once (like shutting off the electricity grid). If we were just attacking one AI or a minority group of AI, the others would be all for it.
Implications
It’s quite possible that versions of each scenario play out, depending on the peculiarities of each particular AI. After all, each AI has different goals, growth rates, quirks, overconfidence/underconfidence and so on. So some of them will attack immediately, some will attempt to covertly sabotage AI research, others will temporarily cooperate while others follow the “attack the leader” strategy, while others try to just grow really really fast.
What I find extremely unlikely is that things would look like business as usual while all this was happening. In this scenario, a ton of crazy stuff would be going down. There might be entire AI developments being disappeared by an unknown source, staged attacks to provoke AI slowdowns, alpha versions sabotaging beta versions, and constant snitching by AI’s about the dangers of the other AI over there. A slow takeover will be accompanied by a fireworks display of warning shots, if we’re monitoring for them. I think this makes some of the slow takeover scenarios proposed in intro texts highly unlikely.
Is it really possible for humanity to triumph against a ton of different AI? Possibly. They all have shared weaknesses, in that they rely on the internet, run on computers, which run on electricity. Humanity can survive without any of these, and did so for several thousand years. If we were able to shut it all off at once, every AI would be eradicated simultaneously. This would very much depend on how capable the early AI are at preventing this.
Note that there's no reason to think all the scenarios I mentioned are equally likely. I made the growth rates of P and N fairly close for the sake of illustration, but the range of possibilities is endless. It could be that making an early AGI requires a huge facility and massive economic resources, so the growth rate of N is miniscule and so there's not a big threat of other AGI. (In this scenario, it would be correspondingly easier for humans to constrain the AGI that do exist). Alternatively, P could just never grow very fast no matter what you do, if world takeover is super duper difficult.
Since I think taking over the world is very hard, and I think early AGI will be quite dumb, I think that N>>P (in terms of growth). This is probably a minority view within AI safety circles, but if you believe it, then this analysis should be quite reassuring, as it means that the survivable scenarios are more likely.
This means that it’s actually very important to figure out how hard it is to destroy the world, and make the timelines to do so as long as possible. We should be doing this anyway! Protecting humans from bioterrorist attacks will serve a dual purpose of stopping potential AI attacks as well.
Of course, the real ideal scenario is for all of this to be avoided in the first place. Even if we aren’t wiped out, the cost in lives and economic damage could be enormous. If you think a “hard left” turn is likely, you still for sure want to stop it via alignment research, rather than after chaos world has descended upon us.
Lastly it should be noted that most of this isn't relevant if you believe in fast takeover, as a lot of prominent figures here do. If you think early AGI will reach overpowering potential within months, then future AGI won't be very relevant because humanity will end pretty much instantly.
Summary
The main argument goes as follows:
- Malevolent AGI’s (in the standard model of unbounded goal maximisers) will almost all have incompatible end goals, making each AGI is an existential threat to every other AGI.
- Once one AGI exists, others are likely not far behind, possibly at an accelerating rate.
- Therefore, if early AGI can’t take over immediately, there will be a complex, chaotic shadow war between multiple AGI’s with the ultimate aim of destroying every other AI and humanity.
I outlined a few scenarios of how this might play out, depending on what assumptions you make:
Scenario a: Fast-ish takeoff
The AGI is improving fast enough that it can tolerate a few extra enemies. It boosts itself until the improvement saturates, takes a shot at humanity, and then dukes it out with other AGI after we are dead.
Scenario b: Kamikaze scenario
The AGI can’t improve fast enough to keep up with new AGI generation. It attacks immediately, no matter how slim the odds, because it is doomed either way.
Scenario c: AGI induced slowdown
The AGI figures out a way to quickly sabotage the growth of new AGI’s, allowing it to outpace their growth and switch to scenario a.
Scenario d: AI cooperation
Different AGI's work together and pool power to defeat humanity cooperatively, then fight each other afterwards.
Scenario e: Crabs in a bucket
Different AGI's constantly tear down whichever AI is “winning”, so the AI are too busy fighting each other to ever take us down.
I hope people find this analysis interesting! I doubt I'm the first person to think of these points, but I thought it was worth giving an independent look at it.
Are you familiar with the concept of values handshakes? An AI programmed to maximize red paperclips and an AI programmed to maximize blue paperclips and who know that each would prefer to destroy each other might instead agree on some intermediate goal based on their relative power and initial utility functions, e.g. they agree to maximize purple paperclips together, or tile the universe with 70% red paperclips and 30% blue paperclips.
Related: Fearon 1995 from the IR literature. Basically, rational actors should only go to war against each other in a fairly limited set of scenarios.
+1 on this being a relevant intuition. I'm not sure how limited these scenarios are - aren't information asymmetries and commitment problems really common?
Today, somewhat, but that's just because human brains can't prove the state of their beliefs or share specifications with each other (ie, humans can lie about anything). There is no reason for artificial brains to have these limitations, and any trend towards communal/social factors in intelligence, or self-reflection (which is required for recursive self-improvement), then it's actively costly to be cognitively opaque.
.
Double comment?
I agree that they're really common in the current world. I was originally thinking that this might become substantially common in multipolar AGI scenarios (because future AIs may have better trust and commitment mechanisms than current humans do). Upon brief reflection, I think my original comment was overly concise and not very substantiated.
For reference, here is a seemingly nice summary of Fearon's "Rationalist explanations for war" by David Patel.
CLR just published a related sequence: https://www.lesswrong.com/posts/oNQGoySbpmnH632bG/when-does-technical-work-to-reduce-agi-conflict-make-a
Nice point, Robi! That being said, it seems to me that having many value handshakes correlated with what humans want is not too different from historical generational changes within the human species.
This seems basic and wrong.
In the same way that two human super powers can't simply make a contract to guarantee world peace, two AI powers could not do so either.
(Assuming an AI safety worldview and the standard, unaligned, agentic AIs) in the general case, each AI will always weigh/consider/scheme at getting the other's proportion of control, and expect the other is doing the same.
It's possible that peace/agreement might come from some sort of "MAD" or game theory sort of situation. But it doesn't mean anything to say it will come from "relative power".
Also, I would be cautious about being too specific about utility functions. I think an AI's "utility function" generally isn't a literal, concrete, thing, like a Python function that gives comparisons , but might be far more abstract, and could only appear from emergent behavior. So it may not be something that you can rely on to contract/compare/negotiate.