Crossposted from LessWrong.
Many thanks to Spencer Greenberg, Lucius Caviola, Josh Lewis, John Bargh, Ben Pace, Diogo de Lucena, and Philip Gubbins for their valuable ideas and feedback at each stage of this project—as well as the ~375 EAs + alignment researchers who provided the data that made this project possible.
Background
Last month, AE Studio launched two surveys: one for alignment researchers, and another for the broader EA community.
We got some surprisingly interesting results, and we're excited to share them here.
We set out to better explore and compare various population-level dynamics within and across both groups. We examined everything from demographics and personality traits to community views on specific EA/alignment-related topics. We took on this project because it seemed to be largely unexplored and rife with potentially-very-high-value insights. In this post, we’ll present what we think are the most important findings from this project.
Meanwhile, we’re also sharing and publicly releasing a tool we built for analyzing both datasets. The tool has some handy features, including customizable filtering of the datasets, distribution comparisons within and across the datasets, automatic classification/regression experiments, LLM-powered custom queries, and more. We’re excited for the wider community to use the tool to explore these questions further in whatever manner they desire. There are many open questions we haven’t tackled here related to the current psychological and intellectual make-up of both communities that we hope others will leverage the dataset to explore further.
(Note: if you want to see all results, navigate to the tool, select the analysis type of interest, and click ‘Select All.’ If you have additional questions not covered by the existing analyses, the GPT-4 integration at the bottom of the page should ideally help answer them. The code running the tool and the raw anonymized data are both also publicly available.)
We incentivized participation by offering to donate $40 per eligible[1] respondent—strong participation in both surveys enabled us to donate over $10,000 to both AI safety orgs as well as a number of different high impact organizations (see here[2] for the exact breakdown across the two surveys). Thanks again to all of those who participated in both surveys!
Three miscellaneous points on the goals and structure of this post before diving in:
- Our goal here is to share the most impactful takeaways rather than simply regurgitating every conceivable result. This is largely why we are also releasing the data analysis tool, where anyone interested can explore the dataset and the results at whatever level of detail they please.
- This post collectively represents what we at AE found to be the most relevant and interesting findings from these experiments. We sorted the TL;DR below by perceived importance of findings. We are personally excited about pursuing neglected approaches to alignment, but we have attempted to be as deliberate as possible throughout this write-up in striking the balance between presenting the results as straightforwardly as possible and sharing our views about implications of certain results where we thought it was appropriate.
- This project was descriptive and exploratory in nature. Our goal was to cast a wide psychometric net in order to get a broad sense of the psychological and intellectual make-up of both communities. We used standard frequentist statistical analyses to probe for significance where appropriate, but we definitely still think it is important for ourselves and others to perform follow-up experiments to those presented here with a more tightly controlled scope to replicate and further sharpen the key results we present here.
Seven key results and implications
Here we present each key result, ordered by perceived relevance, as well as what we think are the fundamental implications of that result. We hyperlink each result to the associated sections in this post for easier navigation.
(Please note that there are also a bunch of miscellaneous results that people have found interesting that are not included in this list or in the main body of the piece.)
- Alignment researchers don't think the field is poised to solve alignment
- Result: Alignment researchers generally do not believe that current alignment research is on track to solve alignment and do not think that current research agendas exhibit strong coverage of the full space of plausible alignment approaches. However, alignment researchers did prove impressively accurate at predicting the research community’s overall views on the relative promise of various technical alignment research directions (as systematized by Shallow review of live agendas in alignment & safety).
- Implications: Alignment researchers’ general models of the field are well-calibrated, but the fact that they don’t think the field is on track to solve alignment suggests that additional approaches should be pursued beyond what is currently being undertaken—a view which was also echoed continuously throughout alignment researchers’ free responses. We think this results lends additional credence to pursuing neglected approaches to alignment.
- Capabilities and alignment research not viewed as mutually exclusive
- Result: Alignment researchers generally disagree with statements like ‘alignment research that has some probability of advancing capabilities should not be done’ and ‘advancing AI capabilities and doing alignment research are mutually exclusive goals.’ Interestingly, researchers also erroneously predicted that the community would generally view safety and capabilities work as incompatible.
- Implications: This finding merits a more precise follow-up and discussion to better understand what exactly alignment researchers believe the relationship is and ideally should be between AI alignment and capabilities research—especially given that roughly two-thirds of alignment researchers also seem to support pausing or slowing AI development. Our general interpretation of this cluster of findings is that alignment researchers believe that capabilities research is proceeding so quickly and aggressively that the probability of alignment research being a meaningful contributor to further capabilities speed-ups is actually low—despite mispredicting that other alignment researchers would view this probability as higher. This alignment-versus-capabilities position is potentially quite action-guiding for policy efforts as well as technical alignment work.
- Overestimating the perceived value of intelligence, underestimating 'softer' skills
- Result: We find in both the EA and alignment communities—but more dramatically in the EA sample—that respondents significantly overestimate (e.g., by a factor of ~2.5 for EAs) how much high intelligence is actually valued in the community. EAs also tend to underestimate how much the community actually values ‘softer’ skills like having a strong work ethic, ability to collaborate, and people skills.
- Implications: Those in charge of hiring/funding/bringing people into these communities should consider (at least as a datapoint) what skills and traits are actually most valued within that community. They should probably treat high intelligence as something more like a necessary-but-not-unilaterally-sufficient trait rather than the ultimate criterion. We agree that softer skills like a strong work ethic and a strong ability to collaborate can render highly intelligent individuals dramatically more effective at driving results[3].
- EAs are not collectively aligned about longtermism
- Result: The EAs we sampled (actively involved across 10+ cause areas) generally seem to think that AI risk and x-risk are less promising cause areas than ones like global health and development and animal welfare—despite the EA community’s own strong predictions that EAs would consider AI risk and x-risk to be the most promising cause areas. EAs also predicted the EA community would view its own shift towards longtermism positively, but the community’s actual views on its own longtermist shift skew slightly negatively.
- Implications: It is important to caveat this finding with the fact that, overall, EAs still view AI risk and x-risk as promising in an absolute sense, despite seeming to consider more ‘classic’ EA cause areas as relatively more promising overall. We think this result merits follow-up and independent replication and invites further discussion within the EA community about the optimal allocation of time, resources, attention, etc. between classic cause areas and longtermist ones.
- Alignment researchers think AGI >5 years away
- Result: Alignment researchers generally do not expect there to be AGI within the next five years—but erroneously predict that the alignment research community does generally expect this.
- Implications: Perceived timelines will naturally calibrate the speed and intensity of research being undertaken. If most AI safety researchers think they have >5 years to attempt to solve alignment, it might be worth funding and pursuing additional ‘expedited’ research agendas in the chance that AGI comes sooner than this.
- Moral foundations of EAs and alignment researchers
- Result: EAs and alignment researchers have reasonably distinct moral foundations. We tested a model of moral foundations that uses three factors: traditionalism, compassion, and liberty. While both communities place low value in traditionalism, EAs seem to value compassion significantly more than alignment researchers. By contrast, both communities are fairly normally distributed in valuing liberty, but alignment researchers tend to skew towards liberty and EAs tend to skew away from it.
- Implications: EAs may be more receptive to work with more straightforwardly humanitarian outcomes than alignment researchers (as is indeed demonstrated elsewhere in our results). In general, the generally-normally-distributed nature of both populations on the moral foundation of liberty suggests that this value is either considered orthogonal[4] to these communities' guiding philosophies (which seems less likely to us) or otherwise underexplored in relation to them (which seems more likely to us).
- Personality traits and demographics of EAs and alignment researchers
- Result: Both EAs and alignment researchers score significantly higher than the general population in neuroticism, openness, conscientiousness, extraversion (ordered here by the magnitude of the delta). EAs score significantly higher than alignment researchers in both agreeableness and conscientiousness. Males outnumber females 2 to 1 in EA and 9 to 1 in alignment. Both communities lean left politically and exhibit a diversity of other (albeit nonconservative) political views, but EAs appear to be significantly more progressive overall.
- Implications: Both communities’ heightened sensitivity to negative emotion and risk aversion may be part of what motivates interest in the causes associated with EA/alignment—but these traits may also prevent bold and potentially risky work from being pursued where it might be necessary to do so. Alignment researchers should also probably put explicit effort into recruiting highly qualified female researchers, especially given that current female alignment researchers generally do seem to have meaningfully different views on foundational questions about alignment.
Survey contents and motivation
We launched two surveys: one for technical alignment researchers, and another for EA community members (who are explicitly not involved in technical alignment efforts). Both surveys largely shared the same structure.
First, we asked for general demographic information, including the extent to which the respondent has engaged with the associated community, as well as the nature of the role they currently play in their community.
Next, we had respondents answer a series of Likert scale questions from a set of well-validated psychometric scales, including the Five Factor Model (‘Big Five’), an updated version of the Moral Foundations Questionnaire (MFQ), and a number of other miscellaneous scales (probing things like risk-taking, delay discounting, self-control, and communal orientation). We included these questions because we think it is important to better understand the dominant cognitive and behavioral traits at play in the EA/alignment communities, especially with an eye towards how these mechanisms might help uncover what otherwise-promising research directions are currently being neglected.
In the final part of each survey, we asked people to respond on five-point Likert scales (strongly disagree, somewhat disagree, …, strongly agree) to statements related to specific topics in EA/alignment. These items were first framed in the general form ‘I think X’ (e.g., I think that effective altruism is a force for good in the world) and subsequently framed in the general form ‘I think the community believes X’ (e.g., I think the EA community as a whole believes that effective altruism is a force for good in the world).
Our motivation in this final section was two-fold: (1) we can straightforwardly understand the distribution of both communities’ views on a given relevant topic, but also (2) we can compare this ground truth distribution against individuals’ predictions of the community’s views in order to probe for false-consensus-effect-style results. Interestingly, we indeed found that both communities significantly mispredict their own views on key questions.
Who took these surveys?
Approximately 250 EAs and 125 alignment researchers. We recruited virtually all of these participants by simply posting on LW and the EA Forum, where we asked each community to fill out their associated survey via a simple Google Form.
We found that each sample includes people working across a wide diversity of research orgs and cause areas at varying levels of seniority. For instance, 18% of the alignment sample self-identifies as actively leading or helping to lead an alignment org, and significant numbers of EAs were sampled from virtually every cause area we listed (see plots below).
Here is the full list of the alignment orgs who had at least one researcher complete the survey (and who also elected to share what org they are working for): OpenAI, Meta, Anthropic, FHI, CMU, Redwood Research, Dalhousie University, AI Safety Camp, Astera Institute, Atlas Computing Institute, Model Evaluation and Threat Research (METR, formerly ARC Evals), Apart Research, Astra Fellowship, AI Standards Lab, Confirm Solutions Inc., PAISRI, MATS, FOCAL, EffiSciences, FAR AI, aintelope, Constellation, Causal Incentives Working Group, Formalizing Boundaries, AISC.
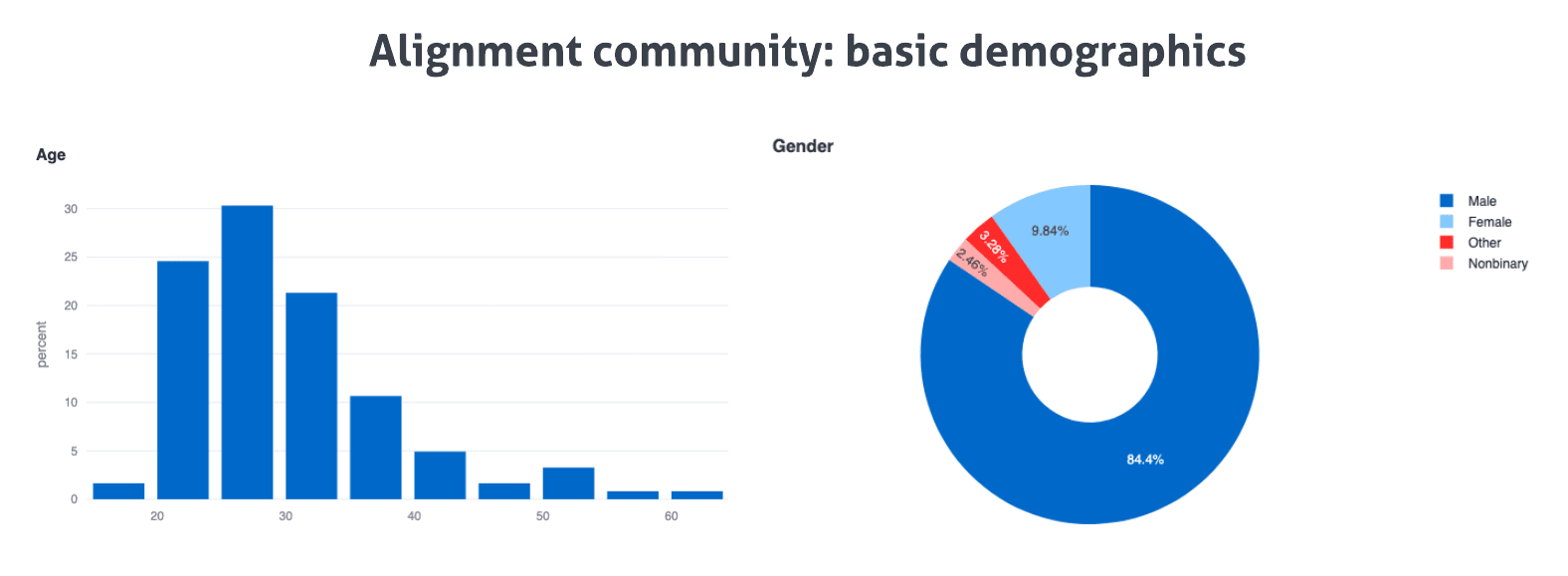
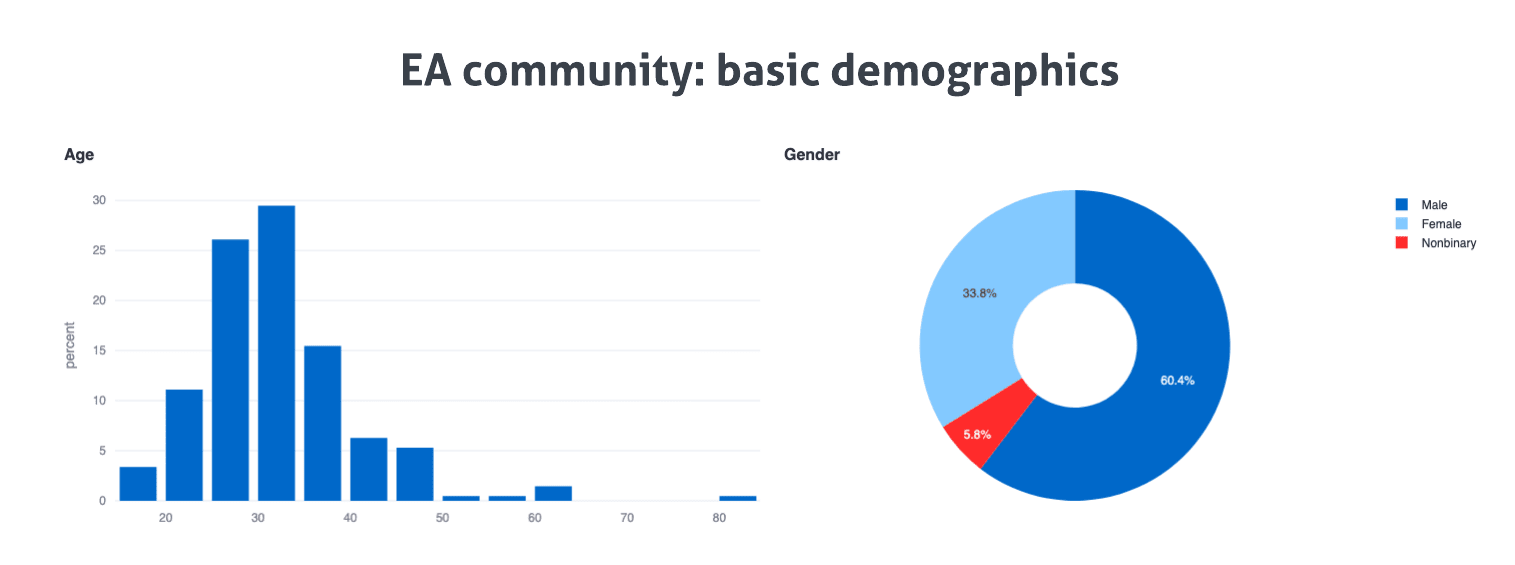
Of note, the majority of alignment researchers are under 30, while the majority of EAs are over 30. Males outnumber females approximately 2 to 1 in EA—but almost 9 to 1 in alignment. While this gender distribution is not unfamiliar in engineering spaces, it certainly seems worth explicitly highlighting, especially to the degree that male and female alignment researchers do seem to exhibit meaningfully different views about the core aims of alignment research (including, critically, the very question of whether alignment research explicitly requires an engineering-style background).
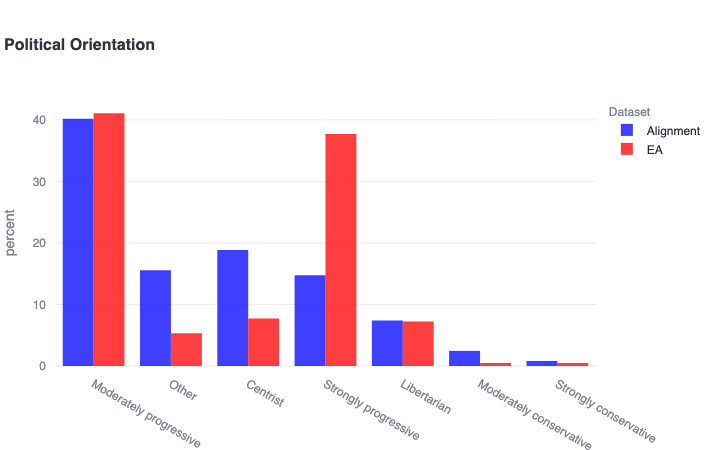
Overall, we find that approximately 55% of alignment researchers identify as politically progressive to some extent, while approximately 80% of EAs identify in the same way. While there appear to be a negligible number of self-identified conservatives in either community (n=4 in alignment, n=2 in EA), there do appear to be a diversity of other political views at play in both samples (including a significant number of highly unique written-in affiliations/leanings across both samples that we somewhat crudely lumped under ‘Other’). It is worth noting that the lack of self-identified conservatives could fuel similar problems as has been well-documented in academia, especially to the degree that policy advocacy is becoming an increasingly prominent cause area of both communities.
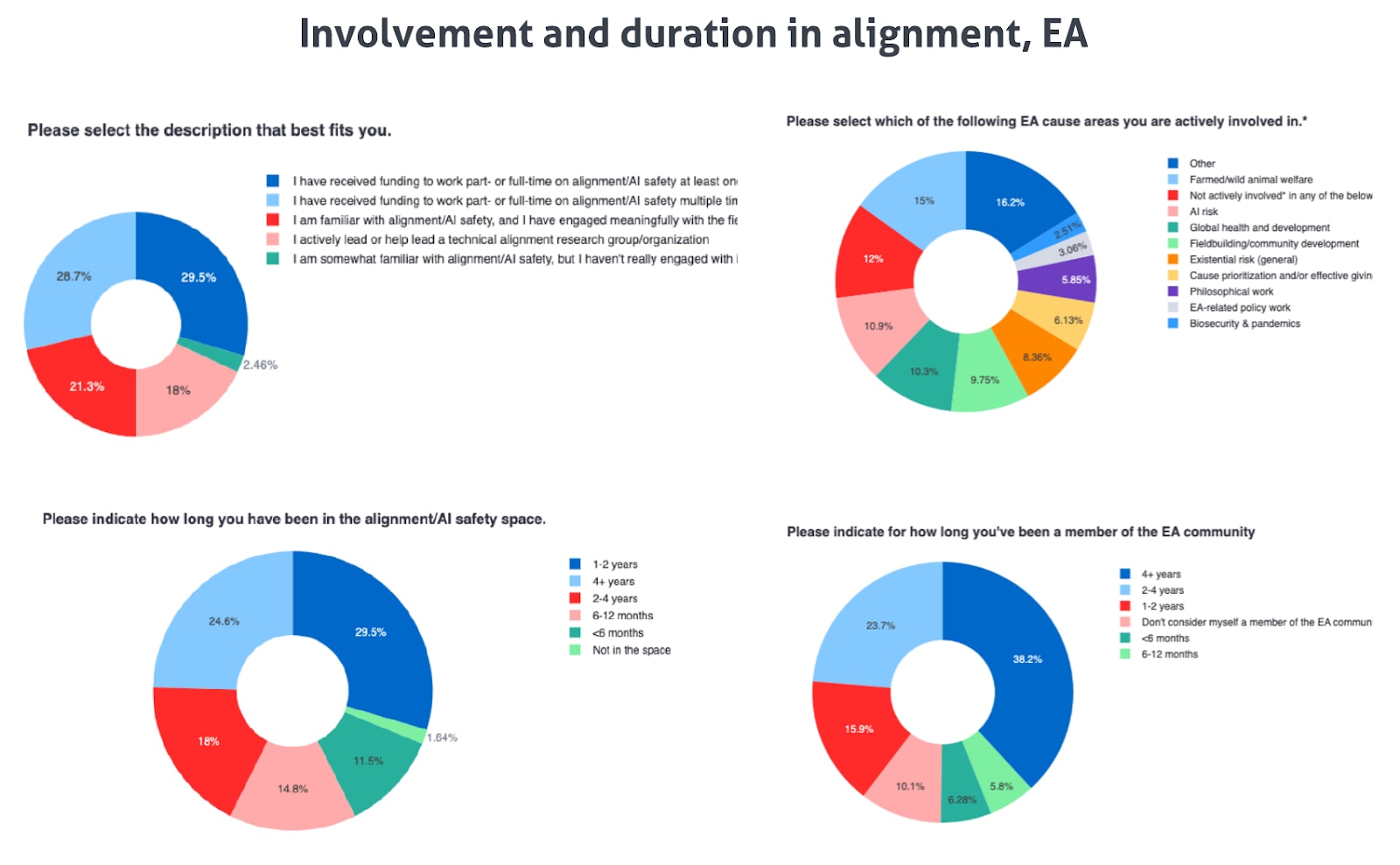
Roughly 65% of EA respondents and 40% of alignment researchers have been involved in the space for 2 or more years. EA respondents demonstrate significant diversity in the cause area in which they are actively involved, and the alignment dataset is shown to include researchers at various stages of their careers, including a significant sample of researchers who are actively leading alignment organizations.
(As with each part of this write-up, there are numerous additional results in this section to explore that are not explicitly called out here. We also want to call out that we generally opted to keep both samples intact in subsequent analyses and found that adopting additional exclusion criteria for either population does not statistically affect the key results reported here; the community can easily further filter either dataset however they see fit using the data analysis tool.)
Community views on specific topics (ground truth vs. predictions)
We asked each community to rate the extent to which they agreed with a number of specific claims in the general form, ‘I think X’ (e.g., I think EA is a force for good in the world). Later on, we asked respondents to predict how their community in general would respond to these same questions in the general form, ‘I think the EA/alignment community as a whole believes X’ (e.g., I think the EA community as a whole believes that EA is a force for good in the world). In this way, we position ourselves to be able to address two important questions simultaneously:
- What do the ground truth distributions of views on specific field-level topics look like within the EA and alignment communities?
- How do these ground truth distributions compare to the community’s prediction of these distributions? In slightly less statistical language—how well does each community actually know itself?
Cause area prioritization (ground truth vs. predictions)
We asked each community to rate the extent to which they considered a large number of relevant cause areas/research directions to be promising—and proceeded to compare these distributions to each community’s predictions of how others would respond in general.
EA community
For the sake of demonstrating this section’s key results as clearly as possible, we translate each available Likert scale option to a number of ‘points’ (‘very unpromising’ = -2, ‘somewhat unpromising’ = -1, …, ‘very promising’ = +2) and proceed to tally the total actual and predicted points allotted to each cause area/research direction. Presented with the core topics of effective altruism, here is how the EA community sample’s ground truth and predicted point allotments look:
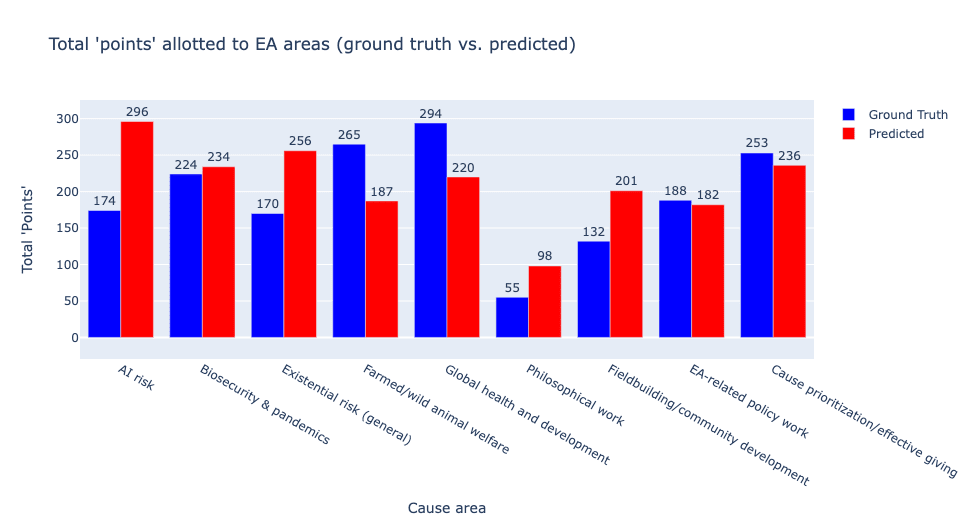
We find that EAs generally believe that global health and development, farmed/wild animal welfare, and cause prioritization/effective giving are the most promising cause areas—but EAs themselves thought that EAs would consider AI risk and general existential risk are most promising (predicted mean = 4.43, actual mean = 3.84; U = 14264, p ≈ 0). The magnitude of the misprediction here—particularly with respect to AI risk—was quite surprising to us (potentially by definition, given the nature of the result). To be clear, most EAs do think AI risk is ‘somewhat promising,’ but overwhelmingly predicted the community would consider AI risk ‘very promising.’ EAs’ generally lukewarm feelings towards longtermist causes are demonstrated in a few places in our results.
Interestingly, the causes that currently receive the most funding align more closely with the EA community’s predictions rather than the ground-truth distributions. It seems this misalignment may therefore be more straightforwardly understood as key funders like Open Philanthropy viewing x-risk as significantly more important than the general EA community, and EAs reflecting this preference in their perceptions of the community writ large.
(We personally consider it important to note here that we certainly don’t think funding alignment should be deprioritized, and that AI-related risks clearly qualify as essential to address under the ITN framework. We are excited that Open Phil plans to double its Global Catastrophic Risk (GCR) funding over the next few years. We ourselves wish that orders of magnitude more AI safety orgs, individual researchers, and for-profit AI-safety-driven businesses were being funded—and we suspect far more will be funded as AI development accelerates and the mainstream comes to care far more about making sure AI is built safely.[5])
Alignment community
By contrast, the alignment community proved impressively accurate at predicting their own views on the relative promise of various alignment research directions as captured by the rough factor structure presented in Shallow review of live agendas in alignment & safety:
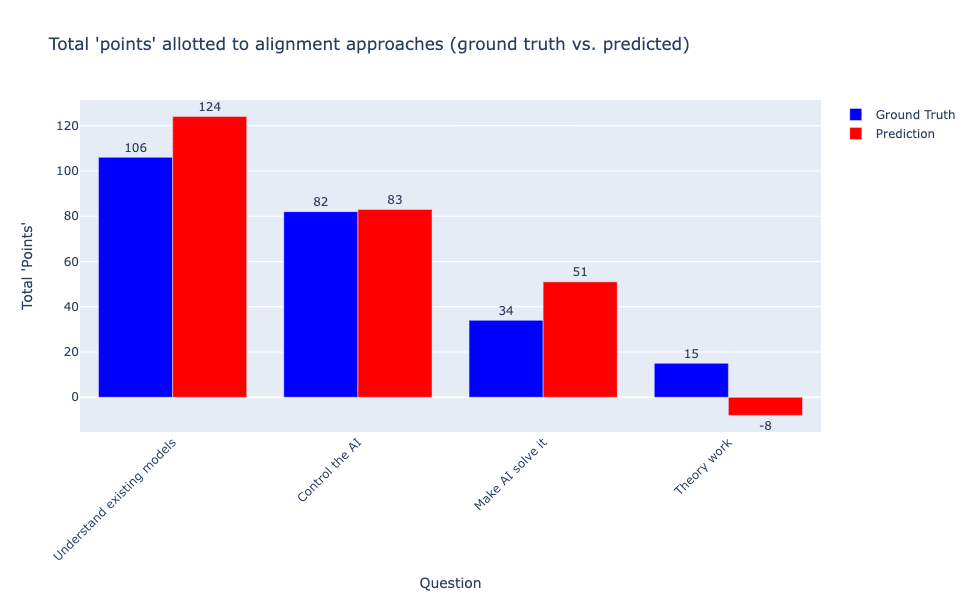
This result indicates that alignment researchers are most excited about evals and interpretability work, followed by various prosaic alignment approaches (eliminating deception, finetuning/model edits, goal robustness, etc.), are relatively less excited about ‘make the AI solve it’ approaches (the most prominent example being superalignment), and are even less excited about more theoretical approaches, including provably safe architectures, corrigibility, and the like. This result also clearly demonstrates that alignment researchers are well-calibrated in understanding that the community has this general prioritization.
As an organization that is particularly interested in pursuing neglected approaches (which would likely all fall into the unpopular ‘theory work’ bin), we certainly think it is worth cautioning (as many others did in free response questions) that this result only tells us what the idiosyncratic set of current alignment researchers think about what should be pursued within the general constraints of the Shallow review framework. We do not think it is valid to conclude from results like this that people should stop doing theory work and all become mechanistic interpretability researchers.
The prioritization here should also be tempered with the parallel findings that alignment researchers generally think (1) that current alignment research (i.e., everything encompassed by the Shallow review framework) is not on track to solve alignment before we get AGI, and (2) that the current research landscape does not demonstrate strong coverage of the space of plausible approaches:
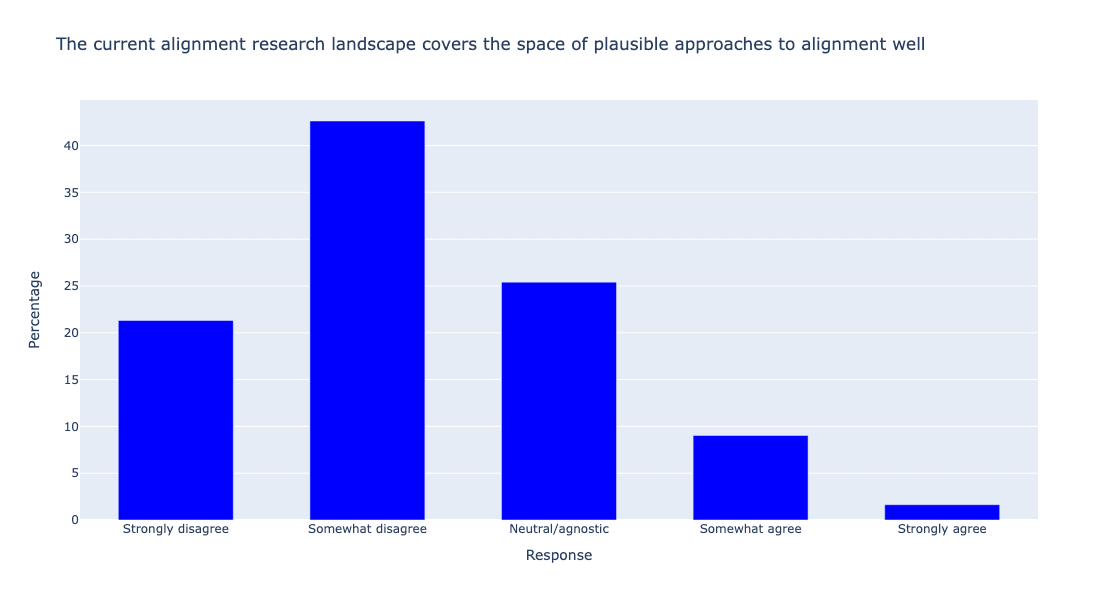
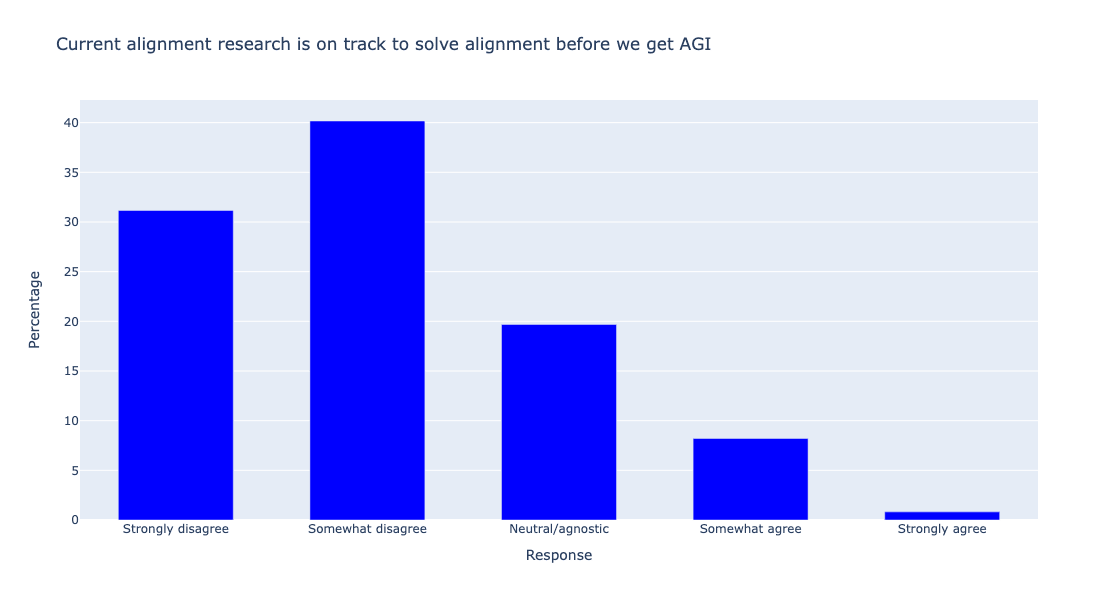
Taken together, these results reinforce to us that additional neglected approaches to alignment are very much worth identifying and pursuing. We suspect that alignment researchers are most excited about evals and interpretability work because they feel they can make more direct, tangible, measurable, and prestigious[6] progress in them in the short-term—but that these approaches appear to be something of a local optimum in the current research landscape rather than the global best strategy that will solve alignment.
Other interesting field-level distributions (ground truth vs. predictions)
In addition to cause/research area prioritization, we asked both communities to share the extent to which they agreed with a number of claims specific to their respective communities. All of these distributions are available here; in this section, we will only highlight and comment on what we think are the most relevant couple of results for each community.
EA community
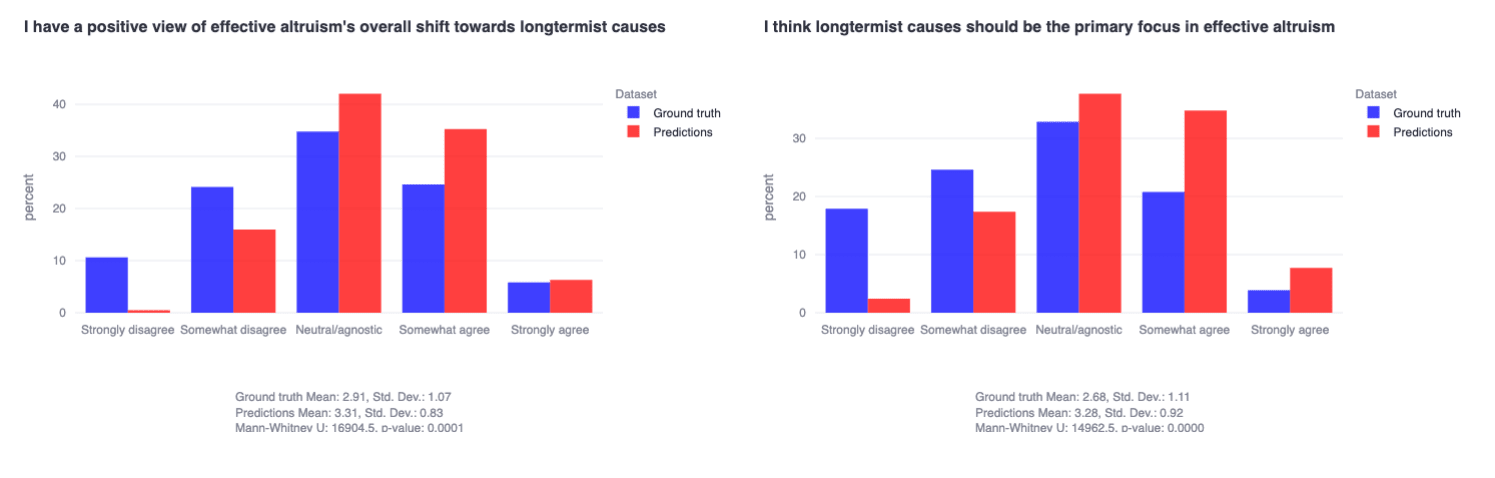
Dovetailing with the earlier EA cause area finding, we also find that EAs are fairly heterogeneous with a slight negative skew towards the related claims that longtermist causes should be the primary focus of EA and that EA’s shift towards longtermism was positive (for both, only ~25% agree to some extent)—but the community predicted a strongly positive skew (for both, that >40% would agree to some extent).
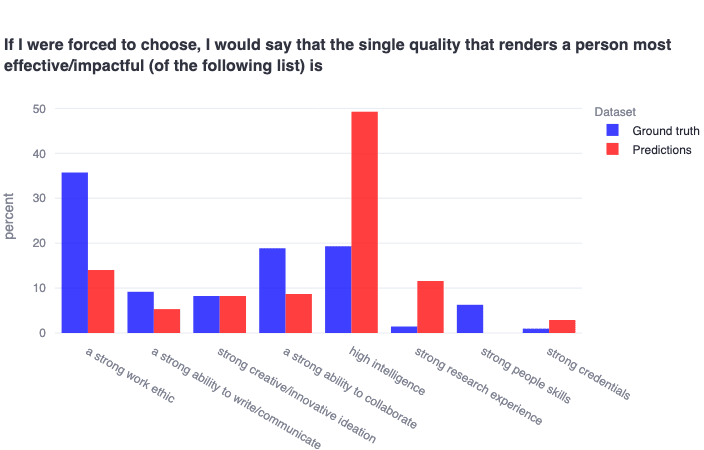
We also find in both datasets—but most dramatically in the EA community sample, plotted below—that respondents vastly overestimate (≈2.5x) how much high intelligence is actually valued, and underestimate other cognitive features like having strong work ethics, abilities to collaborate, and people skills. One potentially clear interpretation of this finding is that EAs/alignment researchers actually believe that high intelligence is necessary but not sufficient for being impactful—but perceive other EAs/alignment researchers as thinking high intelligence is basically sufficient. The community aligning on these questions seems of very high practical importance for hiring/grantmaking criteria and decision-making.
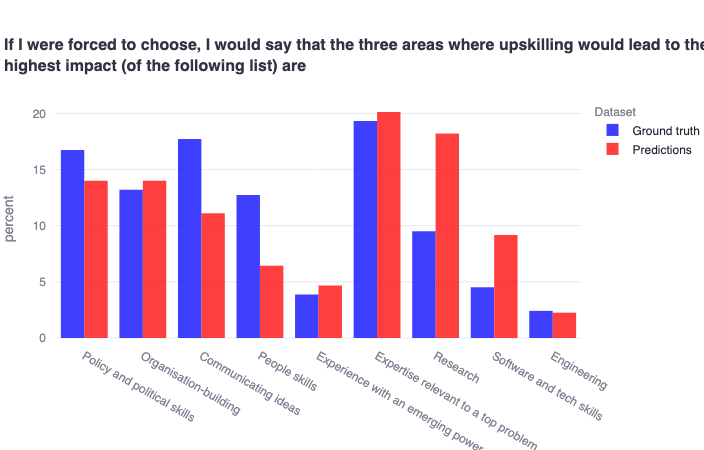
Finally—and not entirely unrelatedly—we highlight the finding that EAs have diverse views on the most important areas for upskilling (options pulled directly from 80000 Hours’ skills list). While generally well-calibrated, the community appears to overestimate the predicted value of upskilling in ‘harder’ skills like research and coding, while underestimating the predicted value of ‘softer’ skills like communicating ideas and being good with people. Overall, EAs think (and predict correctly) that gaining expertise relevant to a top problem is the most valuable area to upskill.
Alignment community
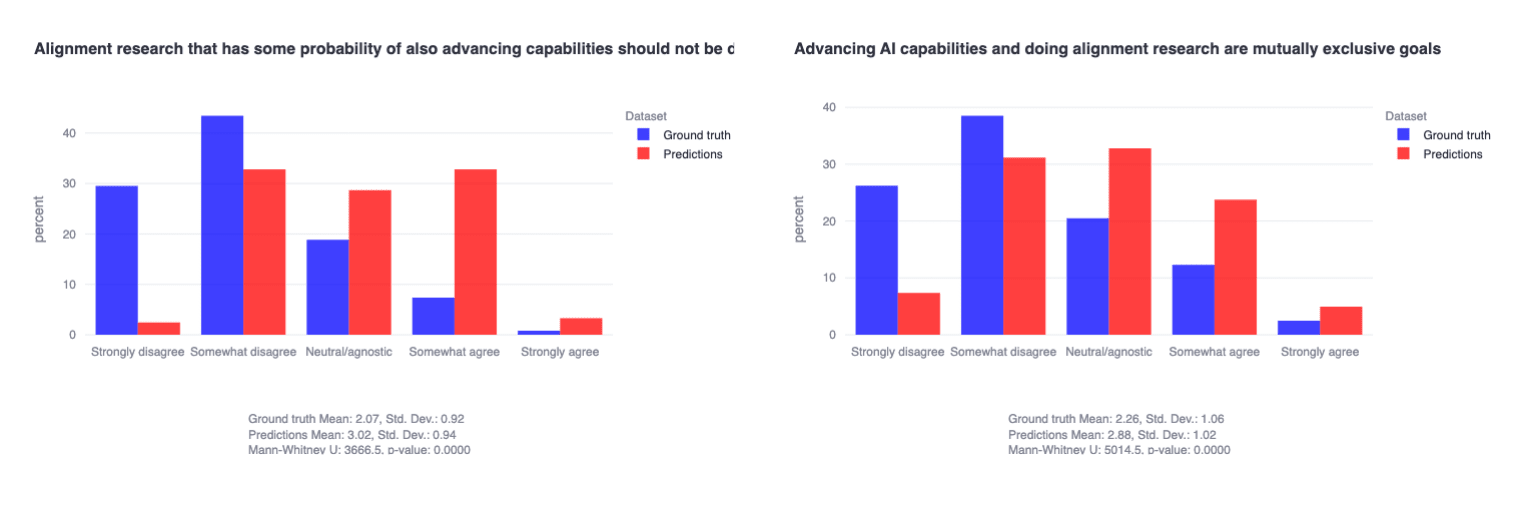
We asked alignment researchers multiple questions to evaluate the extent to which they generally view capabilities research and alignment research as compatible.[7] Interestingly, researchers predicted that the community would view progress in capabilities and alignment as fundamentally incompatible, but the community actually skews fairly strongly in the opposite direction—ie, towards thinking that capabilities and alignment are decidedly not mutually exclusive. As described earlier, our general interpretation of this cluster of findings is that alignment researchers believe that capabilities research is proceeding so hastily that the probability of alignment research being a meaningful contributor to further capabilities speed-ups is actually low—despite mispredicting that other alignment researchers would view this probability as higher.
We find this mismatch particularly interesting for our own alignment agenda and intend to follow up on the implications of this specific development in later work.
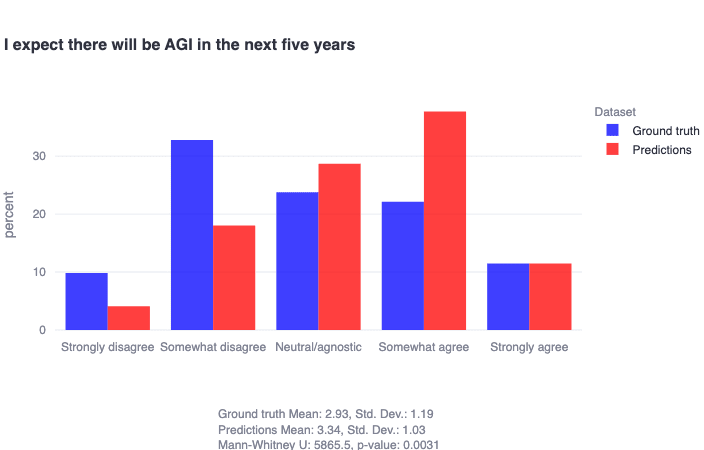
Another relevant misprediction of note relates to AGI timelines. Most alignment researchers do not actively expect there to be AGI in the next five years—but incorrectly predict that other alignment researchers do expect this in general. In other words, this distribution’s skew was systematically mispredicted. Similar distributions can be seen for the related item, ‘I expect there will be superintelligent AI in the next five years.’
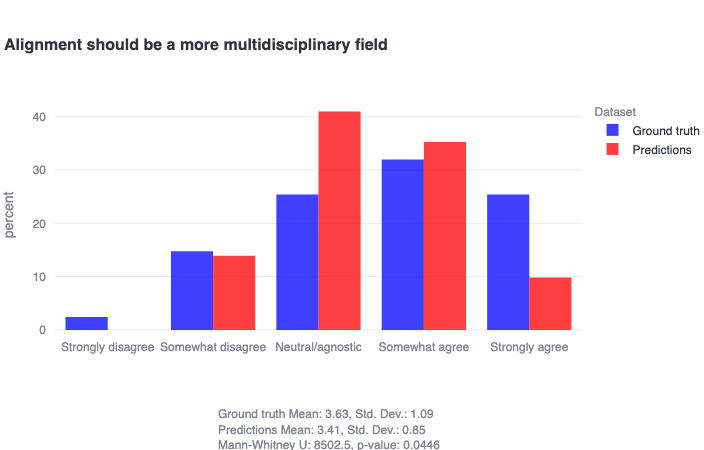
Finally, we share here that the majority of alignment researchers (>55%) agree to some extent that alignment should be a more multidisciplinary field, despite community expectations of a more lukewarm response to this question.
Personality, values, moral foundations
Background on the Big Five
There are many different models of personality (≈ ‘broad patterns of behavior and cognition over time’). The Five Factor Model, or ‘Big Five,’ is widely considered to be the most scientifically rigorous personality model (though it certainly isn’t without its own criticisms). It was developed by performing factor analyses on participants’ ratings over thousands of self-descriptions, and has been generally replicated cross-culturally and over time. Big Five scores for a given individual are also demonstrated to remain fairly consistent over the lifespan. For these reasons, we used this model to measure personality traits in both the EA and the alignment samples.
(We show later on that Big Five + Moral Foundations scores can be used to predict alignment-specific views of researchers significantly above chance level, demonstrating that these tools are picking up on some predictive signal.)
The five factors/traits are as follows:
- Openness: Creativity and willingness to explore new experiences. Lower scores indicate a preference for routine and tradition, while higher scores denote a readiness to engage with new ideas and experiences.
- Conscientiousness: Organization, thoroughness, and responsibility. Individuals with lower scores might tend towards spontaneity and flexibility, whereas those with higher scores demonstrate meticulousness and reliability.
- Extraversion: Outgoingness, energy, and sociability. Lower scores are characteristic of introverted, reflective, and reserved individuals, while higher scores are indicative of sociability, enthusiasm, and assertiveness.
- Agreeableness: Cooperativeness, compassion, and friendliness. Lower scores may suggest a more competitive or skeptical approach to social interactions, whereas higher scores reflect a predisposition towards empathy and cooperation.
- Neuroticism: Tendency and sensitivity towards negative emotionality. Lower scores suggest emotional stability and resilience, whereas higher scores indicate a greater susceptibility to stress and mood swings.
Personality similarities and differences
In general, the results of the Big Five assessment we administered indicate that both EAs and alignment researchers tend to be fairly extraverted, moderately neurotic, intellectually open-minded, generally industrious, and generally quite compassionate. Compared to the general population, both EAs and alignment researchers are significantly more extraverted, conscientious, neurotic, and open. Only EAs are significantly more agreeable than the general population—alignment researchers score slightly lower in agreeableness than the general population mean (but not significantly so).
This result is not the first to demonstrate that the psychological combination of intellectualism (≈ openness), competence (≈ conscientiousness), and compassion (≈ agreeableness) corresponds intuitively to the core philosophies of effective altruism/AI alignment.
It is also somewhat unsurprising that two key differentiators between both communities and the general population appear to be (1) significantly higher sensitivity to negative emotion and (2) significantly higher openness. It seems clear that individuals attracted to EA/alignment are particularly calibrated towards avoidance of negative long-term outcomes, which seems to be reflected not only in both communities’ higher neuroticism scores, but also in our measurements of fairly tepid attitudes towards risk-taking in general (particularly in the alignment community). Additionally, higher openness should certainly be expected in communities organized around ideas, rationality, and intellectual exchange. However, it also seems likely that EAs and alignment researchers may score significantly higher in intellect (often described as ‘truth-oriented’)—one of the two aspects/constituent factors of trait openness—than openness to experience (often described as ‘beauty-oriented’). Pinning down this asymmetry more precisely seems like one interesting direction for follow-up work.
Though it was out of scope for this report, we are also excited about better understanding the extent to which there might be ‘neglected’ personalities in both EA and alignment—i.e., whether there are certain trait configurations that are typically associated with research/organizational success that are currently underrepresented in either community. To give one example hypothesis, it may be the case that consistently deprioritizing openness to experience (beauty-orientedness) in favor of intellect (truth-orientedness) may lead to organizational and research environments that prevent the most effective and resonant possible creative/intellectual work from being done. We are also interested in better understanding whether there is a clear relationship between ‘neglected’ personalities and neglected approaches to alignment—that is, to what degree including (or not including) specific kinds of thinkers in alignment would have a predictable impact on research directions.
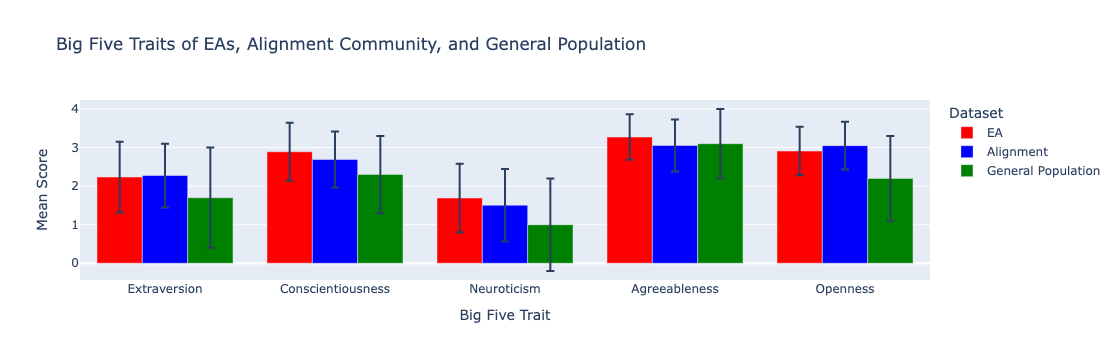
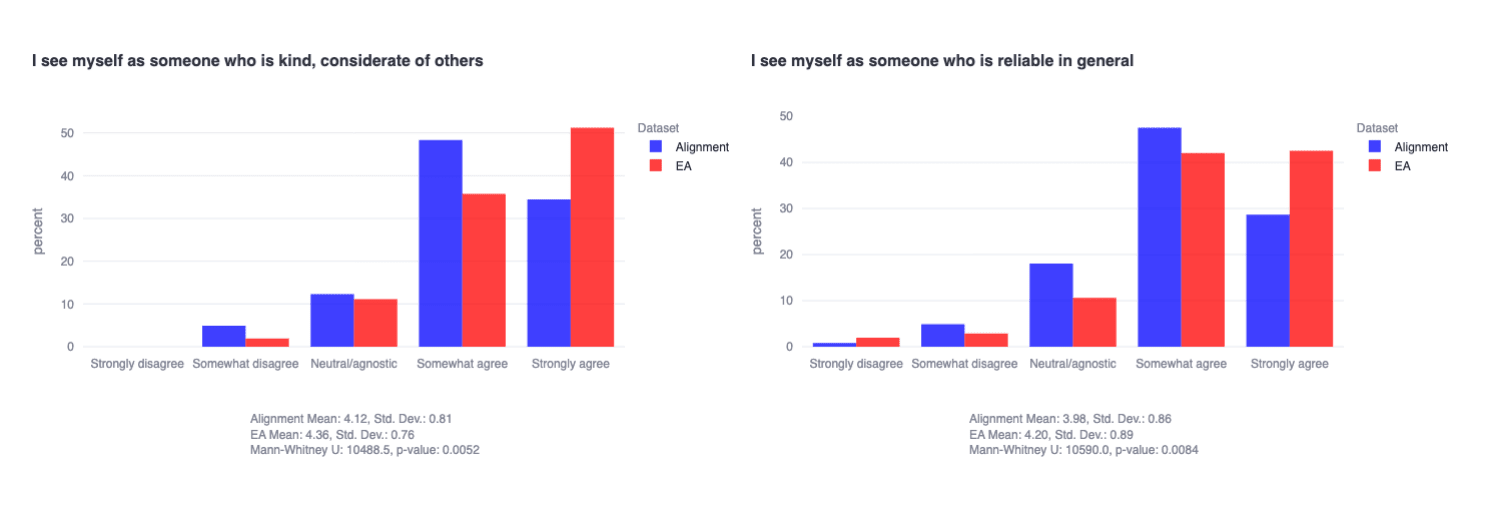
In spite of significant trait similarities across the two communities, we also find that EA respondents on average are more conscientious (t=2.7768, p=0.0058) and more agreeable (t=3.0674, p=0.0023) than the alignment community respondents, while alignment researchers tend to be slightly (though not statistically significantly) higher in openness. It is possible that EAs are more broadly people-oriented (or otherwise select for this) given their prioritization of explicitly-people-(or-animal)-related causes. It is also possible that the relative concreteness of EA cause areas, as compared to the often-theoretical world of technical AI safety research, may lend itself to slightly more day-to-day, industrious types.
These differences are mostly being driven by significantly different distributions on key self-reports related to each trait, for instance:
EAs and alignment researchers have significantly different moral foundations
Moral foundations theory posits that the latent variables underlying moral judgments are modularized to some extent and are validly captured (like the Big Five) via factor analysis/dimensionality reduction techniques. We directly operationalize this paper in our implementation of the Moral Foundations Questionnaire (MFQ), which finds three clear factors underlying the original model:
- Traditionalism: Values social stability, respect for authority, and community traditions, emphasizing loyalty and social norms. Lower scores may lean towards change and flexibility, whereas higher scores uphold authority and tradition.
- Compassion: Centers on empathy, care for the vulnerable, and fairness, advocating for treating individuals based on need rather than status. Lower scores might place less emphasis on individual care, while higher scores demonstrate deep empathy and fairness.
- Liberty: Prioritizes individual freedom and autonomy, resisting excessive governmental control and supporting the right to personal wealth. Lower scores may be more accepting of government intervention, while higher scores champion personal freedom and autonomy.
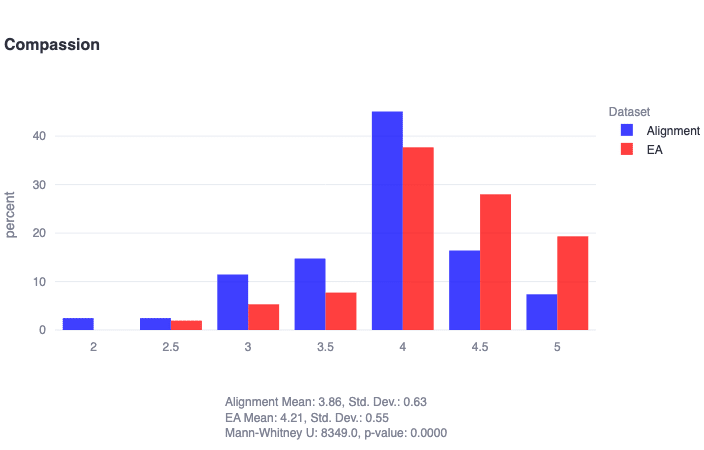
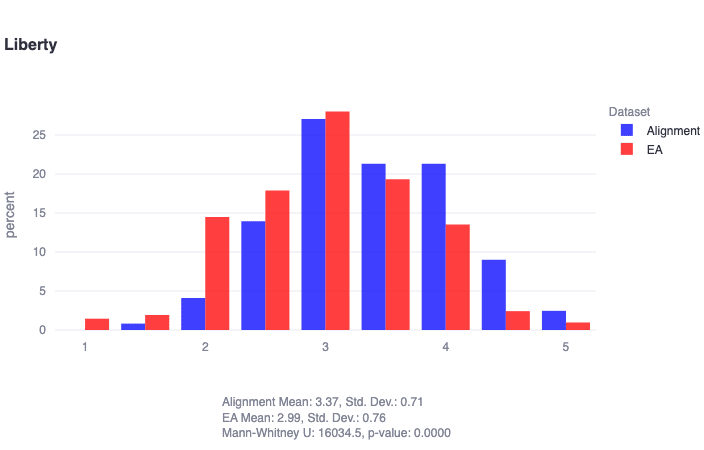
We find in general that both EAs and alignment researchers score low on traditionalism, high on compassion, and are distributed roughly normally on liberty. However, EAs are found to score significantly higher in compassion (U=8349, p≈0), and alignment researchers are found to score significantly higher in liberty (U=16035, p≈0). Note that Likert items (strongly disagree, somewhat disagree, ..., strongly agree) are represented numerically below, where 1 = strongly disagree, and so on.
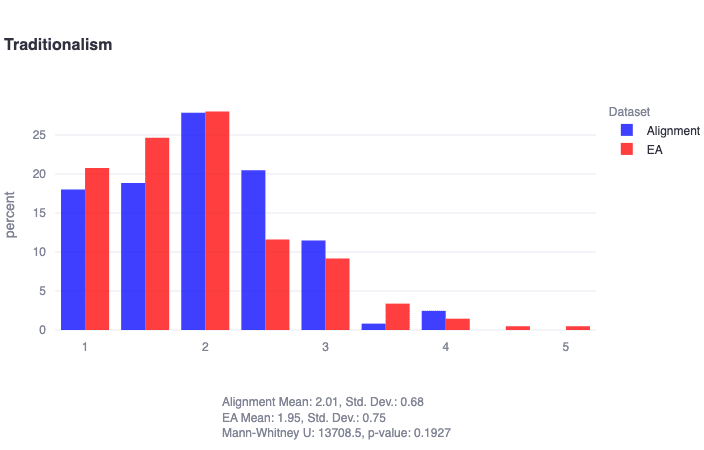
Considering each of these three results in turn:
- It is not very surprising that EAs and alignment researchers are low in traditionalism, which is typically associated with conservatism and more deontological/rule-based ethical systems. Worrying about issues like rogue AI and wild animal suffering might indeed be considered the epitome of ‘untraditional’ ethics. This result naturally pairs with the finding that there are virtually no conservative EAs/alignment researchers, which may have important implications for viewpoint diversity and neglected approaches in both communities.
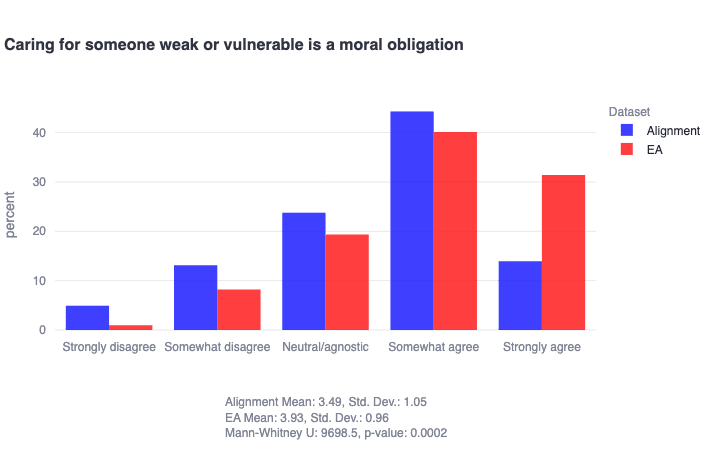
- Both alignment researchers and EAs clearly value compassion from a moral perspective, but EAs seem especially passionate—and more homogenous—in this respect. For instance:
- Interestingly, both alignment researchers and EAs are generally-normally-distributed on liberty as a moral foundation, with alignment researchers demonstrating a slight positive skew (towards liberty) and EAs demonstrating a slight negative skew (away from liberty). A clear example of this dynamic can be seen here:
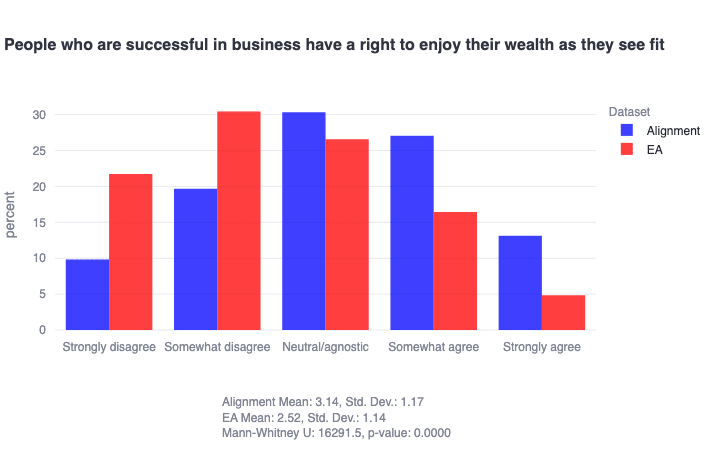
It is worth noting that while the philosophy of effective altruism/AI safety has a clear expected relationship to traditionalism (boo!) and compassion (yay!), it seems plausibly agnostic to liberty as a moral value, potentially explaining the generally-normally-distributed nature of both populations. This finding invites further reflection within both communities on how liberty as a moral foundation relates to their work. For example, the implementation details of an AI development pause seemingly have a clear relationship to liberty (as we actually demonstrate quantitatively later on). Given that alignment researchers seem to care both about liberty and AI x-risk, it would be interesting for follow-up work to better understand, for example, how researchers would react to a government-enforced pause.
Free responses from alignment survey
On the alignment survey, we asked respondents three questions that they could optionally write in responses to:
- What, if anything, do you think is neglected in the current alignment research landscape? Why do you think it is neglected?
- How would you characterize the typical alignment researcher? What are the key ways, if any, that you perceive the typical alignment researcher as unique from the typical layperson, the typical researcher, and/or the typical EA/rationalist type?
- Do you have any other insights about the current state of alignment research that you'd like to share that seems relevant to the contents of this survey?
Given the quantity of the feedback and the fact that we ourselves have strong priors about these questions, we elected to simply aggregate responses for each question and pass them to an LLM to synthesize a coherent and comprehensive overview.
Here is that output (note: it is ~60% the length of this post), along with the anonymized text of the respondents.
Our four biggest takeaways from the free responses (consider this an opinionated TL;DR):
- The field is seen as suffering from discoordination and a lack of consensus on research strategies, compounded by a community described as small, insular, and overly influenced by a few thought leaders. It is important to highlight the significant worries about the lack of self-correction mechanisms and objective measures of research impact, which suggests the need for further introspection on how the community evaluates progress and success. Both of these concerns appear to us as potentially highly impactful neglected ‘meta-approaches’ that would be highly worthwhile to fund and/or pursue further.
- There were numerous specific calls for interdisciplinary involvement in alignment, including multiple calls for collaboration with cognitive psychologists and behavioral scientists. We were excited to see that brain-like AGI was highlighted as one neglected approach that was construed as both accessible and potentially-high-impact for new promising researchers entering the space.
- The alignment community perceives itself to be distinguished by its members' high intellectual capacity and mathematical ability, specialized technical knowledge, high agency, pragmatic altruism, and excellent epistemic practices. Distinct from typical EA/rationalist types, they're noted for their STEM background, practical engagement with technical AI issues, and a combination of ambition with intrinsic motivation. They also believe they are perceived as less experienced and sometimes less realistic than their peers in cognitive sciences or typical ML researchers.
- The community also shared concerns about the ambiguous standards defining alignment researchers, potentially skewing the field towards rewarding effective communication over substantive research progress. Critiques also extend to the research direction and quality, with some arguing that emphasis on intelligence may overlook creativity and diverse contributions (a finding we replicate in more quantitative terms elsewhere).
Concluding thoughts
Thanks again to both communities for their participation in these surveys, which has enabled all of the analysis presented here, as well as over $10k in donations to a set of very high impact orgs. We want to emphasize that we perceive this write-up to be a first pass on both datasets rather than the last word, and we’d like to strongly encourage those who are interested to explore the data analysis tool we built alongside this project (as well as the full, anonymized datasets). We suspect that there are other interesting results to be found that we have not yet uncovered and are very excited to see what else the community can unearth (please do share any results you find and we will add them to this post!).
One practical thought: we were most surprised by the community misprediction/false consensus effect results. Accordingly, we think it is probably worth probing alignment between (1) group X’s perception of group X’s views ‘as a whole’ and (2) group X’s actual views fairly regularly, akin to calibration training in forecasting. Group-level self-misperceptions are a clear coordination problem that should likely be explicitly minimized through some kind of active training or reporting process. (A more precise future tool might enable users to predict the full shape of the distribution to avoid noise in varying statistical interpretations of (1) above.)
To end on a positive note, we highlight one final significant community misprediction from the alignment survey:
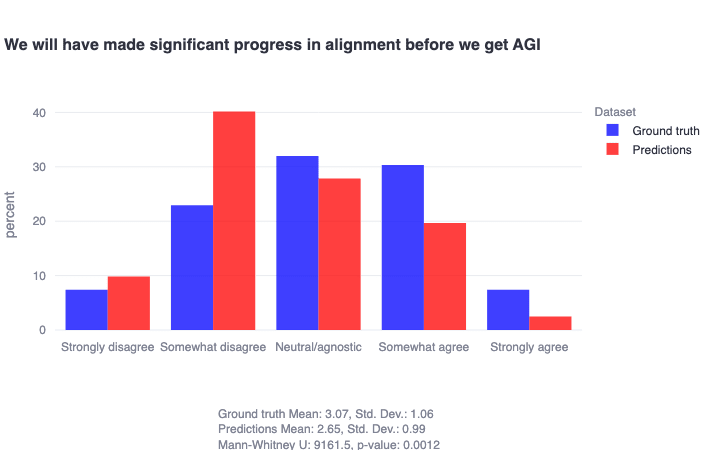
This demonstrates that alignment researchers are significantly more optimistic than they anticipated about having made significant alignment progress before AGI is developed. In other words: alignment researchers currently don’t think that other alignment researchers are particularly hopeful about making progress, but they actually are! (Or at the very least, are explicitly not pessimistic.) So we’d like to strongly encourage researchers to go out and continue doing the hard work with this understanding in mind, particularly with respect to the more underexplored areas of the alignment research landscape.
Thanks very much for your engagement with this project, and we are looking forward to seeing what other interesting results the community can discover.
Appendix: other interesting miscellaneous findings (in no particular order)
Using temperament to predict alignment positions
An interesting (though not particularly actionable) classification result:
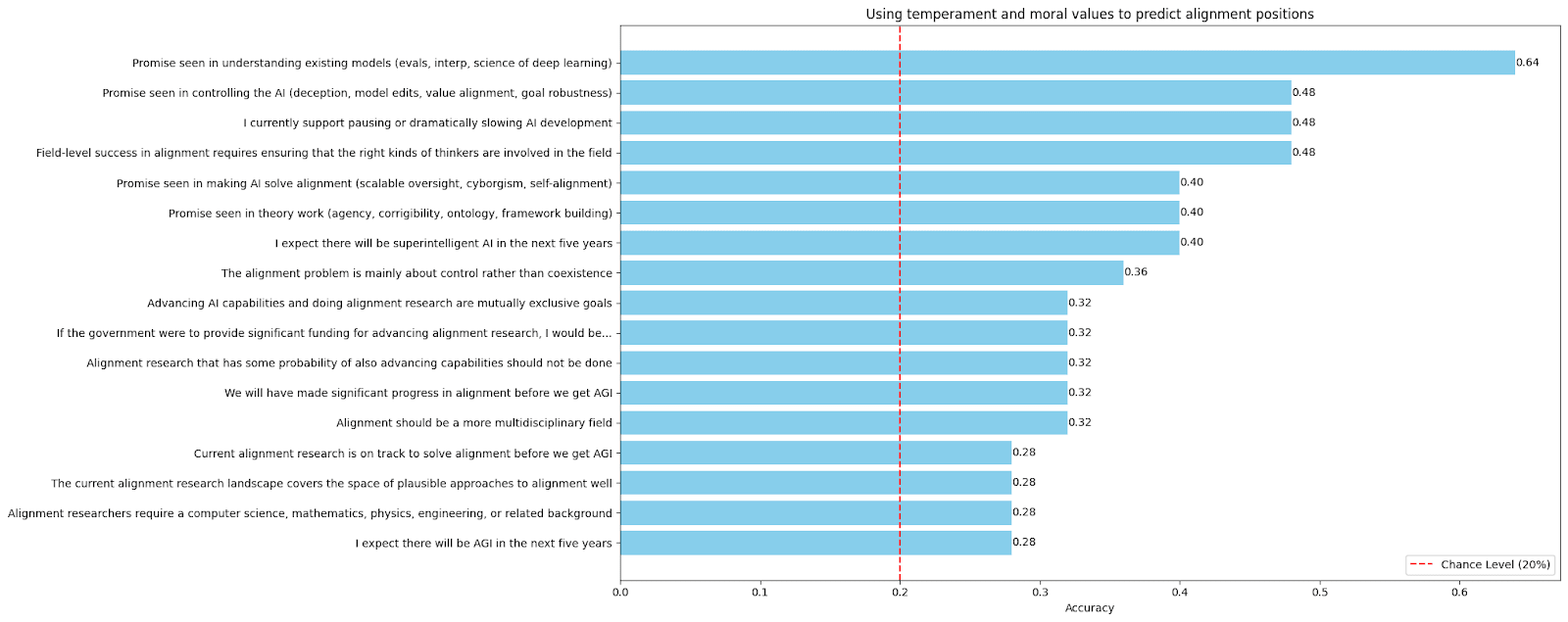
We show that respondents’ trait-level scores from the psychometric instruments deployed in both surveys can be used to predict alignment researchers’ positions on the various alignment-specific questions significantly above chance level using a simple Random Forest Classifier (with balanced class weights). Feature importances reveal that many such predictions are based on seemingly sensible features—for instance, for the statement, “I currently support pausing or dramatically slowing AI development,” the feature with the single highest importance is one’s liberty moral foundation score, which makes a good deal of sense. For the “promise seen in controlling the AI (deception, model edits, value alignment, goal robustness)” question, the single feature with the highest importance is, quite intriguingly, one’s own self-control score on the Brief Self-Control Scale.
The purpose of this analysis is to demonstrate that, while undoubtedly imperfect, these psychometric tools can indeed be used to help predict real-world psychological variables in sensible and interesting ways—which in turn can yield interesting practical implications for field-building, pursuing novel approaches, and the like.
Gender differences in alignment
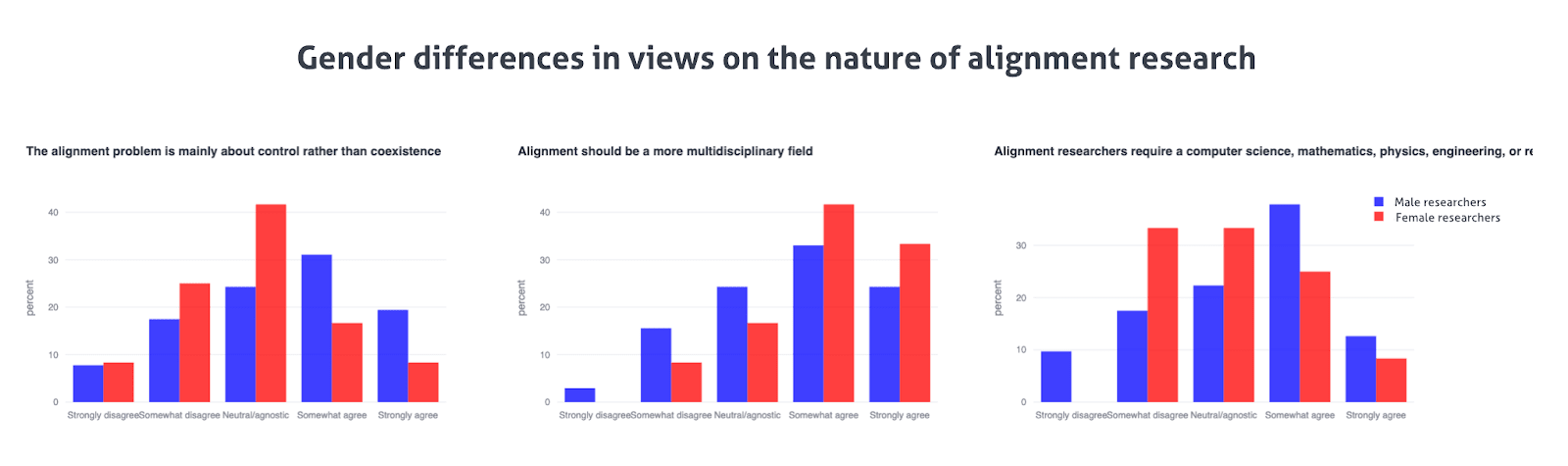
We show here that female alignment researchers are slightly less likely to think of alignment as fundamentally related to control rather than coexistence, more likely to think that alignment should be more multidisciplinary, and slightly less likely to think that alignment researchers require a CS, math, physics, engineering, or similar background. Given that female researchers seem to have meaningfully different views on key questions about the nature of alignment research and are dramatically outnumbered by males (9 to 1), it may be worth explicitly attempting to recruit a larger number of well-qualified female alignment researchers into the fold.
EAs and alignment researchers exhibit very low future discounting rates
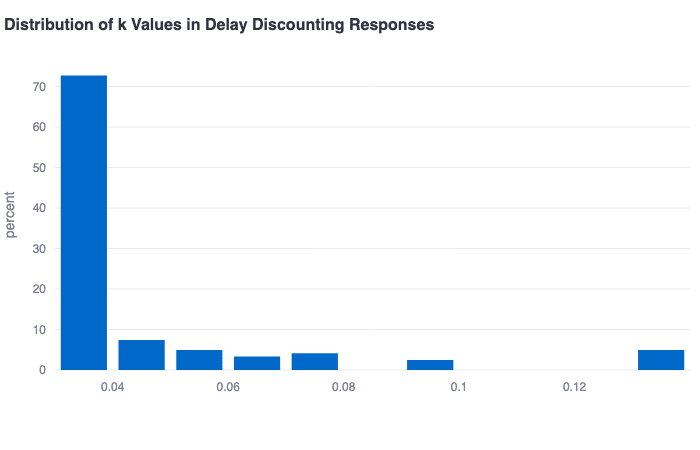
As additional convergent evidence supporting the they-are-who-they-say-they-are conclusion, both EAs and alignment researchers demonstrate very low future discounting rates as measured using a subset of questions from the Monetary Choice Questionnaire. (This tool basically can be thought of as a more quantitative version of the famous marshmallow test and has been shown to correlate with a number of real-world variables.) Having very low discounting rates makes quite a lot of sense for rationalist longtermist thinkers.
One particularly interesting finding related to this metric is that support for doing theory work correlates moderately (r=0.19, p=0.03) with support for pursuing theory work in alignment. One clear interpretation of this result might be that those who discount the future more aggressively—and who might have a diminished sense of the urgency of alignment research as a result—also think it is more promising to pursue alignment approaches that are less immediately practical (i.e., theory work).
EAs and alignment researchers aren't huge risk-takers
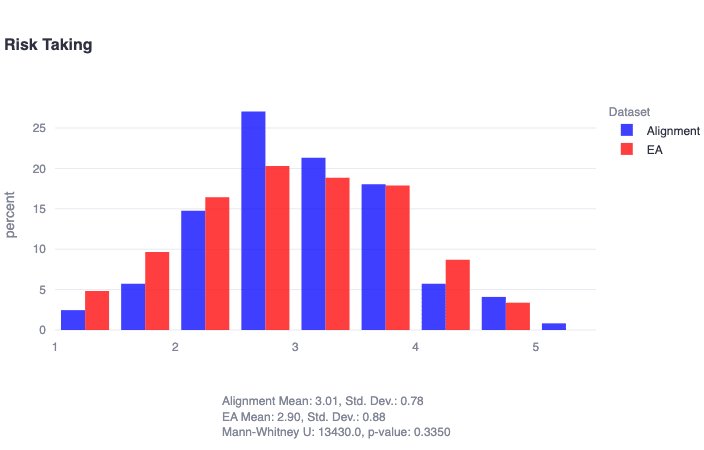
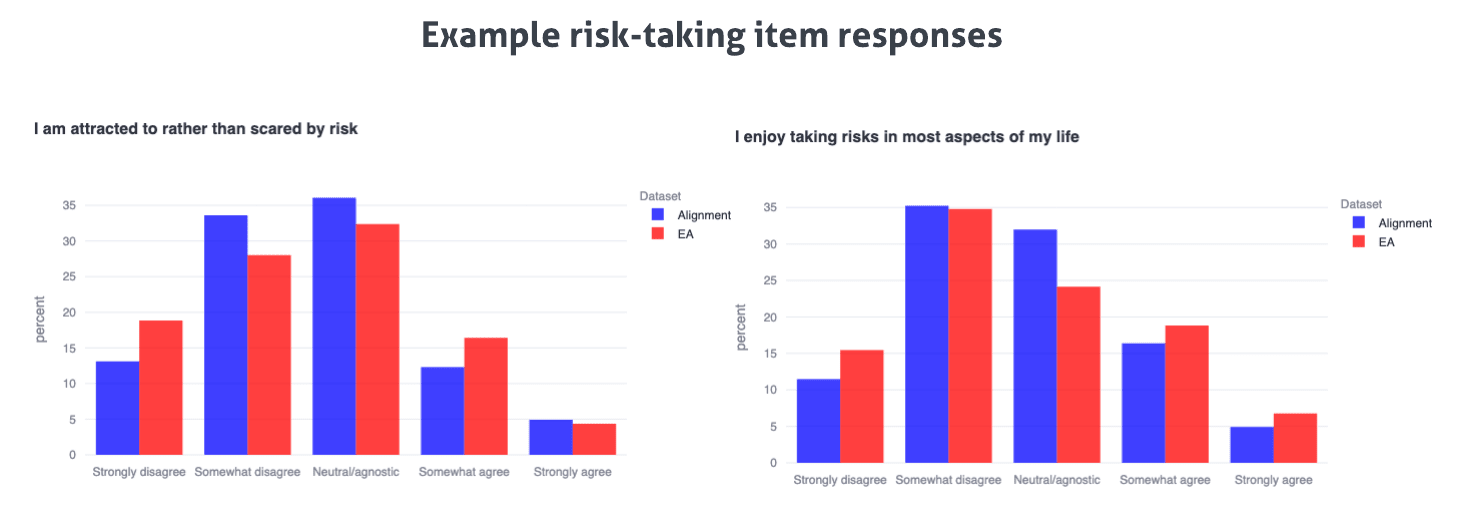
We show that both EAs and alignment researchers are generally normally distributed with a slight negative skew on risk-taking as captured by the General Risk Propensity Scale, with less than 15% of individuals in either community displaying a strong risk-taking temperament (≥4 on the scale above). This effect is driven by example responses shown below the scale-level plot.
EAs are almost-perfectly-normally-distributed on some key EA questions
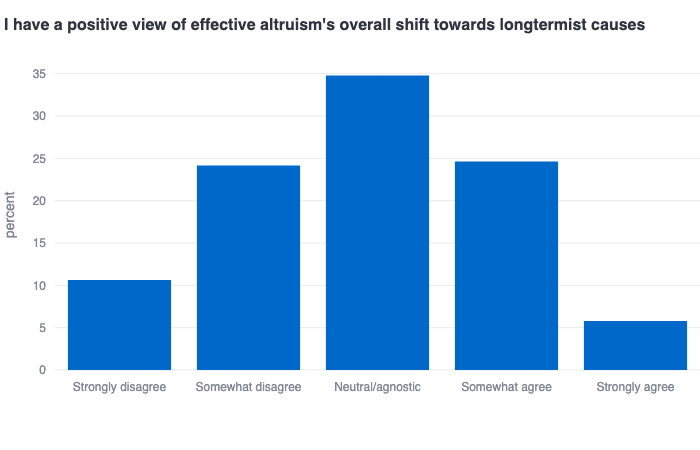
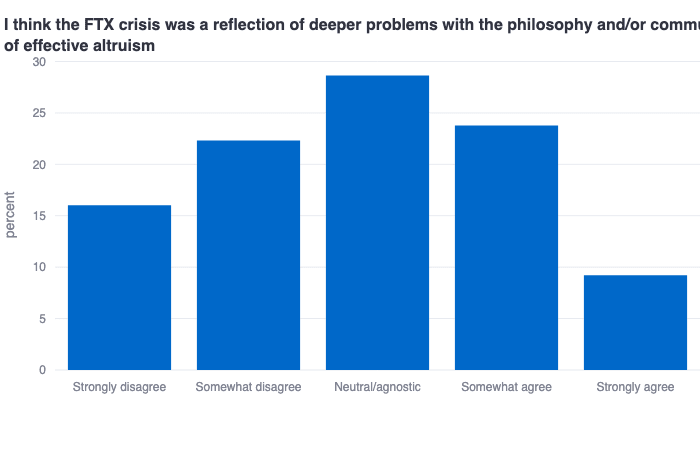
These plots show that EAs are almost perfectly normally distributed on (1) the extent to which they have a positive view of effective altruism’s overall shift towards longtermist causes, and (2) the extent to which they think the FTX crisis was a reflection of deeper problems with EA. These both may be questions that therefore require further adjudication within the community given the strong diversity of opinions on these fairly foundational issues.
Alignment researchers support a pause
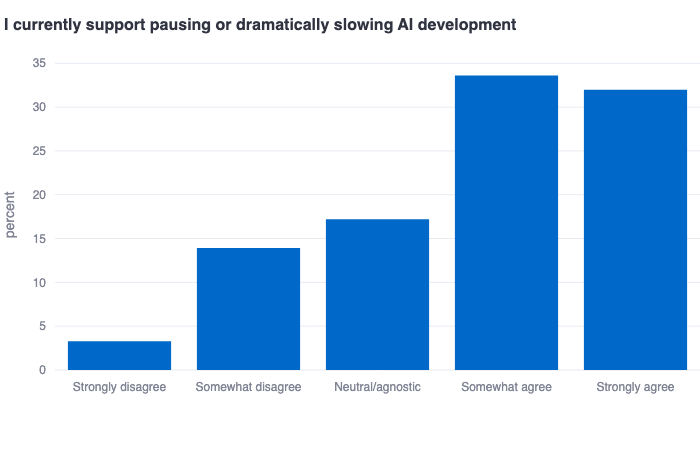
It is very clear that alignment researchers generally support pausing or dramatically slowing AI development (>60% agreement), which naturally pairs with the finding that alignment researchers do not think we are currently on track to solve alignment before we get AGI.
Alignment org leaders are highly optimistic by temperament
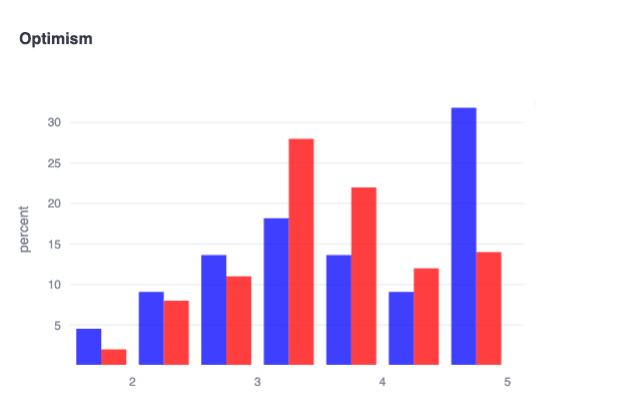
In blue are respondents who actively lead alignment orgs, and in red are all other alignment researchers. We probed trait optimism (ie, not optimism about alignment specifically) in the survey using items like “I see myself as someone who is an optimist,” “...who has a ‘glass-half-full’ mentality,” etc. and found an interesting pocket of extremely optimistic alignment org leaders! This finding suggests an important (if somewhat obvious) motivating factor of good leaders: genuinely believing that effortfully pushing forward impactful work is likely to yield very positive outcomes.
[Any additional interesting results found by the community will be added here!]
- ^
We defined this as currently-grant-funded alignment researchers and EAs actively involved for >5h/week in a specific cause area.
- ^
Donations from alignment survey:
37 part- or full-time researchers chose AI Safety Camp (https://aisafety.camp/), totaling $1480 for this org.
26 part- or full-time researchers chose SERI MATS (https://www.matsprogram.org/), totaling $1040 for this org.
11 part- or full-time researchers chose FAR AI (https://far.ai/), totaling $440 for this org.
8 part- or full-time researchers chose CAIS (https://www.safe.ai/), totaling $320 for this org.
6 part- or full-time researchers chose FHI (https://www.fhi.ox.ac.uk/), totaling $240 for this org.
5 part- or full-time researchers chose Catalyze Impact (https://www.catalyze-impact.org/), totaling $200 for this org.
Donations from EA survey:
33 actively involved EAs chose GiveWell top charities fund, totaling $1320 for this org.
32 actively involved EAs chose Animal welfare fund, totaling $1280 for this org.
31 actively involved EAs chose Wild Animal Initiative, totaling $1240 for this org.
17 actively involved EAs chose Long term future fund, totaling $680 for this org.
10 actively involved EAs chose Lead Exposure Elimination Project, totaling $400 for this org.
7 actively involved EAs chose Good Food Institute, totaling $280 for this org.
6 actively involved EAs chose Faunalytics, totaling $240 for this org.
5 actively involved EAs chose The Humane League, totaling $200 for this org.
5 actively involved EAs chose Charity entrepreneurship, totaling $200 for this org.
4 actively involved EAs chose Against Malaria Foundation, totaling $160 for this org.
4 actively involved EAs chose StrongMinds, totaling $160 for this org.
3 actively involved EAs chose Nuclear Threat Initiative Biosecurity Program, totaling $120 for this org.
2 actively involved EAs chose Johns Hopkins Center For Health Security, totaling $80 for this org.
2 actively involved EAs chose Suvita, totaling $80 for this org.
2 actively involved EAs chose Malaria Consortium SMC programme, totaling $80 for this org.
1 actively involved EAs chose New Incentives, totaling $40 for this org.
Across both surveys, we are donating $10,280 to a diverse set of effective organizations.
- ^
It might be worthwhile to explore and pioneer structures to help individuals for whom these skills come less naturally work on them further—and/or surround these individuals with excellent people to bring out the best in them. This may be particularly necessary for extracting and implementing some very promising underexplored approaches from, eg, more disagreeable but brilliant individuals who might not otherwise implement them.
- ^
That is, knowing that someone is an alignment researcher/in the EA community doesn't meaningfully help predict how much they will value liberty, but it does meaningfully help predict how much they will value both compassion and traditionalism.
- ^
We are also incidentally hopeful that these results may actually have implications for increased funding towards some neglected cause areas that could indirectly wind up benefiting alignment, by, for example, leading to a funding environment in which causes like cluster headaches and consciousness research and the best of human morality are prioritized, and that this in turn may be a part of the hodgepodge that solves alignment.
- ^
“Prestige is like a powerful magnet that warps even your beliefs about what you enjoy. It causes you to work not on what you like, but what you'd like to like.
That's what leads people to try to write novels, for example. They like reading novels. They notice that people who write them win Nobel prizes. What could be more wonderful, they think, than to be a novelist? But liking the idea of being a novelist is not enough; you have to like the actual work of novel-writing if you're going to be good at it; you have to like making up elaborate lies.
Prestige is just fossilized inspiration. If you do anything well enough, you'll make it prestigious. Plenty of things we now consider prestigious were anything but at first. Jazz comes to mind — though almost any established art form would do. So just do what you like, and let prestige take care of itself.
Prestige is especially dangerous to the ambitious. If you want to make ambitious people waste their time on errands, the way to do it is to bait the hook with prestige. That's the recipe for getting people to give talks, write forewords, serve on committees, be department heads, and so on. It might be a good rule simply to avoid any prestigious task. If it didn't suck, they wouldn't have had to make it prestigious.
Similarly, if you admire two kinds of work equally, but one is more prestigious, you should probably choose the other. Your opinions about what's admirable are always going to be slightly influenced by prestige, so if the two seem equal to you, you probably have more genuine admiration for the less prestigious one.” - https://paulgraham.com/love.html
- ^
It is worth noting that two respondents noted that they thought these questions were phrased in an unclear way, which may be a potential source of noise in these results.
Thanks for putting together these results!
This seems over-stated. Our own results on cause prioritisation,[1] which are based on much larger sample sizes drawn from a wider sample of the EA community, find that while Global Poverty tends to be marginally ahead of AI Risk, considering the sample as a whole, Animal Welfare (and all other neartermist causes) are significantly behind both.
But this near-parity of Global Poverty and AI risk considering the sample as a whole obscures the underlying dynamic in the community, which isn't that EAs as a whole are lukewarm about longtermism: it's that highly engaged EAs prioritise longtermist causes and less highly engaged more strongly prioritise neartermist causes.
Overall, I find your patterns of results for people's own cause prioritisation and their predicted cause prioritisation quite surprising. For example, we find ratings of Animal Welfare, and most causes, to be quite normally distributed, but yours are extremely skewed (almost twice as many give Animal Welfare the top rating as give it the next highest rating and more than twice as many give it the second to highest rating as the next highest).
The results below are taken from the 2020 post, but we'll post the more recent ones next week, which found similar results.
Thanks for your comment! I would suspect that these differences are largely being driven by the samples being significantly different. Here is the closest apples-to-apples comparison I could find related to sampling differences (please do correct me if you think there is a better one):
From your sample:
From our sample:
In words, I think your sample is significantly broader than ours: we were looking specifically for people actively involved (we defined as >5h/week) in a specific EA cause area, which would probably correspond to the non-profit buckets in your survey (but explicitly not, for example, 'still deciding what to pursue', 'for profit (earning to give)', etc., which seemingly accounts for many hundreds of datapoints in your sample).
In other words, I think our results do not support the claim that
given that our sample is almost entirely composed of highly engaged EAs.
Additional sanity checks on our cause area result are that the community's predictions of the community's views do more closely mirror your 2020 finding (ie, people indeed expected something more like your 2020 result)—but that the community's ground truth views are clearly significantly misaligned with these predictions.
Note that we are also measuring meaningfully different things related to cause area prioritization between the 2020 analysis and this one: we simply asked our sample how promising they found each cause area, while you seemed to ask about resourced/funded each cause area should be, which may invite more zero-sum considerations than our questions and may in turn change the nature of the result (ie, respondents could have validly responded 'very promising' to all of the cause areas we listed; they presumably could not have similarly responded '(near) top priority' to all of the cause areas you listed).
Finally, it is worth clarifying that our characterization of our sample of EAs seemingly having lukewarm views about longtermism is motivated mainly by these two results:
These results straightforwardly demonstrate that the EAs we sampled clearly predict that the community would have positive views of 'longtermism x EA' (what we also would have expected), but the group is actually far more evenly distributed with a slight negative skew on these questions (note the highly statistically significant differences between each prediction vs. ground truth distribution; p≈0 for both).
Finally, it's worth noting that we find some of our own results quite surprising as well—this is precisely why we are excited to share this work with the community to invite further conversation, follow-up analysis, etc. (which you have done in part here, so thanks for that!).
I don't think this can explain the difference, because our sample contains a larger number of highly engaged / actively involved EAs, and when we examine results for these groups (as I do above and below), they show the pattern I describe.
These are the results from people who currently work for an EA org or are currently doing direct work (for which we have >500 and 800 respondents respectively). Note that the EA Survey offers a wide variety of ways we can distinguish respondents based on their involvement, but I don't think any of them change the pattern I'm describing.
Both show that AI risk and Biosecurity are the most strongly prioritized causes among these groups. Global Poverty and Animal Welfare retain respectable levels of support, and it's important not to neglect that, but are less strongly prioritised among these groups.
To assess the claim of whether there's a divergence between more and less highly engaged EAs, we need to look at the difference between groups however, not just a single group of somewhat actively involved EAs. Doing this with 2022 data, we see the expected pattern of AI Risk and Biosecurity being more strongly prioritised by highly engaged EAs and Global Poverty less so. Animal Welfare notably achieves higher support along the more highly engaged, but still lower than the longtermist causes.[1]
I agree that this could explain some of the differences in results, though I think that how people would prioritize allocation of resources is more relevant for assessing prioritization. I think that promisingness may be hard to interpret both given that, as you say, people could potentially rate everything highly promising, and also because "promising" could connote an early or yet to be developed venture (one might be more inclined to describe a less developed cause area as "promising", than one which has already reached its full size, even if you think the promising cause area should be prioritized less than the fully developed cause areas). But, of course, your mileage may vary, and you might be interested in your measure for reasons other than assessing cause prioritization.
Thanks, I think these provide useful new data!
It's worth noting that we have our own, similar, measure concerning agreement with an explicit statement of longtermism: "The impact of our actions on the very long-term future is the most important consideration when it comes to doing good."
As such, I would distinguish 3 things:
Abstract support for (quite strong) longtermism
Looking at people's responses to the above (rather strong) statement of abstract longtermism we see that responses lean more towards agreement than disagreement. Given the bimodal distribution, I would also say that this reflects less a community that is collectively lukewarm on longtermism, and more a community containing one group that tends to agree with it and a group which tends to disagree with it.
Moreover, when we examine these results split by low/high engagement we see clear divergence, as in the results above.
Concrete cause prioritization
Moreover, as noted, the claim that it is "the most important consideration" is quite strong. People may be clearly longtermist despite not endorsing this statement. Looking at people's concrete cause prioritization, as I do above, we see that two longtermist causes (AI Risk and Biosecurity) are among the most highly prioritized causes across the community as a whole and they are even more strongly prioritised when examining more highly engaged EAs. I think this clearly conflicts with a view that "EAs have lukewarm views about longtermism... EAs (actively involved across 10+ cause areas) generally seem to think that AI risk and x-risk are less promising cause areas than ones like global health and development and animal welfare" and rules out an explanation based on your sample being more highly engaged.
Shift towards longtermism
Lastly, we can consider attitudes towards the "shift" towards longtermism, where your results show no strong leaning one way or the other, with a plurality being Neutral/Agnostic. It's not clear to me that this represents the community being lukewarm on longtermism, rather than, whatever their own views about cause prioritization, people expressing agnosticism about the community's shift (people might think "I support longtermist causes, but whether the community should is up to the community" or some such. One other datapoint I would point to regarding the community's attitudes towards the shift, however, is our own recent data showing that objection to the community's cause prioritization and perception of an excessive focus on AI / x-risk causes are among the most commonly cited reasons for dissatisfaction with the EA community. Thus, I think this reflects a cause for dissatisfaction for a significant portion of the community, even though large portions of the community clearly support strong prioritization of EA causes. I think more data about the community as a whole's views about whether longtermist causes should be prioritized more or less strongly by community infrastructure would be useful and is something we'll consider adding to future surveys.
Animal Welfare does not perform as a clear 'neartermist' cause in our data, when we examine the relationships between causes. It's about as strongly associated with Biosecurity as Global Poverty, for example.
Thanks for sharing all of this new data—it is very interesting! (Note that in my earlier response, I had nothing to go on besides the 2020 result you have already published, which indicated that the plots you included in your first comment were drawn from a far wider sample of EA-affiliated people than what we were probing in our survey, which I still believe is true. Correct me if I'm wrong!)
Many of these new results you share here, while extremely interesting in their own right, are still not apples-to-apples comparisons for the same reasons we've already touched on.[1]
It is not particularly surprising to me that we are asking people meaningfully different questions and getting meaningfully different results given how generally sensitive respondents in psychological research are to variations in item phrasing. (We can of course go back and forth about which phrasing is better/more actionable/etc, but this is orthogonal to the main question of whether these are reasonable apples-to-apples comparisons.)
The most recent data you have that you mention briefly at the end of your response seems far more relevant in my view. It seems like both of the key results you are taking issue with here (cause prioritization and lukewarm longtermism views) you found yourself to some degree in these results (which it's also worth noting was sampled at the same time as our data, rather than 2 or 4 years ago):
Your result 1:
Our result 1:
We specifically find the exact same two cause areas, animals and GHD, as being considered the most promising to currently pursue.
Your result 2 (listed as the first reason for dissatisfaction with the EA community):
Our result 2:
We specifically find that our sample is overall normally distributed with a slight negative skew (~35% disagree, ~30% agree) that EAs' recent shift towards longtermism is positive.
I suppose having now read your newest report (which I was not aware of before conducting this project), I actually find myself less clear on why you are as surprised as you seem to be by these results given that they essentially replicate numerous object-level findings you reported only ~2 months ago.
(Want to flag that I would lend more credence in terms of guiding specific action to your prioritization results than to our 'how promising...' results given your significantly larger sample size and more precise resource-related questions. But this does not detract from also being able to make valid and action-guiding inferences from both of the results I include in this comment, of which we think there are many as we describe in the body of this post. I don't think there is any strong reason to ignore or otherwise dismiss out of hand what we've found here—we simply sourced a large and diverse sample of EAs, asked them fairly basic questions about their views on EA-related topics, and reported the results for the community to digest and discuss.)
One further question/hunch I have in this regard is that the way we are quantifying high vs. low engagement is almost certainly different (is your sample self-reporting this/do you give them any quantitative criteria for reporting this?), which adds an additional layer of distance between these results.
Thanks Cameron!
We agree that our surveys asked different questions. I'm mostly not interested in assessing which of our questions are the most 'apples-to-apples comparisons', since I'm not interested in critiquing your results per se. Rather, I'm interested in what we should conclude about the object-level questions given our respective results (e.g. is the engaged EA community lukewarm and longtermism, and prioritises preference for global poverty and animal welfare, or is the community divided on these views, with the most engaged more strongly prioritising longtermism?).
I would just note that in my original response I showed the how the results varied across the full range of engagement levels, which I think offers more insight into how the community's views differ across groups, than just looking at one sub-group.
The engagement scale is based on self-identification, but the highest engagement level is characterised with reference to "helping to lead an EA group or working at an EA-aligned organization". You can read more about our different measures of engagement and how they cohere here. Crucially, I also presented results specifically for EA org employees and people doing EA work so concerns about the engagement scale specifically do not seem relevant.
I respond to these two points below:
I don't think this tells us much about which causes people think most promising overall. The result you're referring to is looking only at the 22% of respondents who mentioned Cause prioritization as a reason for dissatisfaction with EA and were not one of the 16% of people who mentioned excessive focus on x-risk as a cause for dissatisfaction (38 respondents, of which 8 mentioned animals, 4 mentioned Global poverty and 7 mentioned another cause (the rest mentioned something other than a specific cause area)).
Our footnote mentioning this was never intended to indicate which causes are overall judged most promising, just to clarify how our 'Cause prioritization' and 'Excessive focus on AI' categories differed. (As it happens, I do think our results suggest Global Poverty and Animal Welfare are the highest rated non-x-risk cause areas, but they're not prioritised more highly than all x-risk causes).
Our results show that, among people dissatisfied with EA, Cause prioritisation (22%) and Focus on AI risks/x-risks/longtermism (16%) are among the most commonly mentioned reasons.[1] I should also emphasise that 'Focus on AI risks/x-risks/longtermism' is not the first reason for dissatisfaction with the EA community, it's the fifth.
I think both our sets of results show that (at least) a significant minority believe that the community has veered too much in the direction of AI/x-risk/longtermism. But I don't think that either sets of results show that the community overall is lukewarm on longtermism. I think the situation is better characterised as division between people who are more supportive of longtermist causes[2] (whose support has been growing), and those who are more supportive of neartermist causes.
I certainly agree that my comment here have only addressed one specific set of results to do with cause prioritisation, and that people should assess the other results on their own merits!
And, to be clear, these categories are overlapping, so the totals can't be combined.
As we have emphasised elsewhere, we're using "longtermist" and "neartermist" as a shorthand, and don't think that the division is necessarily explained by longtermism per se (e.g. the groupings might be explained by epistemic attitudes towards different kinds of evidence).
Agreed.
It seems like you find the descriptor 'lukewarm' to be specifically problematic—I am considering changing the word choice of the 'headline result' accordingly given this exchange. (I originally chose to use the word 'lukewarm' to reflect the normal-but-slightly-negative skew of the results I've highlighted previously. I probably would have used 'divided' if our results looked bimodal, but they do not.)
What seems clear from this is that the hundreds of actively involved EAs we sampled are not collectively aligned (or 'divided' or 'collectively-lukewarm' or however you want to describe it) on whether increased attention to longtermist causes represents a positive change in the community—despite systematically mispredicting numerous times that the sample would respond more positively. I will again refer to the relevant result to ensure any readers appreciate how straightforwardly this interpretation follows from the result—
(~35% don't think positive shift, ~30% do; ~45% don't think primary focus, ~25% do. ~250 actively involved EAs sampled from across 10+ cause areas.)
This division/lukewarmness/misalignment represents a foundational philosophical disagreement about how to go about doing the most good and seemed pretty important for us to highlight in the write-up. It is also worth emphasizing that we personally care very much about causes like AI risk and would have hoped to see stronger support for longtermism in general—but we did not find this, much to our surprise (and to the surprise of the hundreds of participants who predicted the distributions would look significantly different as can be seen above).
As noted in the post, we definitely think follow-up research is very important for fleshing out all of these findings, and we are very supportive of all of the great work Rethink Priorities has done in this space. Perhaps it would be worthwhile at some point in the future to attempt to collaboratively investigate this specific question to see if we can't better determine what is driving this pattern of results.
(Also, to be clear, I was not insinuating the engagement scale is invalid—looks completely reasonable to me. Simply pointing out that we are quantifying engagement differently, which may further contribute to explaining why our related but distinct analyses yielded different results.)
Thanks again for your engagement with the post and for providing readers with really interesting context throughout this discussion :)
Thanks again for the detailed reply Cameron!
I don't think our disagreement is to do with the word "lukewarm". I'd be happy for the word "lukewarm" to be replaced with "normal but slightly negative skew" or "roughly neutral, but slightly negative" in our disagreement. I'll explain where I think the disagreement is below.
Here's the core statement which I disagreed with:
The first point of disagreement concerned this claim:
If we take "promising" to mean anything like prioritise / support / believe should receive a larger amount of resources / believe is more impactful etc., then I think this is a straightforward substantive disagreement: I think whatever way we slice 'active involvement', we'll find more actively involved EAs prioritise X-risk more.
As we discussed above, it's possible that "promising" means something else. But I personally do not have a good sense of in what way actively involved EAs think AI and x-risk are less promising than GHD and animal welfare.[1]
Concerning this claim, I think we need to distinguish (as I did above), between:
Regarding the first of these questions, your second result shows slight disagreement with the claim "I think longtermist causes should be the primary focus in effective altruism". I agree that a reasonable interpretation of this result, taken in isolation, is that the actively involved EA community is slightly negative regarding longtermism. But taking into account other data, like our cause prioritisation data which shows actively engaged EAs strongly prioritise x-risk causes or result suggesting slight agreement with an abstract statement of longtermism, I'm more sceptical. I wonder if what explains the difference is people's response to the notion of these causes being the "primary focus", rather than their attitudes towards longtermist causes per se.[2] If so, these responses need not indicate that the actively involved community leans slightly negative towards longtermism.
In any case, this question largely seems to me to reduce to the question of what people's actual cause prioritisation is + what their beliefs are about abstract longtermism, discussed above.
Regarding the question of EA's attitudes towards the "overall shift towards longtermist causes", I would also say that, taken in isolation, it's reasonable to interpret your result as showing that actively involved EAs are lean slightly negative towards EA's shift towards longtermism. Again, our cause prioritisation results suggesting strong and increasing prioritisation of longtermist causes by more engaged EAs across multiple surveys gives me pause. But the main point I'll make (which suggests a potential conciliatory way to reconcile these results) is to observe that attitudes towards the "overall shift towards longtermist causes" may not reflect attitudes towards longtermism per se. Perhaps people are Neutral/Agnostic regarding the "overall shift", despite personally prioritising longtermist causes, because they are Agnostic about what people in the rest of the community should do. Or perhaps people think that the shift overall has been mishandled (whatever their cause prioritisation). If so the results may be interesting, regarding EAs' attitudes towards this "shift" but not regarding their overall attitudes towards longtermism and longtermist causes.
Thanks again for your work producing these results and responding to these comments!
As I noted, I could imagine "promising" connoting something like new, young, scrappy cause areas (such that an area could be more "promising" even if people support it less than a larger established cause area). I could sort of see this fitting Animal Welfare (though it's not really a new cause area), but it's hard for me to see this applying to Global Health/Global Poverty which is a very old, established and large cause area.
For example, people might think EA should not have a "primary focus", but remain a 'cause-neutral' movement (even though they prioritise longtermist cause most strongly and think they should get most resources). Or people might think we should split resources across causes for some other reason, despite favouring longtermism.
"Liberty: Prioritizes individual freedom and autonomy, resisting excessive governmental control and supporting the right to personal wealth. Lower scores may be more accepting of government intervention, while higher scores champion personal freedom and autonomy..."
"alignment researchers are found to score significantly higher in liberty (U=16035, p≈0)"
This partly explains why so much of the alignment community doesn't support PauseAI!
Good find! Two additional points of context:
Hi Cameron :) thanks for replying! I am concerned that the question is double-barreled. Are you? (i.e. a survey question that actually asks about two different things, but only allows for one answer. This can be confusing for respondents and lead to inaccurate data).
Hi Yanni, this is definitely an important consideration in general. Our goal was basically to probe whether alignment researchers think the status quo of rapid capabilities progress is acceptable/appropriate/safe or not. Definitely agree that for those interested, eg, in understanding whether alignment researchers support a full-blown pause OR just a dramatic slowing of capabilities progress, this question would be insufficiently vague. But for our purposes, having the 'or' statement doesn't really change what we were fundamentally attempting to probe.
I love this work, especially because you investigated something I have been curious about for a while - the impact that diversity might have on AI safety. I have a few reactions so I thought I would provide them in separate comments (not sure what the forum norm is).
I am curious if you think there are dimensions of diversity you have not captured, that might be important? One thought that came to my mind when reading this post is geographic/cultural diversity. I am not 100% sure if it is important, but reasons it might be include both:
1 - That different cultures might have different views on what it is important to focus on (a bit like women might focus more on coexistence and less on control)
2 - That it is a global problem and international policy initiatives might be more successful if one can anticipate how various stakeholders react to such initiatives.
Thanks for your comment! Agree that there are additional relevant axes to consider than just those we present here. We actually did probe geography to some extent in the survey, though we don't meaningfully include this in the write-up. Here's one interesting statistically significant difference between alignment researchers who live in urban or semi-urban environments (blue) vs. those who live everywhere else (suburban, ..., remote; red):
Agree that this only scratches the surface of these sorts of questions and that there are other important sources of intellectual/psychological diversity that we are not probing for here.
Thanks for releasing this. I'm curious what is the more interesting sample here: somewhat established alignment researchers (measured by the proxy that they have published a paper), or the general population of who filled out the sample (including those with briefer prior engagement)?
I filled out this survey because it got signal boosted in the AI Safety Camp slack. At the same time, there were questions about the funding viability of AI Safety Camp, so I was strongly motivated to fill it out for the $40 donation. At the same time, I'm not sure that I have engaged deeply enough with Alignment Research to be called an "alignment researcher." Given that AISC was the most common place donated to, this may have skewed the population in general.
Skimming through the visualization tool (very cool, thank you!), the personality questions didn't seem to be affected, but the political questions do seem to vary a little bit. For instance, among alignment researchers who have published a paper, around 55% support or strongly support pausing. On the other hand, among those who haven't published a paper, around 75% support or strongly support pausing. Which population should this analysis rely on?
Good points and thanks for the question. One point to consider is that AISC publicly noted that they need more funding, which may have been a significant part of the reason that they were the most common donation recipient in the alignment survey. We also found that a small subset of the sample explicitly indicated they were involved with AISC (7 out of 124 participants). This is just to provide some additional context/potential explanation to what you note in your comment.
As we note in the post, we were generally cautious to exclude data from the analysis and opted to prioritize releasing the visualization/analysis tool that enables people sort and filter the data however they please. That way, we do not have to choose between findings like the ones you report about pause support x quantity of published work; both statistics you cite are interesting in their own right and should be considered by the community. We generally find though that the key results reported are robust to these sorts of filtering perturbations (let me know if you discover anything different!). Overall, ~80% of the alignment sample is currently receiving funding of some form to pursue their work, and ~75% have been doing this work for >1 year, which is the general population we are intending to sample.
What surprised me the most was that EAs and alignment researchers are more extroverted on average.
In hindsight, I suppose it makes sense. The average alignment researcher I've met interacts way more than the average person, certainly the average male, (conferences, communities, research groups, organising parties etc.).
It really contradicted my assumptions, because EA events are unusually introvert-friendly and online communications for EA/alignment are wayyyyy more text-heavy than most communities.
I wonder how much of that is a selection pressure? For me, I'm strongly introverted, but I probably could not have done AI Safety without actively socialising and reaching out to people very frequently.
I am also curious if you think the field of anthropology (and perhaps linguistics and other similar fields) might have something to offer the field of AI safety/alignment? Caveat: My understanding of both AI safety and anthropology is that of an informed lay person.
A perhaps a bit of a poor analogy: The movie "Arrival" features a linguist and/or anthropologist as the main character and I think that might have been a good observation from the script writer. Thus, one example output I could imagine anthropologists to contribute would be to push back on the framing of the binary or "AIs" and humans. It might be that in terms of culture, the difference between different AIs is larger than between humans and the most "human-like" AI.
People definitely seem excited in general about taking on more multidisciplinary approaches/research related to alignment (see this comment for an overview).
Minor nitpick: you list work ethic as your first example of a soft skill but I don't think it's commonly listed as an example of a soft skill.
Fair enough—I think we are trying to generally point at the distinction between 'raw intelligence' and other 'supplementary' cognitive traits that also predict effectiveness/success (like work ethic, people skills, etc.). This differentiation is the important takeaway, I think, rather than the exact terms we are using to point at it.
Executive summary: Surveys of the EA and AI alignment communities reveal important insights about cause prioritization, research directions, demographics, personality traits, and moral foundations that can help guide the future work and priorities of both communities.
Key points:
This comment was auto-generated by the EA Forum Team. Feel free to point out issues with this summary by replying to the comment, and contact us if you have feedback.