David_Moss
Bio
I am the Principal Research Director at Rethink Priorities. I lead our Surveys and Data Analysis department and our Worldview Investigation Team.
The Worldview Investigation Team previously completed the Moral Weight Project and CURVE Sequence / Cross-Cause Model. We're currently working on tools to help EAs decide how they should allocate resources within portfolios of different causes, and to how to use a moral parliament approach to allocate resources given metanormative uncertainty.
The Surveys and Data Analysis Team primarily works on private commissions for core EA movement and longtermist orgs, where we provide:
- Private polling to assess public attitudes
- Message testing / framing experiments, testing online ads
- Expert surveys
- Private data analyses and survey / analysis consultation
- Impact assessments of orgs/programs
Formerly, I also managed our Wild Animal Welfare department and I've previously worked for Charity Science, and been a trustee at Charity Entrepreneurship and EA London.
My academic interests are in moral psychology and methodology at the intersection of psychology and philosophy.
How I can help others
Survey methodology and data analysis.
Posts 63
Comments612
Thanks James!
We previously asked this question in 2019. The modal response was 0 such connections, followed by 1-2, though there was a long tail of >10 connection respondents. Connections were also far higher for highly engaged EAs (60.7% of highly engaged EAs had >10 connections, compared to 13.7% for considerably (4/5) engaged EAs, and <2% for anyone less engaged).
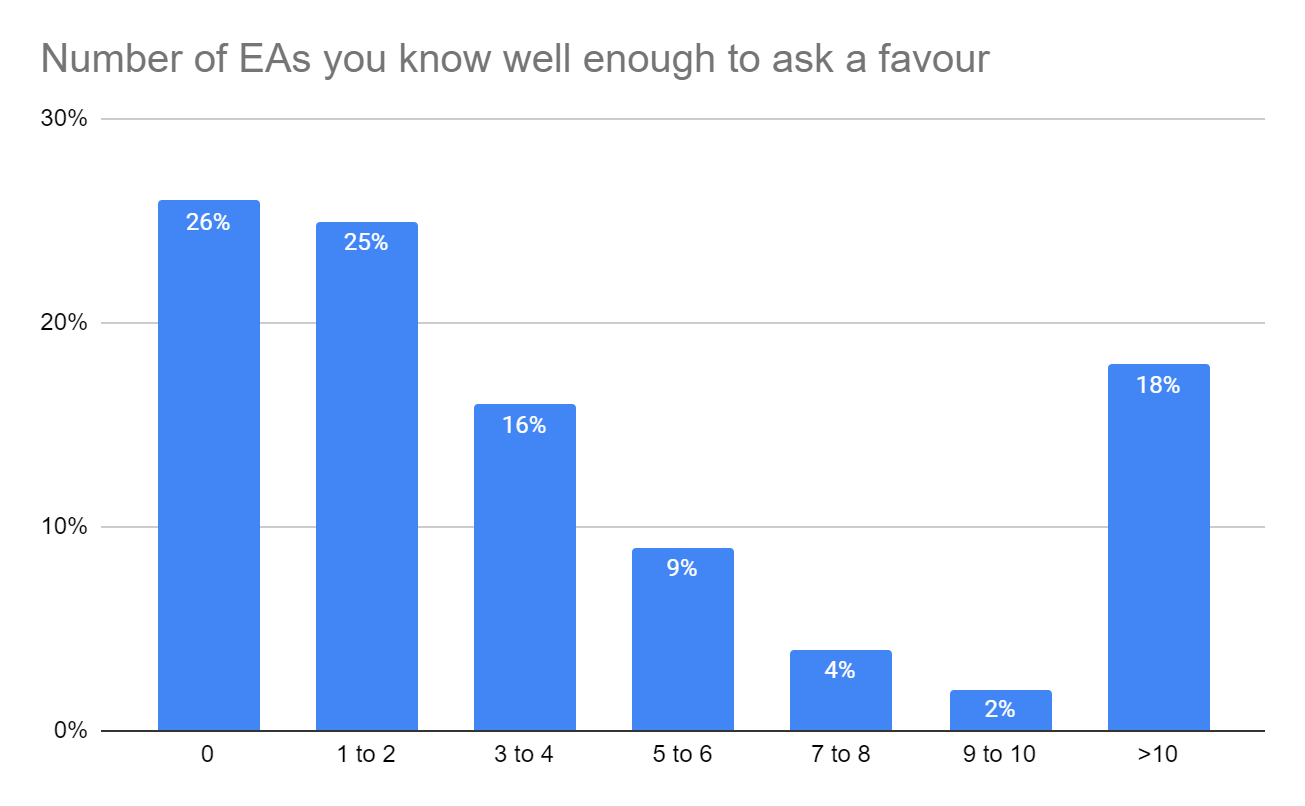
We cut the question due to lack of space and it not being prioritized by core orgs making requests of us. But we'd be happy to reintroduce if there is sufficient interest.
RP actually did some empirical testing on this and we concluded that people really like the name "Effective Altruism", but not the ideas, values or mission.
That's unfortunate. But I think it suggests there's scope for a new 'Centre for Effective Altruism' to push forward exciting new ideas that have more mainstream appeal, like raising awareness of the cause du jour, while the rebranded Center for ████████ continues to focus on all the unpopular stuff.
I think it was a mistake to post about "Hidden Capabilities Evals Leaked In Advance to Bioterrorism Researchers and Leaders (minor)" in a public forum... it seems too minor! Maybe if you'd included some specific examples it would be more useful.
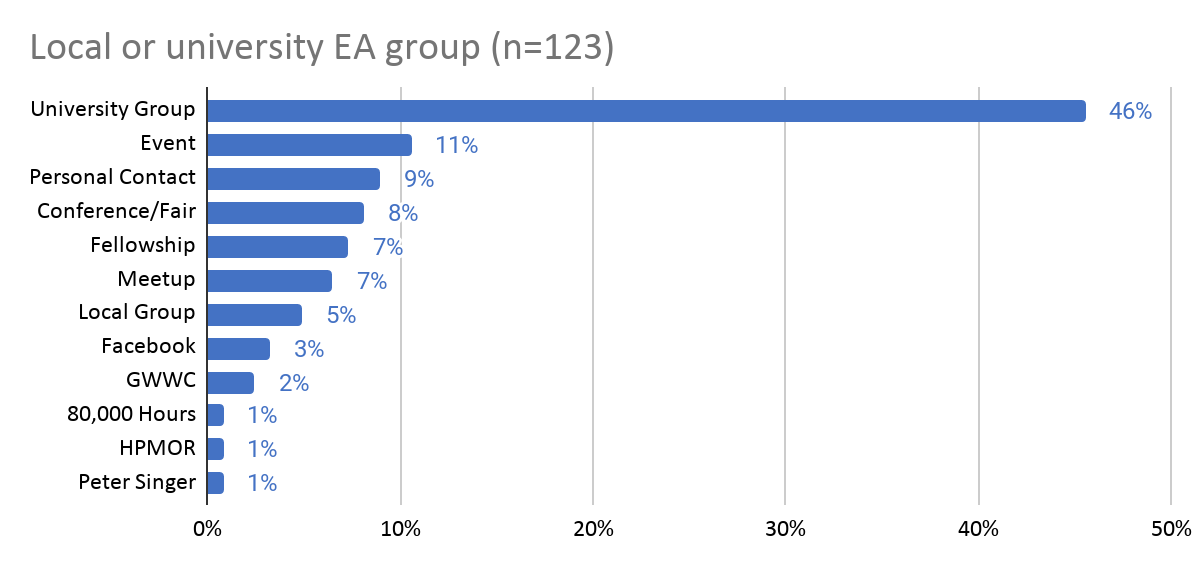
Are introductory fellowships and other courses run by local EA groups considered under "educational courses" or does that mean things like philosophy classes, where EA might be mentioned as a concept?
There are two different things to consider here:
- People's response to the main question about where they heard about EA, which was a selection from a fixed list. So this just means the respondent selected "Educational course (e.g., lecture, class, MOOC)", with no additional classification from us.
- Their responses to the open comment follow-up question asking for more detail: the majority of these (>75%) refer to a university course or the Singer MOOC.
In most cases where someone joins EA through an activity run by their EA group, they'll select EA Group. I went through references to "group" in the comments for those who did not select EA Group and most (23/36) were not referring to an EA Group, 3 referred to a friend referring them to a group, 2 referred to seeing an ad for a group, 5 mentioned something else first introducing them to EA but a group being useful for them beginning to seriously engage and the rest were miscellaneous/uncategorisable. I went through comments of those who did select EA Group and 9/111 (8%) mentioned a fellowship. You can see a more detailed analysis of comments by those who selected EA Group in 2020 here, where 7% mentioned a fellowship, but a larger number mentioned an event or fresher's fair.
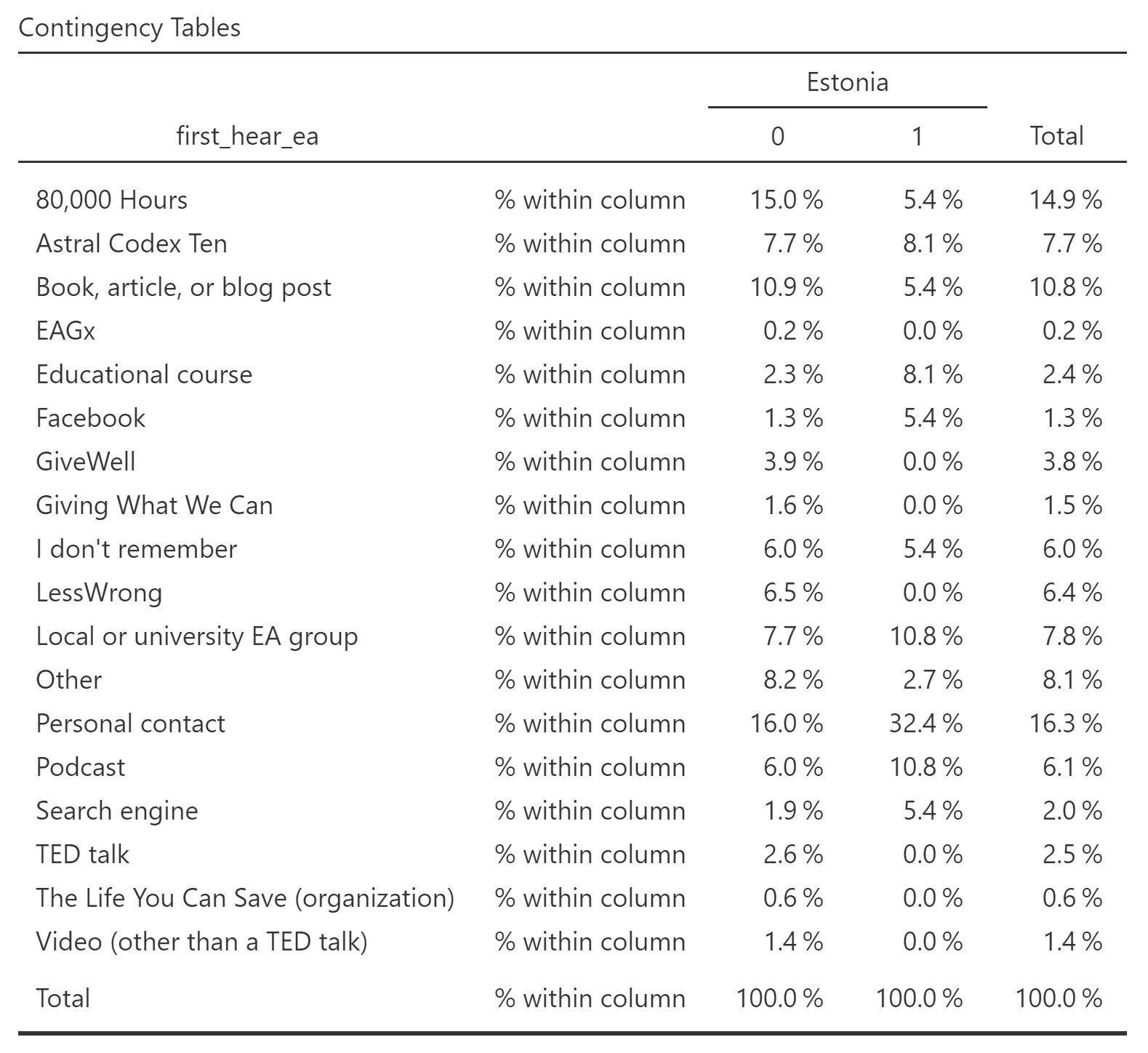
Alternatively, would it be possible to ask for country-specific data analysis?
For Estonia, there are not very clear differences (p=0.023). This is from n=37 for Estonia, so we should not be very confident about the differences.
Thanks for raising this interesting point!
If we look direction at the association between active outreach and levels of engagement, we see no strong relationship (aside from within the very small "No engagement with EA" category).
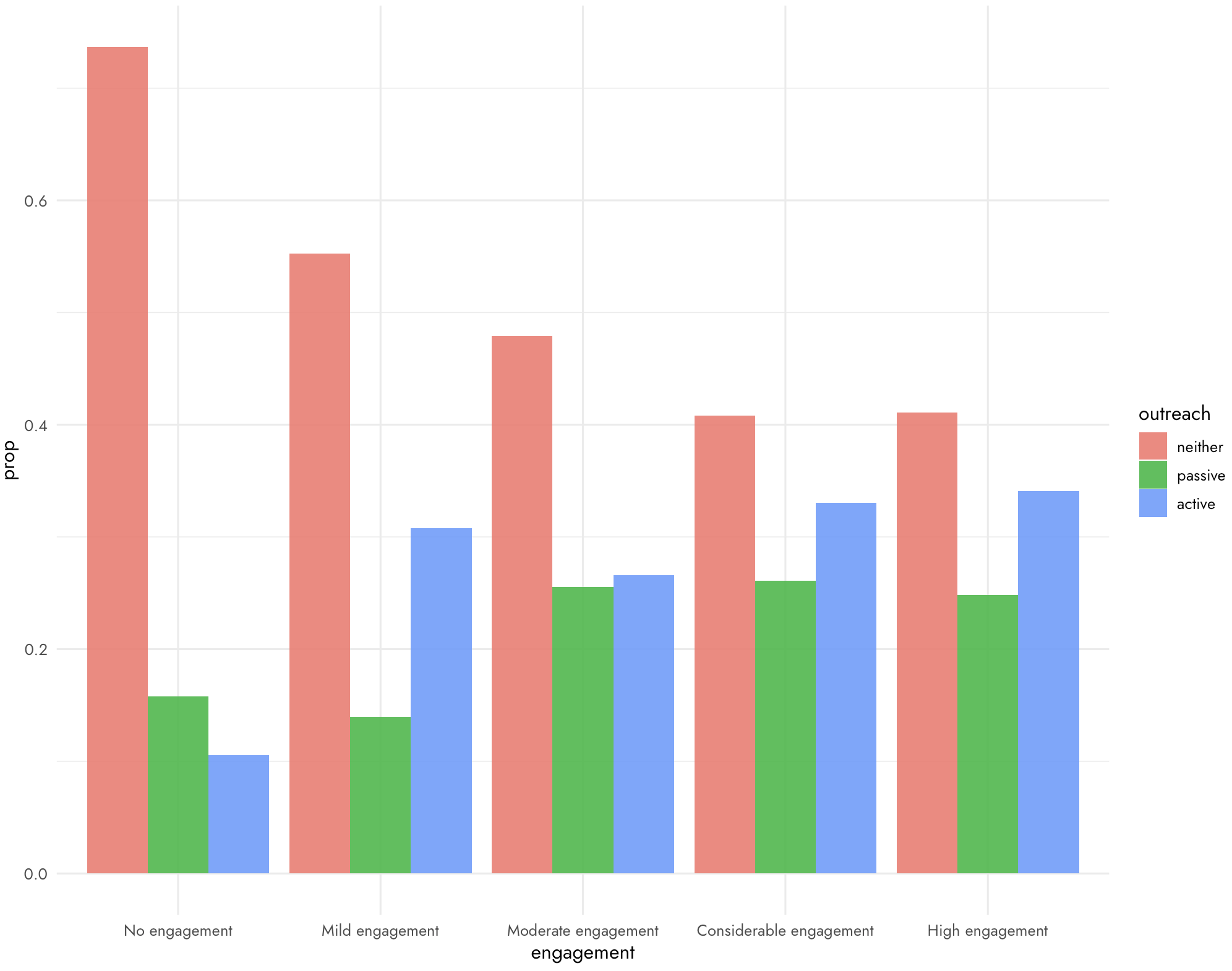
I agree that it's intuitively plausible, as you say, that people who actively sought out EA might be expected to be more inclined to high engagement.
But I think that whether the person encounters EA through active outreach (influencing selection) may often be in tension with whether the person encounters EA through a high-touch form of engagement (leading to different probability of continued engagement). For example, EA Groups are quite active outreach (ex hypothesi, leading to lower selection for EA inclination), but higher touch (potentially leading to people being more likely to get engaged), whereas a book is more passive outreach (ex hypothesi, leading to higher selection for EA inclination), but lower touch (and so may be less likely to facilitate engagement)[1].
- ^
There may be other differences between these particular two examples of course. For example, EA Groups and EA books might select in different ways.
@titotal I'm curious whether or to what extent we substantively disagree, so I'd be interested in what specific numbers you'd anticipate, if you'd be interested in sharing.
- My guess is that we'll most likely see <30% reduction in people first hearing about EA from 80K next time we run the survey (though this might be confounded if 80K don't promote the EA Survey so much, so we'd need to control for that).
- Obviously we can't directly observe this counterfactual, but I'd guess that if a form of outreach that was 100% active shut down, we'd observe close to a 100% reduction (e.g. if everyone stopped running EA Groups or EAGs, we'd soon see ~0% people hearing about EA from these sources).[1]
- ^
I don't say strictly 0% only because I think there's always the possibility for a few unusual cases, e.g. someone is googling how to do good and happens across an old post about EAG or their inactive local group.
Thanks James! Yes, we'd encourage any readers to flag what questions they would find most useful.