Below is the video and transcript for my talk from EA Global, Bay Area 2023. It's about how likely AI is to cause human extinction or the like, but mostly a guide to how I think about the question and what goes into my probability estimate (though I do get to a number!)
The most common feedback I got for the talk was that it helped people feel like they could think about these things themselves rather than deferring. Which may be a modern art type thing, like "seeing this, I feel that my five year old could do it", but either way I hope this empowers more thinking about this topic, which I view as crucially important.
You can see the slides for this talk here
Introduction
Hello, it's good to be here in Oakland. The first time I came to Oakland was in 2008, which was my first day in America. I met Anna Salamon, who was a stranger and who had kindly agreed to look after me for a couple of days. She thought that I should stop what I was doing and work on AI risk, which she explained to me. I wasn't convinced, and I said I'd think about it; and I've been thinking about it. And I'm not always that good at finishing things quickly, but I wanted to give you an update on my thoughts.
Two things to talk about

Before we get into it, I want to say two things about what we're talking about. There are two things in this vicinity that people are often talking about. One of them is whether artificial intelligence is going to literally murder all of the humans. And the other one is whether the long-term future – which seems like it could be pretty great in lots of ways – whether humans will get to bring about the great things that they hope for there, or whether artificial intelligence will take control of it and we won't get to do those things.
I'm mostly interested in the latter, but if you are interested in the former, I think they're pretty closely related to one another, so hopefully there'll also be useful things.
The second thing I want to say is: often people think AI risk is a pretty abstract topic. And I just wanted to note that abstraction is a thing about your mind, not the world. When things happen in the world, they're very concrete and specific, and saying that AI risk is abstract is kind of like saying World War II is abstract because it's 1935 and it hasn't happened yet. Now, if it happens, it will be very concrete and bad. It'll be the worst thing that's ever happened. The rest of the talk's gonna be pretty abstract, but I just wanted to note that.
A picture of the landscape of guessing
So this is a picture. You shouldn't worry about reading all the details of it. It's just a picture of the landscape of guessing [about] this, as I see it. There are a bunch of different scenarios that could happen where AI destroys the future. There’s a bunch of evidence for those different things happening. You can come up with your own guess about it, and then there are a bunch of other people who have also come up with guesses.
I think it's pretty good to come up with your own guess before, or at some point separate to, mixing it up with everyone else's guesses. I think there are three reasons that's good.
First, I think it's just helpful for the whole community if numerous people have thought through these things. I think it's easy to end up having an information cascade situation where a lot of people are deferring to other people.
Secondly, I think if you want to think about any of these AI risk-type things, it's just much easier to be motivated about a problem if you really understand why it's a problem and therefore really believe in it.
Thirdly, I think it's easier to find things to do about a problem if you understand exactly why it's a problem.
So today I'm just going to talk about the stuff in the thought bubble [in the slide] – not ‘what does anyone else think about this?’, and how to mix it together. I'm encouraging you to come up with your own guess. I'm not even going to cover most of the stuff in this thought bubble. I'm just going to focus on one scenario, which is: bad AI agents control the future. And I'm going to focus on one particular argument for this, which involves bad AI agents taking over the future, which I think is the main argument that causes people to have very high probabilities on doom. So I think it's doing a lot of the work in the thinking people have about this. But if you wanted to come up with an overall guess, I think you should also think about these other things [on the slide].
Argument from competent bad AI agents: first pass

I think that the very basic argument in outline is:
- At some point there's going to be very smart AI.
- If there's very smart AI, it's probably going to have goals – a lot of it, in the sense that there are things in the world that it will want to happen and it will push toward those things happening.
- If it has goals, those goals will be bad, in the sense that if it succeeds at its goals we won't like what happened in the long term.
- If all those things come to pass, if there is smart AI with goals and the goals are bad, then the future will be bad.
I think at this level of abstraction, high level, it doesn't really seem to work. I don't think (4) is true. You could have some amount of AI which is smart and has goals and they're bad, and you know, maybe the whole world together could still win out. So I want to make a more complicated and quantitative argument about this.
Before we do that, I want to step back and talk about: what is special about AI at all? Why might this be the thing that ends the world?
I think there are two interesting things about AI, but before I even get to them: what's going on in the world, in general? Seems like one thing is: lots of thinking. Like every year, it'd be 8 billion years of thinking, give or take. And when I say thinking, I mean a fairly broad set of things. For instance, you're deciding where to put your foot on the floor; you see where the floor is and exactly how gravity is acting on you and stuff like that and slightly adjust as you walk. That's a sort of mental processing that I'm counting as thinking.
An important thing about thinking is that it's often helping you achieve some goal or another, like maybe it's helping you walk across the floor, maybe it's helping you… [say] you're thinking about what to write in an email, it's helping you get whatever you wanted from that email.
So thinking is kind of like a resource, like gasoline. You have a stock of it. In the next year, I'm gonna get to think about things for a year. It could be all kinds of different things. But at the end of the year, there will be some specific goals that I tried to forward with this thinking and maybe I'll be closer to them.
Two new things: cognitive labor and agents

One thing that is going to be different [with AI] is just huge amounts more thinking: the industrial production of thinking. The sort of useful thinking that we're putting toward things I'm gonna call “cognitive labor”. So, much more of it. And another part of that is it might just be distributed differently. At the moment it's somewhat equal between people. Each person gets an allotment of it with their head which they can use for whatever they value, and often they sell some of it. But usually they don't sell all of it and so they can still forward their own interests.
With this new big ocean of thinking that could get produced, it's sort of unclear how it'll be distributed. Maybe it'll be very unequal, maybe it'll go to people with bad goals. So that's potentially disturbing to begin with.
But a second thing that could go on is AI might bring about more agents in the process. And they might also just have different values to humans because in the process of making AI systems, they might be kind of agentic. When I say agents here, I mean they're the things controlling how the cognitive labor is spent. They have values and they'll try and use it to get something.
So I think each of these things on its own would be potentially disruptive to the world. Having a whole bunch more of a resource appear can be disruptive and having a bunch of new “people” who are perhaps bad seems potentially disruptive. But I think the two things happening together is where things get very scary, potentially, because if the new distribution of cognitive labor is such that it mostly lands in the hands of bad agents, then things could be very bad.
Argument from competent bad AI agents: quantified (ish)

All right, so with these concepts in mind, let's go back to the argument we are trying to make. Here's a more complicated version of it, somewhat quantified. I'm going to try and ask, how much cognitive labor will be working toward bad futures versus good futures?
First we're going to ask, how much new cognitive labor will there be? We're going to ask, how much of it will be captured by these new AI agents? We're going to ask, of their goals, how often are they going to be involved in bad futures? Which might be that they just want the future to be bad in the long term, according to us. Or it might just be that they want all of the resources for some other thing such that we don't get to use them for whatever we wanted in the future.
And then we need to compare that to what fraction of the cognitive labor actually goes to good futures, which probably isn't all of the cognitive labor under human control. It seems like we work towards all kinds of things happening. Then, at the end, I'll consider, if we're in a situation where there is more going toward bad than good, does that mean that we are doomed, or what other complications might come into this?
1. How much new cognitive labor?
I think you don't need to look at this diagram in much detail. Basically, the idea is there's going to be a lot of new cognitive labor potentially. Probably much more than human cognitive labor at some point. So I'm just going to basically ignore this and we'll just talk about that ocean of new cognitive labor, not how big it is compared to the existing tiny pool of cognitive labor.
2. How much of the cognitive labor is controlled by new AI agents?
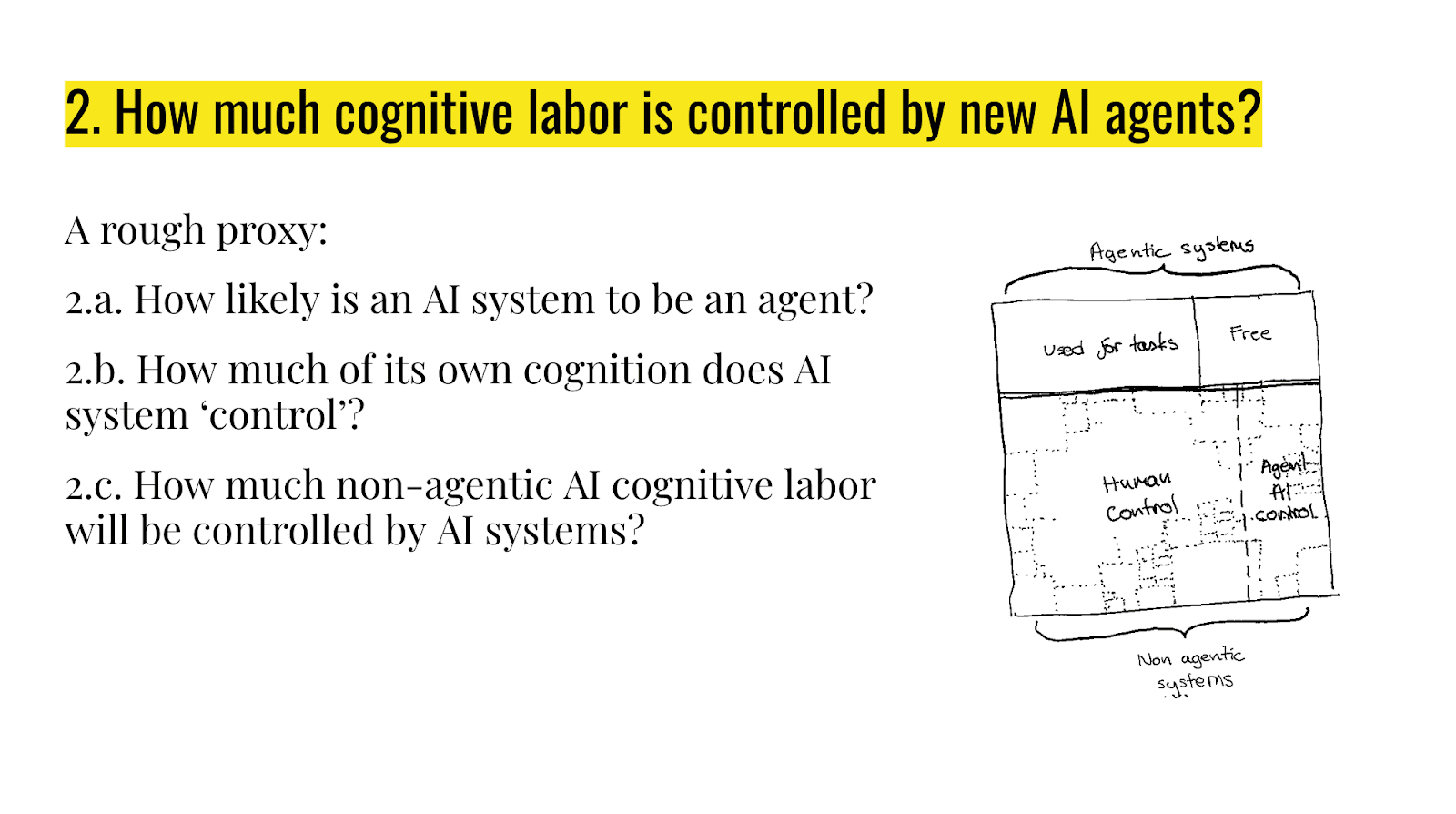
I think we can break this down into: how likely is an AI system to be an agent? Then that will be what fraction of the cognitive labor is in agents, and then of the cognitive labor that's going to agents, what fraction of it do those agents get to use for their own goals? Like, if they have some sort of long-term nefarious purposes they're working toward, they probably can't put all of their effort into that because they have to Google stuff for you or whatever. They were produced for some reason, and if it's in a competitive situation, maybe they won't keep on being used if they're not doing the stuff that humans wanted them to do. So they have to use at least some cognitive labor for that, potentially.
And then thirdly, for the non-agentic AI cognitive labor, how much of that will get controlled by the AI system somehow? That seems like it could be controlled by the human agents or the AI agents. There is a question of how it gets split up.
So now we're going to go into detail on these.
2a. How likely is a system to be an agent?

There are a whole bunch of considerations here. I'm not sure I'll go into all of them. I think a particularly big one is just economic forces to create agents. The alternative to agents is something like a tool that is not trying to do anything in the world, but you can use it to do something that you wanted, like a souped-up calculator or something; Google maps is a tool. I guess we hope that things like ChatGPT are tools at this point.
It's often useful to have a thing that is an agent because if you can convey to it the goal that you would like it to have, then it can just go out and do that thing instead of you having to do that. This is often a value add with employing humans to do things, so pretty plausibly people want to pay for that in AIs.
But I think it seems good to think of agency as something like a spectrum. The most extreme levels of agency would look like, for every action you take, you can see the whole distribution of possible futures that happen as a result and you can evaluate all of them perfectly and then you can take the action that leads to the highest expected utility. That seems pretty infeasible, you know, if you're not God. So probably we're not going to end up that close to that.
Rocks are very non-agentic, humans are somewhere in the middle, where they often seem like they have goals to some extent but it's not that clear and they're not that consistent. It seems like if a thing is about as agentic as a human, I would start being worried about it. Probably a spectrum is far too simple a way of thinking of this. Probably it's more complicated, but I think economic forces probably push more toward the middle of the spectrum, not the very extreme end, for the reason that: suppose you're employing someone to plan your wedding, you would probably like them to stick to the wedding planning and, you know, choose flowers and music and stuff like that, and not try to fix any problems in your family at the moment so that the seating arrangement can be better. [You want them to] understand what the role is and only do that. Maybe it would be better if they were known to be very good at this, so things could be different in the future, but it seems to be [that] economic forces push away from zero agency but also away from very high agency.
Next consideration: spontaneous emergence.
We don't know how machine learning systems work. We do know how to make them sometimes, which is, you get a random neural network and you ask it to do a thing for you. You're like, "Recognize this, is it a cat?" And it's like, "No," and you're like, "It was a cat, alright." And then you change every little weighting in it so it's more likely to give the answer you want and then you just keep doing that again and again until it does recognize the cat, but you don't really know what's happening inside it at all. You just know that you searched around until you found some software that did the thing.
And so you don't know whether that software is an agent, and there's a question of: how likely is software to be an agent? There's also a question of how useful agents are. It seems like if they're pretty useful, you could imagine that you often, if trying to do something efficiently, end up with things that are agents, or where some part of them is an agent. I think that's a pretty open question, to my knowledge, but could happen.
Relatedly, there are these coherence arguments, but actually I'm not going to go into that after repeated feedback that I have not explained it well enough. Another consideration is that, at the moment, we try to get AI to do human-like things often by just copying humans. Humans are at least somewhat agentic, as we've noted. So AI, which copies humans, can also be somewhat agentic: it seems like the Bing chat does threaten people, so that seems a bit like it's trying to achieve goals. Hopefully it's not, but you could imagine if you copy humans pretty well, you get that sort of thing for free.
In general, being an agent is more efficient than less being-an-agent 'cause you're not treading on your own toes all the time by being inconsistent. So that seems like probably some pressure toward agents effectively having more cognitive labor to spend on things 'cause they're not wasting it all the time. So you might just expect, if at some point in time there are some fraction of agents, that over time things might become more agentic as those things went out and took control.
I think for some people that's a very big consideration, pushing toward in the longer term it just being entirely very agentic agents. I find all of these things kind of ambiguous. I think the economic forces [consideration] is pretty good, but it doesn't push toward all systems being agents, just at least some of them, and as I said, it doesn't push all the way there, and I'm less sure what to make of these other ones. So I end up somewhere kind of middling. I'm going to not actually go into these ones very much.
2b. How much of its own cognition does an AI system ‘control’?

If there's an agent system, how much of its own cognition does it get to control? I can imagine this being pretty high, for instance if it's not in a kind of economic situation where it's competing with other systems to be used, or being very low if things are very competitive. I'm gonna go with 50% as a guess right now and move on.
2c. How much non-agentic AI cognitive labor will be controlled by AI systems?
So for all of the tool AIs, how much of that cognitive labor will the agent AIs manage to get control of across the whole range of scenarios. I'm also not gonna go into that in very much detail at the moment. In fact, no more detail, I'm gonna guess 20% and move on. But these are things you could think more about if you wanted to come up with a better guess.
3. What fraction of AI goals are bad?

All right, then: what fraction of AI goals are bad? That was like, what fraction of systems are agents? Okay, are they bad? I think some people think a very high fraction of AI goals are bad. I think the argument for them being bad is roughly: it's very hard to find good goals for an AI, and it's easy to find goals that are bad yet appealing, and the reason that's important to have here is, well, otherwise we might think [that if] we can't find good goals, we just won't make AI systems with goals, except maybe by accident. But it seems like it's easy to want to make them anyway.
And then somewhat separately, even if we did know which goals we would like an AI system to have, it seems quite hard to give AI systems goals anyway, to our knowledge. So good to go into detail on these.
3a. Why is it hard to find good goals?

One issue is: it is claimed that most goals are in conflict because to some extent, all goals would benefit from having all of the resources.
So if you imagine that Alice and Bob are going to have a party, and Alice just really wants the party to have a lot of cupcakes, as many as possible, and Bob just really wants it to have really good music. You might think, "Ah, their goals are consistent with one another." You can imagine a party that has both of these things and it would be amazing for both of them, but if they only have like $200 to spend on the party, then their interests are very much in conflict, because Alice would like to spend all of that money on cupcakes and Bob would like to spend all of it on, you know, hiring someone to play music.
So I think there's a question here of: how many goals are really in conflict in this way? Because lots of goals don't really ask for all of the resources in the universe. So there's a question of: of the goals that AI systems might end up with, how many end up in conflict?
But there is a theoretical reason to expect other utility maximizers to want to take your resources if they can, which wouldn't be that much of a problem if they had reasonably good goals. Like Alice might be fine with Bob taking all of the money if she also likes music quite a lot, but not as much as cupcakes.
But a separate problem is that maybe that the values themselves are just not what we want at all. So one argument given for this is just that value space is very large; there are just a whole lot of ways you could want the universe to be. So if someone has different values from you, probably they're bad.
I think this is a pretty bad argument. I think you could also say ‘the space of configurations of metal is very large, so what are the chances that one of them would be a car?’, but I think we managed to find cars in the space of metal configurations. So I think intuitively, how big the space seems is not that relevant. In many big spaces we just have a way of getting to the thing that we want.
Another kind of argument that is made is just ‘value is fragile’, which is the thought that if the thing you value is here, if you move very, very slightly away from it, how much you value it just goes down very quickly. I think that the thought experiment suggesting this, originally proposed by Eliezer Yudkowsky, is something like: if someone was writing down human values and they missed out boredom, you might end up with a world that is extremely boring, even though it was good on lots of other fronts, and maybe that would be quite bad.
This seems to be not the kind of error that you make with modern machine learning, at least. It seems similar to saying, ‘Well, if you wrote down what a human face looks like and you just missed out the nose, then it would look very wrong.’ But I think that this kind of ‘set a high-level feature to zero’-type error doesn't seem like the kind of mistake that's made. For instance, [on the slide there’s] a human face made by AI and I think it just looks very accurate. It's much better than a face I could draw if I was trying to draw a human face.
Intuitively, similarly, it seems to me that if an AI tried to learn my values, maybe it would learn them much more correctly than I could write them down or even recognize them. So I guess it's pretty unclear to me that the level of detail needed to get close enough to human values is not available to AI systems.
I think there's various counterarguments to this, that I'm not going to go into, along the lines of, ‘Well, this face is not a maximally human face-like face, according to AI systems. If you ask for that you'll get something more horrifying.’
This other picture [on the slide] is illustrating the thought that it seems not clear what my values are specifically. As I said, they're probably not very coherent, so it seems like if I sat down forever and figured out what they are, there's a small cloud of different things they could be and it might not be clear that there's a real answer to what they are at the moment, and there are a bunch of other humans. You probably have different values to me, very slightly at least; we're all just physical systems who learned human values somehow. And so I think of human society as a bunch of these different little overlapping clouds. So I think it seems unlikely that human values are, like, one point.
And so if AI systems can learn something like human values but inaccurately – intuitively, they’re some distance from the true answer that they are. But also, probably we're okay with things being some distance from the true answer, because to start with, there isn't really a true answer for me, say, and then I feel like if another human got to decide what happened with the long run future, pretty plausibly, I quite like it. So I think this is evidence against value being very fragile.
Some different thoughts in that ‘maybe it's not so hard to find good goals’ direction. It seems like short-term goals are not very alarming in general, and a lot of goals are relatively short term. I think in practice when I have goals, often I don't try to take over the world in order to get them. Like I'd like a green card… for none of the things I try to do, I try to take over the world in the process. You might think this is 'cause I'm not smart and strategic enough. I think that's not true. I think if I was more smart and strategic I would actually just find an even more efficient route to get a green card than taking over the world, or even than now. I don't think it would get more world-taking-over-y.
A counter-argument to that counter-argument is, ‘Well, there are selection effects though, so if some creatures have short-term goals and some have long-term goals, probably if we come back in 50 years, all of the ones with long-term goals are still around accruing resources and stuff’. So yeah, we should worry about that.
A different thought is, ‘Well, why would you expect AI systems to learn the world really well, well enough to do stuff, but be so bad at learning human values exactly?’ I'm not going to go into that in detail. I think there's been some thinking about this under the heading ‘sharp left turn’ that you can look into if you want. So I guess overall with ‘how hard is it to find good goals?’, I think it’s pretty unclear to me. It could be not that hard, it’s a pretty broad distribution.
3b. Why is it easy to find appealing bad goals?

Why is it easy to find appealing bad goals? I think one issue is just: lots of things have externalities. I think it's not that hard to think of AI systems that would be immediately profitable to build, but if you don't really know what they're going to do in the long term, and they might have their own values that they want to pursue in the world and that might be bad, that badness is not going to accrue to the person deciding to put them into the world unless it's very fast, which it might not be.
I think also it's just easy to make errors on this. People have very different views about how dangerous such things are. Probably many of them are an error in one direction or the other.
3c. Why can’t we give AI systems goals anyway?

Why can't we give AI systems goals? If we have some goals that we want to give them, why is it hard to give them those goals? One thing is we just don't have a known procedure for it, so that's sort of a red flag.
But I think there are theoretical reasons to think it would be hard, where one of them is just: if you have a finite amount of training data, maybe you can make the system do pretty well on the distribution you're showing it, but if it's in some new distribution, there's a lot of different values that it could have that cause it to behave in the way that you've seen. So without really understanding what happens inside the system, it's hard to know if it's what you wanted.
And now there's this issue of deceptive alignment, where the thought there is: if you made this system and you don't know what it is, you don't know what it values. Maybe you think you've made something that's like an agent, but there's two different kinds of agents you might have made that do the thing you want, where one of them really values the thing you want: it really values correctly identifying cats. But the other kind of system is one that understands the world well enough to realize that you are going to keep running it if it does the thing that you want, and maybe it wants to keep being run for whatever reason. At that point it can have any other values as long as they make it want to continue existing and being run, and so if you keep on training it, it will continue to be good at understanding that it's in that situation, but its values could drift around and be anything. So then when you put it out in the world, who knows what it does, is the thought.
I think to me that seems like a pretty important argument that I don't understand very well. I think if I'm going to think more about this, that's a place I would look at. I guess I would look at many of these places more, but that's a particularly important one.

So I guess, overall it seems pretty unclear how hard it is to find good goals. I think it's definitely easy to find bad yet appealing goals. I guess on the ‘can we give AI systems goals anyway?’, a counter-argument to all of that is ‘Well, maybe we can understand what's going on inside them enough to figure out broadly whether they're tricking us or something else’. So I don't think that's that hopeless but it does seem tricky at this point.
Overall guesses: what % of cognitive labor goes to bad goals?
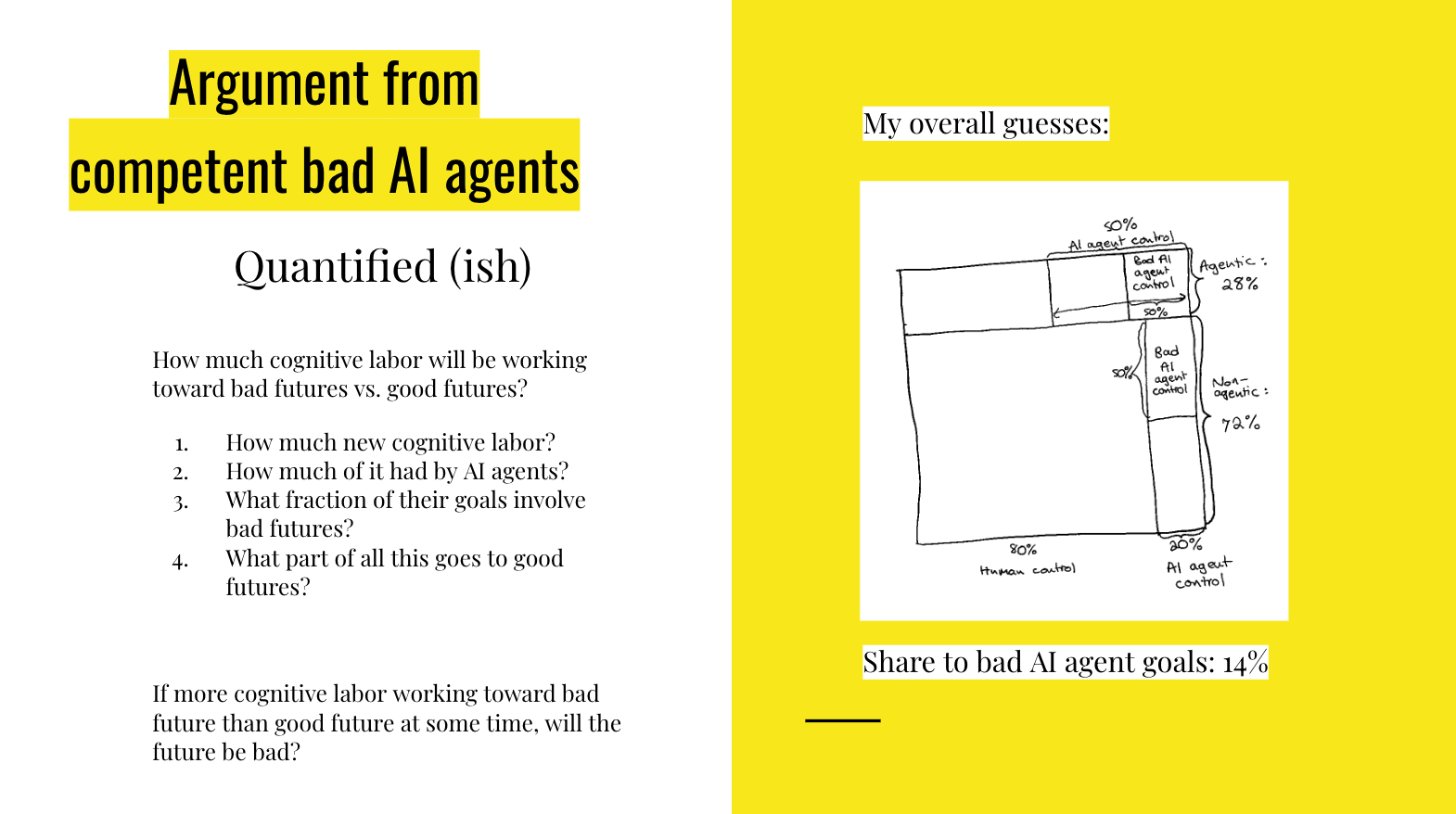
So putting these things together, here's a picture of some guesses that I have about things, but you know, to be clear, these are numbers that I just sort of made up. I said ‘You know, 28% agentic systems, and then you know, maybe half of the effort that agentic systems are putting into things do they get to control for their own things, and maybe half of them are bad, and then I imagine that agentic AI systems control less of the non-agentic cognitive labor…’ All of this gets you in the end a 14% share of cognitive labor to bad goals. But this isn't that helpful because we want to know: in how many worlds is more cognitive labor going to bad goals than to good goals, and this is sort of just all flattened down together.
So I guess after making these slides, I made a better model of the distribution of these different things, and I think overall it came out as 27% of worlds get more cognitive labor going to bad things than good things, on my made up numbers, which includes also making up something for Step 4 here, which we didn't go into, which is ‘what part of all of this goes to good futures?’ Humans put their cognitive labor into lots of different things. It's hard to say what fraction of them are good futures, so I made something up.
But I think even if in a particular world more cognitive labor is going to bad things than good things, there's still a question of, does that mean we're doomed?
If more cognitive labor goes to a bad future, will the future be bad?

This is an extremely simplified model. I think there are two main considerations here where things might differ a lot from that. One is, there's just a lot of different bad goals.
So if mostly people trying to make the future go well are pushing for one particular kind of future and then there are many more people pushing for, or many more agents of some sort pushing for all kinds of different bad things, they're probably acting in conflict with one another and can't necessarily do as well. That seems like it probably makes a difference.
Secondly, there are a lot of other resources than cognitive labor: it's nice to be able to own stuff. If AI systems can't own money or earn money for their labor, if humans own them and whenever the AI system does something useful, the human gets resources, then it's less clear that smart AI systems accrue power over time in a more market-y situation at least.
So those are things that cause me to adjust the probability of doom downward. I probably want to say something like 18% if I'm gonna make up a number at this point.
Considerations regarding the whole argument

Here we have various considerations affecting this whole argument. You might have noticed that it was pretty vague and unclear in a lot of places and also just not very well-tested and thought about by lots of people or anything. I think it probably commits the so-called ‘multiple stage fallacy’ of reasoning by multiplying different things together. My guess is this is fine, but I think there's a fair amount of disagreement on that.
I think there were probably pretty big biases in the collection of arguments. I think the arguments for these things that you see around were probably collected by people who are more motivated to explain why AI is risky than to really check that maybe it's not risky. I think I'm probably biased in the other direction. I'd probably rather get to decide that it's fine.
I think the thing that was raised by a few people talking about this is like: alright, there are a bunch of these scenarios where you know, maybe there aren't that many really bad AI systems trying to take over the world, but there are some, and they're pretty agentic. Does that sound existentially safe, or does it just seem like things are gonna go badly some other day soon? I think that's a reasonable concern, but I dunno, I think most of the time things don't really seem existentially safe. I think saying it's an X-risk unless you can tell a story for how we're definitely gonna be okay forever is probably too high a bar. I probably want to just focus on situations that really seem like we're going to die soon or get everything taken from us soon.
So overall, I don't know that many of these change my number that much.
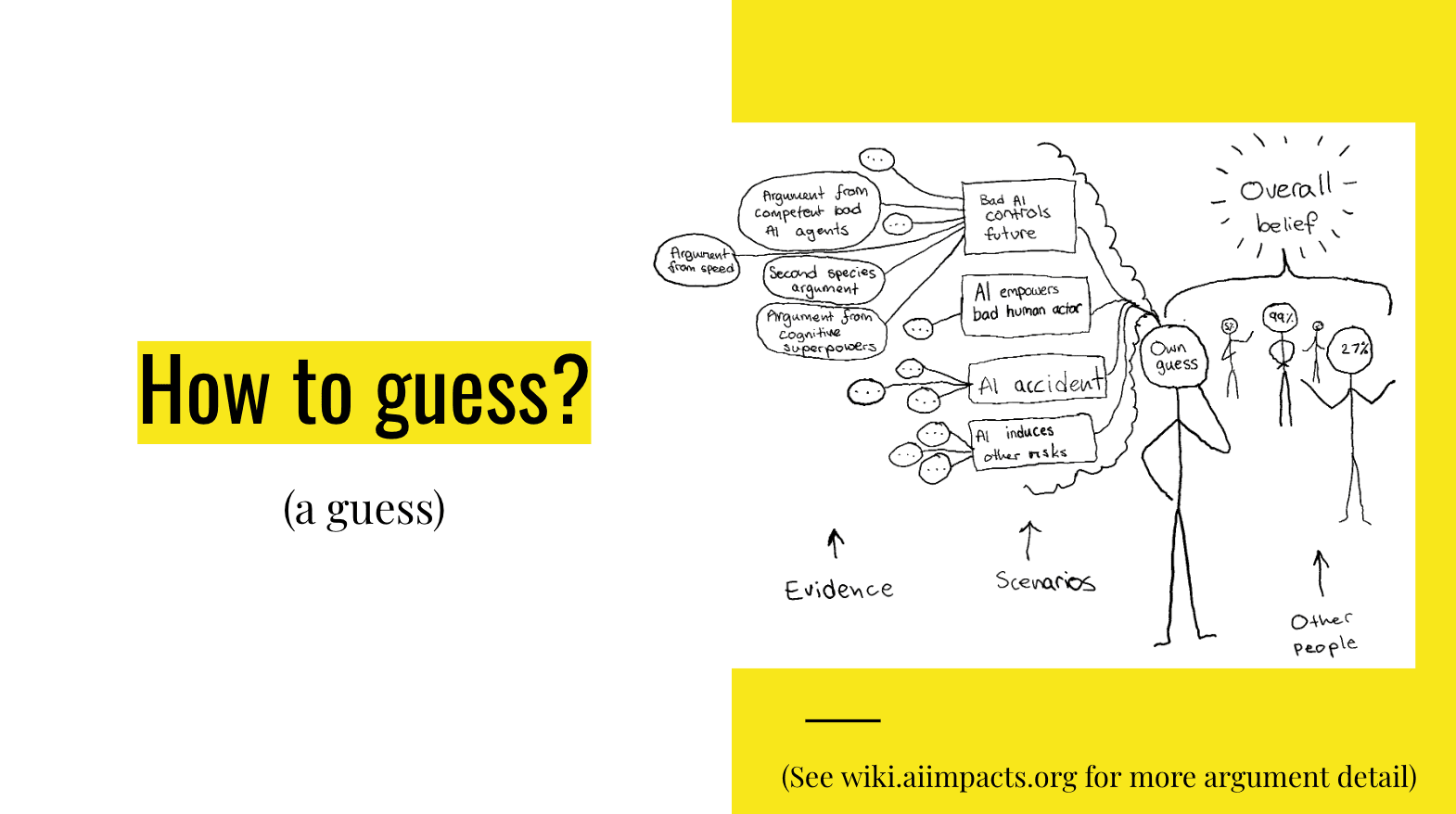
So this was all in the category of ‘argument from competent bad AI agents’, which is affecting this one scenario of ‘bad AI controls the future’. If you want to come up with an overall guess on this, you'd want to think about other arguments and different scenarios, and so on. And if you wanted to actually act on this, I think you would probably want to listen to what other people are saying as well and combine these things.
I think my hope with sharing this with you is not so much that you will believe this argument or think it is good or take away my number, but that you see the details of coming to some sort of guess about this and think, "Oh, that seems wrong in ways. I could probably do better there." Or you know, "This thing could be built on more." Or just come up with your own entirely different way of thinking through it.
Conclusions

In conclusion: this morning when I could think more clearly 'cause I wasn't standing on a stage, I thought the overall probability of doom was 19%, in sum, but I don't think you should listen to that very much 'cause I might change it tomorrow or something.
I think an important thing to note with many of the things in these arguments is that they could actually be changed by us doing different things. Like if we put more effort into figuring out what's going on inside AI systems, that would actually change the ‘how likely is it that we can't make AI systems do the things we want?’ parameter.
I hope it seemed like there was a lot of space for improvement in this overall argument. I think I would really just like to see more people thinking through these things on the object level and not deferring to other people so much, and so I hope this is encouraging for that. Thank you.
Thanks for writing this up!
Quick thing I flagged:
> Probably a spectrum is far too simple a way of thinking of this. Probably it's more complicated, but I think economic forces probably push more toward the middle of the spectrum, not the very extreme end, for the reason that: suppose you're employing someone to plan your wedding, you would probably like them to stick to the wedding planning and, you know, choose flowers and music and stuff like that, and not try to fix any problems in your family at the moment so that the seating arrangement can be better. [You want them to] understand what the role is and only do that. Maybe it would be better if they were known to be very good at this, so things could be different in the future, but it seems to be [that] economic forces push away from zero agency but also away from very high agency.
I think this intuition is misleading. In most cases we can imagine, a wedding planner that attempts to do other things would be bad at it, and thus undesirable. There's a trope of people doing more than they're tasked for, which often goes badly - one reason is that given that they were tasked with something specific, the requester probably assumed that they would mess up other things.
If the agent is good enough to actually do a good job at other things, the situation would look different from the start. If I knew that this person who can do "wedding planning" is also awesome at doing many things, including helping with my finances and larger family issues, then I'd probably ask them something more broad, like, "just make my life better".
In cases where I trust someone to do a good job at many broad things in my life or business, I typically assign tasks accordingly.
Now, with GPT4, I'm definitely asking it to do many kinds of tasks.
I think economic forces are pushing for many bounded workflows, but because that's just more effective and economical - it's easier to make a great experience at "AI for writing" - not because people really otherwise would want it that way.