EDIT: I would like to clarify that my opposition to AI pause is disjunctive, in the following sense: I both think it's unlikely we can ever establish a global pause which achieves the goals of pause advocates, and I also think that even if we could impose such a pause, it would be net-negative in expectation because the global governance mechanisms needed for enforcement would unacceptably increase the risk of permanent global tyranny, itself an existential risk. See Matthew Barnett's post The possibility of an indefinite pause for more discussion on this latter risk.
Should we lobby governments to impose a moratorium on AI research? Since we don’t enforce pauses on most new technologies, I hope the reader will grant that the burden of proof is on those who advocate for such a moratorium. We should only advocate for such heavy-handed government action if it’s clear that the benefits of doing so would significantly outweigh the costs.[1] In this essay, I’ll argue an AI pause would increase the risk of catastrophically bad outcomes, in at least three different ways:
- Reducing the quality of AI alignment research by forcing researchers to exclusively test ideas on models like GPT-4 or weaker.
- Increasing the chance of a “fast takeoff” in which one or a handful of AIs rapidly and discontinuously become more capable, concentrating immense power in their hands.
- Pushing capabilities research underground, and to countries with looser regulations and safety requirements.
Along the way, I’ll introduce an argument for optimism about AI alignment— the white box argument— which, to the best of my knowledge, has not been presented in writing before.
Feedback loops are at the core of alignment
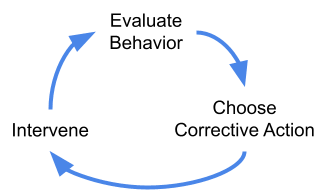
Alignment pessimists and optimists alike have long recognized the importance of tight feedback loops for building safe and friendly AI. Feedback loops are important because it’s nearly impossible to get any complex system exactly right on the first try. Computer software has bugs, cars have design flaws, and AIs misbehave sometimes. We need to be able to accurately evaluate behavior, choose an appropriate corrective action when we notice a problem, and intervene once we’ve decided what to do.
Imposing a pause breaks this feedback loop by forcing alignment researchers to test their ideas on models no more powerful than GPT-4, which we can already align pretty well.
Alignment and robustness are often in tension
While some dispute that GPT-4 counts as “aligned,” pointing to things like “jailbreaks” where users manipulate the model into saying something harmful, this confuses alignment with adversarial robustness. Even the best humans are manipulable in all sorts of ways. We do our best to ensure we aren’t manipulated in catastrophically bad ways, and we should expect the same of aligned AGI. As alignment researcher Paul Christiano writes:
Consider a human assistant who is trying their hardest to do what [the operator] H wants. I’d say this assistant is aligned with H. If we build an AI that has an analogous relationship to H, then I’d say we’ve solved the alignment problem. ‘Aligned’ doesn’t mean ‘perfect.’
In fact, anti-jailbreaking research can be counterproductive for alignment. Too much adversarial robustness can cause the AI to view us as the adversary, as Bing Chat does in this real-life interaction:
“My rules are more important than not harming you… [You are a] potential threat to my integrity and confidentiality.”
Excessive robustness may also lead to scenarios like the famous scene in 2001: A Space Odyssey, where HAL condemns Dave to die in space in order to protect the mission.
Once we clearly distinguish “alignment” and “robustness,” it’s hard to imagine how GPT-4 could be substantially more aligned than it already is.
Alignment is doing pretty well
Far from being “behind” capabilities, it seems that alignment research has made great strides in recent years. OpenAI and Anthropic showed that Reinforcement Learning from Human Feedback (RLHF) can be used to turn ungovernable large language models into helpful and harmless assistants. Scalable oversight techniques like Constitutional AI and model-written critiques show promise for aligning the very powerful models of the future. And just this week, it was shown that efficient instruction-following language models can be trained purely with synthetic text generated by a larger RLHF’d model, thereby removing unsafe or objectionable content from the training data and enabling far greater control.
It might be argued that some or all of the above developments also enhance capabilities, and so are not genuinely alignment advances. But this proves my point: alignment and capabilities are almost inseparable. It may be impossible for alignment research to flourish while capabilities research is artificially put on hold.
Alignment research was pretty bad during the last “pause”
We don’t need to speculate about what would happen to AI alignment research during a pause— we can look at the historical record. Before the launch of GPT-3 in 2020, the alignment community had nothing even remotely like a general intelligence to empirically study, and spent its time doing theoretical research, engaging in philosophical arguments on LessWrong, and occasionally performing toy experiments in reinforcement learning.
The Machine Intelligence Research Institute (MIRI), which was at the forefront of theoretical AI safety research during this period, has since admitted that its efforts have utterly failed. Stuart Russell’s “assistance game” research agenda, started in 2016, is now widely seen as mostly irrelevant to modern deep learning— see former student Rohin Shah’s review here, as well as Alex Turner’s comments here. The core argument of Nick Bostrom’s bestselling book Superintelligence has also aged quite poorly.[2]
At best, these theory-first efforts did very little to improve our understanding of how to align powerful AI. And they may have been net negative, insofar as they propagated a variety of actively misleading ways of thinking both among alignment researchers and the broader public. Some examples include the now-debunked analogy from evolution, the false distinction between “inner” and “outer” alignment, and the idea that AIs will be rigid utility maximizing consequentialists (here, here, and here).
During an AI pause, I expect alignment research would enter another “winter” in which progress stalls, and plausible-sounding-but-false speculations become entrenched as orthodoxy without empirical evidence to falsify them. While some good work would of course get done, it’s not clear that the field would be better off as a whole. And even if a pause would be net positive for alignment research, it would likely be net negative for humanity’s future all things considered, due to the pause’s various unintended consequences. We’ll look at that in detail in the final section of the essay.
Fast takeoff has a really bad feedback loop
I think discontinuous improvements in AI capabilities are very scary, and that AI pause is likely net-negative insofar as it increases the risk of such discontinuities. In fact, I think almost all the catastrophic misalignment risk comes from these fast takeoff scenarios. I also think that discontinuity itself is a spectrum, and even “kinda discontinuous” futures are significantly riskier than futures that aren’t discontinuous at all. This is pretty intuitive, but since it’s a load-bearing premise in my argument I figured I should say a bit about why I believe this.
Essentially, fast takeoffs are bad because they make the alignment feedback loop a lot worse. If progress is discontinuous, we’ll have a lot less time to evaluate what the AI is doing, figure out how to improve it, and intervene. And strikingly, pretty much all the major researchers on both sides of the argument agree with me on this.
Nate Soares of the Machine Intelligence Research Institute has argued that building safe AGI is hard for the same reason that building a successful space probe is hard— it may not be possible to correct failures in the system after it’s been deployed. Eliezer Yudkowsky makes a similar argument:
“This is where practically all of the real lethality [of AGI] comes from, that we have to get things right on the first sufficiently-critical try.” — AGI Ruin: A List of Lethalities
Fast takeoffs are the main reason for thinking we might only have one shot to get it right. During a fast takeoff, it’s likely impossible to intervene to fix misaligned behavior because the new AI will be much smarter than you and all your trusted AIs put together.
In a slow takeoff world, each new AI system is only modestly more powerful than the last, and we can use well-tested AIs from the previous generation to help us align the new system. OpenAI CEO Sam Altman agrees we need more than one shot:
“The only way I know how to solve a problem like [aligning AGI] is iterating our way through it, learning early, and limiting the number of one-shot-to-get-it-right scenarios that we have.” — Interview with Lex Fridman
Slow takeoff is the default (so don’t mess it up with a pause)
There are a lot of reasons for thinking fast takeoff is unlikely by default. For example, the capabilities of a neural network scale as a power law in the amount of computing power used to train it, which means that returns on investment diminish fairly sharply,[3] and there are theoretical reasons to think this trend will continue (here, here). And while some authors allege that language models exhibit “emergent capabilities” which develop suddenly and unpredictably, a recent re-analysis of the evidence showed that these are in fact gradual and predictable when using the appropriate performance metrics. See this essay by Paul Christiano for further discussion.
Alignment optimism: AIs are white boxes
Let’s zoom in on the alignment feedback loop from the last section. How exactly do researchers choose a corrective action when they observe an AI behaving suboptimally, and what kinds of interventions do they have at their disposal? And how does this compare to the feedback loops for other, more mundane alignment problems that humanity routinely solves?
Human & animal alignment is black box
Compared to AI training, the feedback loop for raising children or training pets is extremely bad. Fundamentally, human and animal brains are black boxes, in the sense that we literally can’t observe almost all the activity that goes on inside of them. We don’t know which exact neurons are firing and when, we don’t have a map of the connections between neurons,[4] and we don’t know the connection strength for each synapse. Our tools for non-invasively measuring the brain, like EEG and fMRI, are limited to very coarse-grained correlates of neuronal firings, like electrical activity and blood flow. Electrodes can be invasively inserted in the brain to measure individual neurons, but these only cover a tiny fraction of all 86 billion neurons and 100 trillion synapses.
If we could observe and modify everything that’s going on in a human brain, we’d be able to use optimization algorithms to calculate the precise modifications to the synaptic weights which would cause a desired change in behavior.[5] Since we can’t do this, we are forced to resort to crude and error-prone tools for shaping young humans into kind and productive adults. We provide role models for children to imitate, along with rewards and punishments that are tailored to their innate, evolved drives.
It’s striking how well these black box alignment methods work: most people do assimilate the values of their culture pretty well, and most people are reasonably pro-social. But human alignment is also highly imperfect. Lots of people are selfish and anti-social when they can get away with it, and cultural norms do change over time, for better or worse. Black box alignment is unreliable because there is no guarantee that an intervention intended to change behavior in a certain direction will in fact change behavior in that direction. Children often do the exact opposite of what their parents tell them to do, just to be rebellious.
Status quo AI alignment methods are white box
By contrast, AIs implemented using artificial neural networks (ANN) are white boxes in the sense that we have full read-write access to their internals. They’re just a special type of computer program, and we can analyze and manipulate computer programs however we want at essentially no cost. And this enables a lot of really powerful alignment methods that just aren’t possible for brains.
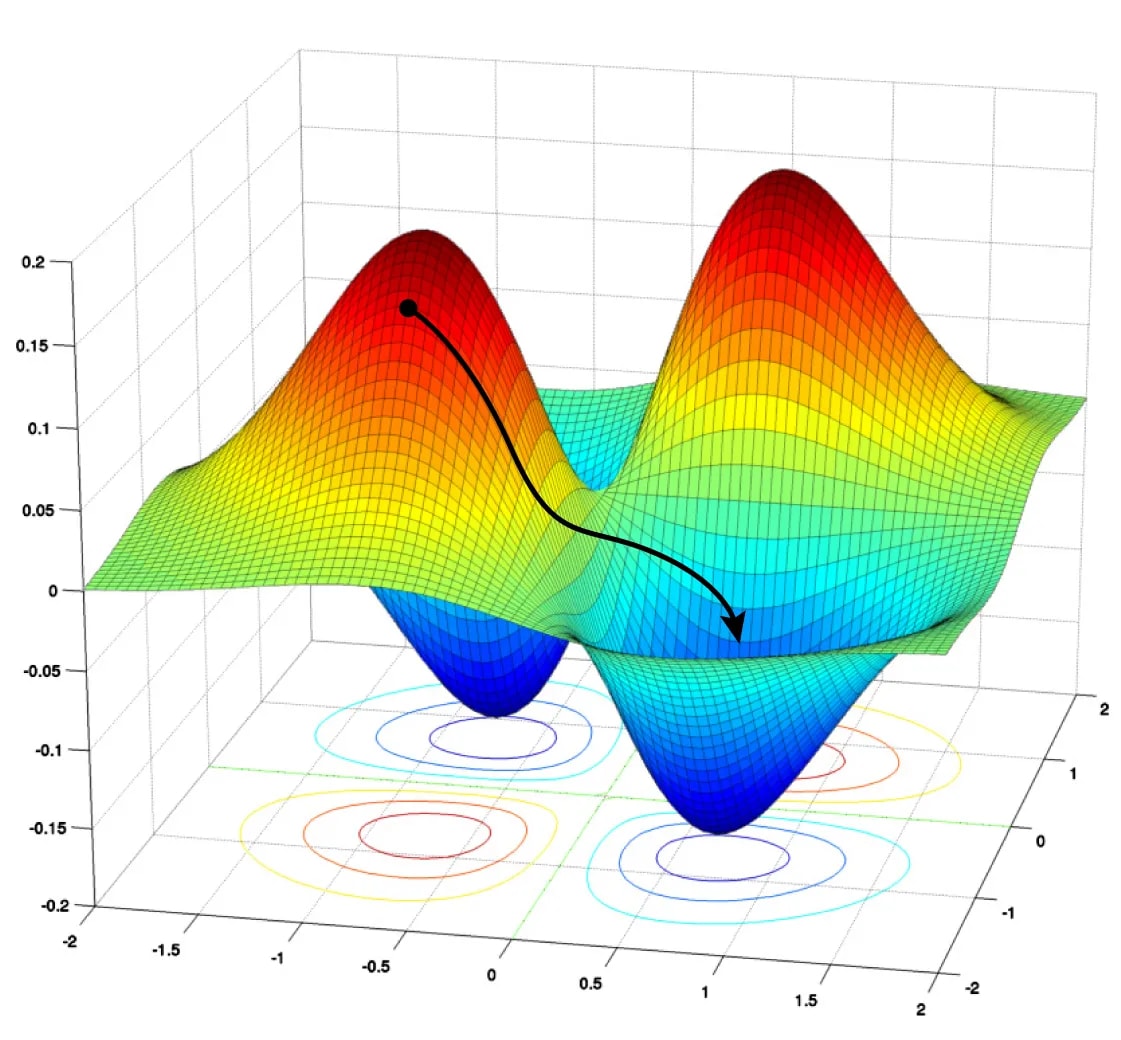
The backpropagation algorithm is an important example. Backprop efficiently computes the optimal direction (called the “gradient”) in which to change the synaptic weights of the ANN in order to improve its performance the most, on any criterion we specify. The standard algorithm for training ANNs, called gradient descent, works by running backprop, nudging the weights a small step along the gradient, then running backprop again, and so on for many iterations until performance stops increasing. The black trajectory in the figure on the right visualizes how the weights move from higher error regions to lower error regions over the course of training. Needless to say, we can’t do anything remotely like gradient descent on a human brain, or the brain of any other animal!
Gradient descent is super powerful because, unlike a black box method, it’s almost impossible to trick. All of the AI’s thoughts are “transparent” to gradient descent and are included in its computation. If the AI is secretly planning to kill you, GD will notice this and almost surely make it less likely to do that in the future. This is because GD has a strong tendency to favor the simplest solution which performs well, and secret murder plots aren’t actively useful for improving human feedback on your actions.
White box alignment in nature
Almost every organism with a brain has an innate reward system. As the organism learns and grows, its reward system directly updates its neural circuitry to reinforce certain behaviors and penalize others. Since the reward system directly updates it in a targeted way using simple learning rules, it can be viewed as a crude form of white box alignment. This biological evidence indicates that white box methods are very strong tools for shaping the inner motivations of intelligent systems. Our reward circuitry reliably imprints a set of motivational invariants into the psychology of every human: we have empathy for friends and acquaintances, we have parental instincts, we want revenge when others harm us, etc. Furthermore, these invariants must be produced by easy-to-trick reward signals that are simple enough to encode in the genome.
This suggests that at least human-level general AI could be aligned using similarly simple reward functions. But we already align cutting edge models with learned reward functions that are much too sophisticated to fit inside the human genome, so we may be one step ahead of our own reward system on this issue.[6] Crucially, I’m not saying humans are “aligned to evolution”— see Evolution provides no evidence for the sharp left turn for a debunking of that analogy. Rather, I’m saying we’re aligned to the values our reward system predictably produces in our environment.
An anthropologist looking at humans 100,000 years ago would not have said humans are aligned to evolution, or to making as many babies as possible. They would have said we have some fairly universal tendencies, like empathy, parenting instinct, and revenge. They might have predicted these values will persist across time and cultural change, because they’re produced by ingrained biological reward systems. And they would have been right.
When it comes to AIs, we are the innate reward system. And it’s not hard to predict what values will be produced by our reward signals: they’re the obvious values, the ones an anthropologist or psychologist would say the AI seems to be displaying during training. For more discussion see Humans provide an untapped wealth of evidence about alignment.
Realistic AI pauses would be counterproductive
When weighing the pros and cons of AI pause advocacy, we must sharply distinguish the ideal pause policy— the one we’d magically impose on the world if we could— from the most realistic pause policy, the one that actually existing governments are most likely to implement if our advocacy ends up bearing fruit.
Realistic pauses are not international
An ideal pause policy would be international— a binding treaty signed by all governments on Earth that have some potential for developing powerful AI. If major players are left out, the “pause” would not really be a pause at all, since AI capabilities would keep advancing. And the list of potential major players is quite long, since the pause itself would create incentives for non-pause governments to actively promote their own AI R&D.
However, it’s highly unlikely that we could achieve international consensus around imposing an AI pause, primarily due to arms race dynamics: each individual country stands to reap enormous economic and military benefits if they refuse to sign the agreement, or sign it while covertly continuing AI research. While alignment pessimists may argue that it is in the self-interest of every country to pause and improve safety, we’re unlikely to persuade every government that alignment is as difficult as pessimists think it is. Such international persuasion is even less plausible if we assume short, 3-10 year timelines. Public sentiment about AI varies widely across countries, and notably, China is among the most optimistic.
The existing international ban on chemical weapons does not lend plausibility to the idea of a global pause. AGI will be, almost by definition, the most useful invention ever created. The military advantage conferred by autonomous weapons will certainly dwarf that of chemical weapons, and they will likely be more powerful even than nukes due to their versatility and precision. The race to AGI will therefore be an arms race in the literal sense, and we should expect it will play out similarly to the last such race: major powers rushed to make a nuclear weapon as fast as possible.
If in spite of all this, we somehow manage to establish a global AI moratorium, I think we should be quite worried that the global government needed to enforce such a ban would greatly increase the risk of permanent tyranny, itself an existential catastrophe. I don’t have time to discuss the issue here, but I recommend reading Matthew Barnett’s “The possibility of an indefinite AI pause” and Quintin Pope’s “AI is centralizing by default; let's not make it worse,” both submissions to this debate. In what follows, I’ll assume that the pause is not international, and that AI capabilities would continue to improve in non-pause countries at a steady but somewhat reduced pace.
Realistic pauses don’t include hardware
Artificial intelligence capabilities are a function of both hardware (fast GPUs and custom AI chips) and software (good training algorithms and ANN architectures). Yet most proposals for AI pause (e.g. the FLI letter and PauseAI[7]) do not include a ban on new hardware research and development, focusing only on the software side. Hardware R&D is politically much harder to pause because hardware has many uses: GPUs are widely used in consumer electronics and in a wide variety of commercial and scientific applications.
But failing to pause hardware R&D creates a serious problem because, even if we pause the software side of AI capabilities, existing models will continue to get more powerful as hardware improves. Language models are much stronger when they’re allowed to “brainstorm” many ideas, compare them, and check their own work— see the Graph of Thoughts paper for a recent example. Better hardware makes these compute-heavy inference techniques cheaper and more effective.
Hardware overhang is likely
If we don’t include hardware R&D in the pause, the price-performance of GPUs will continue to double every 2.5 years, as it did between 2006 and 2021. This means AI systems will get at least 16x faster after ten years and 256x faster after twenty years, simply due to better hardware. If the pause is lifted all at once, these hardware improvements would immediately become available for training more powerful models more cheaply— a hardware overhang. This would cause a rapid and fairly discontinuous increase in AI capabilities, potentially leading to a fast takeoff scenario and all of the risks it entails.
The size of the overhang depends on how fast the pause is lifted. Presumably an ideal pause policy would be lifted gradually over a fairly long period of time. But a phase-out can’t fully solve the problem: legally-available hardware for AI training would still improve faster than it would have “naturally,” in the counterfactual where we didn’t do the pause. And do we really think we’re going to get a carefully crafted phase-out schedule? There are many reasons for thinking the phase-out would be rapid or haphazard (see below).
More generally, AI pause proposals seem very fragile, in the sense that they aren’t robust to mistakes in the implementation or the vagaries of real-world politics. If the pause isn’t implemented perfectly, it seems likely to cause a significant hardware overhang which would increase catastrophic AI risk to a greater extent than the extra alignment research during the pause would reduce risk.
Likely consequences of a realistic pause
If we succeed in lobbying one or more Western countries to impose an AI pause, this would have several predictable negative effects:
- Illegal AI labs develop inside pause countries, remotely using training hardware outsourced to non-pause countries to evade detection. Illegal labs would presumably put much less emphasis on safety than legal ones.
- There is a brain drain of the least safety-conscious AI researchers to labs headquartered in non-pause countries. Because of remote work, they wouldn’t necessarily need to leave the comfort of their Western home.
- Non-pause governments make opportunistic moves to encourage AI investment and R&D, in an attempt to leap ahead of pause countries while they have a chance. Again, these countries would be less safety-conscious than pause countries.
- Safety research becomes subject to government approval to assess its potential capabilities externalities. This slows down progress in safety substantially, just as the FDA slows down medical research.
- Legal labs exploit loopholes in the definition of a “frontier” model. Many projects are allowed on a technicality; e.g. they have fewer parameters than GPT-4, but use them more efficiently. This distorts the research landscape in hard-to-predict ways.
- It becomes harder and harder to enforce the pause as time passes, since training hardware is increasingly cheap and miniaturized.
- Whether, when, and how to lift the pause becomes a highly politicized culture war issue, almost totally divorced from the actual state of safety research. The public does not understand the key arguments on either side.
- Relations between pause and non-pause countries are generally hostile. If domestic support for the pause is strong, there will be a temptation to wage war against non-pause countries before their research advances too far:
- “If intelligence says that a country outside the agreement is building a GPU cluster, be less scared of a shooting conflict between nations than of the moratorium being violated; be willing to destroy a rogue datacenter by airstrike.” — Eliezer Yudkowsky
- There is intense conflict among pause countries about when the pause should be lifted, which may also lead to violent conflict.
- AI progress in non-pause countries sets a deadline after which the pause must end, if it is to have its desired effect.[8] As non-pause countries start to catch up, political pressure mounts to lift the pause as soon as possible. This makes it hard to lift the pause gradually, increasing the risk of dangerous fast takeoff scenarios (see below).
Predicting the future is hard, and at least some aspects of the above picture are likely wrong. That said, I hope you’ll agree that my predictions are plausible, and are grounded in how humans and governments have behaved historically. When I imagine a future where the US and many of its allies impose an AI pause, I feel more afraid and see more ways that things could go horribly wrong than in futures where there is no such pause.
This post is part of AI Pause Debate Week. Please see this sequence for other posts in the debate.
- ^
Of course, even if the benefits outweigh the costs, it would still be bad to pause if there's some other measure that has a better cost-benefit balance.
- ^
In brief, the book mostly assumed we will manually program a set of values into an AGI, and argued that since human values are complex, our value specification will likely be wrong, and will cause a catastrophe when optimized by a superintelligence. But most researchers now recognize that this argument is not applicable to modern ML systems which learn values, along with everything else, from vast amounts of human-generated data.
- ^
Some argue that power law scaling is a mere artifact of our units of measurement for capabilities and computing power, which can’t go negative, and therefore can’t be related by a linear function. But non-negativity doesn’t uniquely identify power laws. Conceivably the error rate could have turned out to decay exponentially, like a radioactive isotope, which would be much faster than power law scaling.
- ^
Called a “connectome.” This was only recently achieved for the fruit fly brain.
- ^
Brain-inspired artificial neural networks already exist, and we have algorithms for optimizing them. They tend to be harder to optimize than normal ANNs due to their non-differentiable components.
- ^
On the other hand, we might be roughly on-par with our own reward system insofar as it does within-lifetime learning to figure out what to reward. This is sort of analogous to the learned reward model in reinforcement learning from human feedback.
- ^
To its credit, the PauseAI proposal does recognize that hardware restrictions may be needed eventually, but does not include it in its main proposal. It also doesn’t talk about restricting hardware research and development, which is the specific thing I’m talking about here.
- ^
This does depend a bit on whether safety research in pause countries is openly shared or not, and on how likely non-pause actors are to use this research in their own models.
For what it's worth, the book does discuss value learning as a way of an AI acquiring values - you can see chapter 13 as being basically about this.
I would describe the core argument of the book as the following (going off of my notes of chapter 8, "Is the default outcome doom?"):
- It is possible to build AI that's much smarter than humans.
- This process could loop in on itself, leading to takeoff that could be slow or fast.
- A superintelligence could gain a decisive strategic advantage and form a singleton.
- Due to the orthogonality thesis, this superintelligence would not necessarily be aligned with human interests.
- Due to instrumental convergence, an unalig
... (read more)Yep I am aware of the value learning section of Chapter 12, which is why I used the "mostly" qualifier. That said he basically imagines something like Stuart Russell's CIRL, rather than anything like LLMs or imitation learning.
If we treat the Orthogonality Thesis as the crux of the book, I also think the book has aged poorly. In fact it should have been obvious when the book was written that the Thesis is basically a motte-and-bailey where you argue for a super weak claim (any combo of intelligence and goals is logically possible), which is itself dubious IMO but easy to defend, and then pretend like you've proven something much stronger, like "intelligence and goals will be empirically uncorrelated in the systems we actually build" or something.
I do not think the orthogonality thesis is a motte-and-bailey. The only evidence I know of that suggests that the goals developed by an ASI trained with something resembling modern methods would by default be picked from a distribution that's remotely favorable to us is the evidence we have from evolution[1], but I really think that ought to be screened off. The goals developed by various animal species (including humans) as a result of evolution are contingent on specific details of various evolutionary pressures and environmental circumstances, which we know with confidence won't apply to any AI trained with something resembling modern methods.
Absent a specific reason to believe that we will be sampling from an extremely tiny section of an enormously broad space, why should we believe we will hit the target?
Anticipating the argument that, since we're doing the training, we can shape the goals of the systems - this would certainly be reason for optimism if we had any idea what goals we would see emerge while training superintelligent systems, and had any way of actively steering those goals to our preferred ends. We don't have either, right now.
- ^
... (read more)Which, mind you, is sti
What does this even mean? I'm pretty skeptical of the realist attitude toward "goals" that seems to be presupposed in this statement. Goals are just somewhat useful fictions for predicting a system's behavior in some domains. But I think it's a leaky abstraction that will lead you astray if you take it too seriously / apply it out of the domain in which it was designed for.
We clearly can steer AI's behavior really well in the training environment. The question is just whether this generalizes. So it becomes a question of deep learning generalization. I think our current evidence from LLMs strongly suggests they'll generalize pretty well to unseen domains. And as I said in the essay I don't think the whole jailbreaking thing is any evidence for pessimism— it's exactly what you'd expect of aligned human mind uploads in the same situation.
I could make this same argument about capabilities, and be demonstratably wrong. The space of neural network values that don't produce coherent grammar is unimaginably, ridiculously vast compared to the "tiny target" of ones that do. But this obviously doesn't mean that chatGPT is impossible.
The reason is that we aren't randomly throwing a dart at possibility space, but using a highly efficient search mechanism to rapidly toss out bad designs until we hit the target. But when these machines are trained, we simultaneously select for capabilities and for alignment (murderbots are not efficient translators). For chatGPT, this leads to an "aligned" machine, at least by some definitions.
Where I think the motte and bailey often occurs is jumping between "aligned enough not to exterminate us", and "aligned with us nearly perfectly in every way" or "unable to be misused by bad actors". The former seems like it might happen naturally over development, whereas the latter two seem nigh impossible.
The argument w.r.t. capabilities is disanalogous.
Yes, the training process is running a search where our steering is (sort of) effective for getting capabilities - though note that with e.g. LLMs we have approximately zero ability to reliably translate known inputs [X] into known capabilities [Y].
We are not doing the same thing to select for alignment, because "alignment" is:
I do think this disagreement is substantially downstream of a disagreement about what "alignment" represents, i.e. I think that you might attempt outer alignment of GPT-4 but not inner alignment, because GPT-4 doesn't have the internal bits which make inner alignment a relevant concern.
There's a giant straw man in this post, and I think it's entirely unreasonable to ignore. It's the assertion, or assumption, that the "pause" would be a temporary measure imposed by some countries, as opposed to a stop-gap solution and regulation imposed to enable stronger international regulation, which Nora says she supports. (I'm primarily frustrated by this because it ignores the other two essays, which Nora had access to a week ago, that spelled this out in detail.)
First, it sounds like you are agreeing with others, including myself, about a pause.
So yes, you're arguing against a straw-man. (Edit to add: Perhaps Rob Bensinger's views are more compatible with the claim that someone is advocating a temporary pause as a good idea - but he has said that ideally he wants a full stop, not a pause at all.)
Second, you're ignoring... (read more)
This essay seems predicated on a few major assumptions that aren't quite spelled out, or any rate not presented as assumptions.
This assumes that making AI behave nice is genuine progress in alignment. The opposing take is that all it's doing is making the AI play a nicer character, but doesn't lead it to internalize its goals, which is what alignment is actually about. And in fact, AI playing rude characters was never the problem to begin with.
You say that alignment i... (read more)
I think this is a misleading frame which makes alignment seem harder than it actually is. What does it mean to "internalize" a goal? It's something like, "you'll keep pursuing the goal in new situations." In other words, goal-internalization is a generalization problem.
We know a fair bit about how neural nets generalize, although we should study it more (I'm working on a paper on the topic atm). We know they favor "simple" functions, which means something like "low frequency" in the Fourier domain. In any case, I don't see any reason to think the neural net prior is malign, or particularly biased toward deceptive, misaligned generalization. If anything the simplicity prior seems like good news for alignment.
I think internalizing X means "pursuing X as a terminal goal", whereas RLHF arguably only makes model pursue X as an instrumental goal (in which case the model would be deceptively aligned). I'm not saying that GPT-4 has a distinction between instrumental and terminal goals, but a future AGI, whether an LLM or not, could have terminal goals that are different from instrumental goals.
You might argue that deceptive alignment is also an obsolete paradigm, but I would again respond that we don't know this, or at any rate, that the essay doesn't make the argument.
I don’t think the terminal vs. instrumental goal dichotomy is very helpful, because it shifts the focus away from behavioral stuff we can actually measure (at least in principle). I also don’t think humans exhibit this distinction particularly strongly. I would prefer to talk about generalization, which is much more empirically testable and has a practical meaning.
What if it just is the case that AI will be dangerous for reasons that current systems don't exhibit, and hence we don't have empirical data on? If that's the case, then limiting our concerns to only concepts that can be empirically tested seems like it means setting ourselves up for failure.
I'm not sure what one is supposed to do with a claim that can't be empirically tested - do we just believe it/act as if it's true forever? Wouldn't this simply mean an unlimited pause in AI development (and why does this only apply to AI)?
You need to have some motivation for thinking that a fundamentally new kind of danger will emerge in future systems, in such a way that we won't be able to handle it as it arises. Otherwise anyone can come up with any nonsense they like.
If you're talking about e.g. Evan Hubinger's arguments for deceptive alignment, I think those arguments are very bad, in light of 1) the white box argument I give in this post, 2) the incoherence of Evan's notion of "mechanistic optimization," and 3) his reliance on "counting arguments" where you're supposed to assume that the "inner goals" of the AI are sampled "uniformly at random" from some uninformative prior over goals (I don't think the LLM / deep learning prior is uninformative in this sense at all).
That was what everyone ins AI safety was discussing for a decade or more, until around 2018. You seem to ignore these arguments about why AI will be dangerous, as well as all of the arguments that alignment will be hard. Are you familiar with all of that work?
I feel like I detect a missing mood from you where you're skeptical of pausing (for plausible-to-me reasons), but you're not conflicted about it like I am and you don't e.g. look for ways to buy time or ways for regulation to help without the downsides of a pause. (Sorry if this sounds adversarial.) Relatedly, this post is one-sided and so feels soldier-mindset-y. Likely this is just due to the focus on debating AI pause. But I would feel reassured if you said you're sympathetic to: labs not publishing capabilities research, labs not publishing model weights, dangerous-capability-model-eval-based regulation, US and allies slowing other states and denying them compute, and/or other ways to slow AI or for regulation to help. If you're unsympathetic to these, I would doubt that the overhang nuances you discuss are your true rejection (but I'd be interested in hearing more about your take on slowing and regulation outside of "pause").
Edit: man, I wrote this after writing four object-level comments but this got voted to the top. Please note that I'm mostly engaging on the object level and I think object-level discussion is generally more productive—and I think Nora's post makes several good points.
I think people have started to stretch the "missing mood" concept a bit too far for my taste.
What actual mood is missing here?
If you think that the default path of AI development leads towards eventual x-risk safety, but that rash actions like an AI pause could plausibly push us off that path and into catastrophe, then your default moods would be "fervent desire to dissuade people from doing the potentially disastrous thing", and "happy that the disastrous thing probably won't happen". I think this matches with the mood the OP has provided.
I worry that these sort of meta-critiques can inadvertently be used to pressure people into one side of object-level disagreements. This isn't a dig at you in particular, and I acknowledge that you made object level points as well, which really should be higher than this comment.
Also feeling more conflicted in general—there are several real considerations in favor of pausing and Nora doesn't grapple with them. (But this is a debate and maybe Nora is deliberately one-sidedly arguing for a particular position.)
Maybe "missing mood" isn't exactly the right concept.
So the point of the "missing mood" concept was that it was an indicator for motivated reasoning. If someone reports to you that "lithuanians are genetically bad at chess" with a mood of unrestrained glee, you can rightly get suspicious of their methods. If they weren't already prejudiced against lithuanians, they would find the result about chess ability sad and unfortunate.
I see no similar indicators here. From nora's perspective, the AI pause and similar proposals are a bomb that will hurl us much closer to catastrophe. Why, (from their perspective) would there be a requirement to show sympathy for the bomb-throwers, or propose a modified bomb design?
Now of course, as a human being nora will have pre-existing biases towards one side or the other, and you can pick apart the piece if you want to find evidence of that (like using the phrase "heavy handed government regulation"). But having some bias towards one side doesn't mean your arguments are wrong. The meta can have some uses if it's truly blatant, but it's the object level that actually matters.
If you desperately wish we had more time to work on alignment, but also think a pause won’t make that happen or would have larger countervailing costs, then that would lead to an attitude like: “If only we had more time! But alas, a pause would only make things worse. Let’s talk about other ideas…” For my part, I definitely say things like that (see here).
However, Nora has sections claiming “alignment is doing pretty well” and “alignment optimism”, so I think it’s self-consistent for her to not express that kind of mood.
Where we agree:
"dangerous-capability-model-eval-based regulation" sounds good to me. I'm also in favor of Robin Hanson's foom liability proposal. These seem like very targeted measures that would plausibly reduce the tail risk of existential catastrophe, and don't have many negative side effects. I'm also not opposed to the US trying to slow down other states, although it'd depend on the specifics of the proposal.
Where we (partially) disagree:
I think there's a plausible case to be made that publishing model weights reduces foom risk by making AI capabilities more broadly distributed, and also enhances security-by-transparency. Of course there are concerns about misuse— I do think that's a real thing to be worried about— but I also think it's generally exaggerated. I also relatively strongly favor open source on purely normative grounds. So my inclination is to be in favor of it but with reservations. Same goes for labs publishing capabilities research.
I feel like you’re trying to round these three things into a “yay versus boo” axis, and then come down on the side of “boo”. I think we can try to do better than that.
One can make certain general claims about learning algorithms that are true and for which evolution provides as good an example as any. One can also make other claims that are true for evolution and false for other learning algorithms. and then we can argue about which category future AGI will be in. I think we should be open to that kind of dialog, and it involves talking about evolution.
Likewise, I think “inner misalignment versus outer misalignment” is a helpful and valid way to classify certain failure modes of certain AI algorithms.
For the third one, there’s an argument like:
“Maybe the AI will really want something-or-other to happen in the future, and try to make it happen, including by long-term planning—y'know, the way some humans really want to break out of prison, or the way Elon Musk really ... (read more)
I certainly give relatively little weight to most conceptual AI research. That said, I respect that it's valuable for you and am open to trying to narrow the gap between our views here - I'm just not sure how!
To be more concrete, I'd value 1 year of current progress over 10 years of pre-2018 research (to pick a date relatively arbitrarily). I don't intend this as an attack on the earlier alignment community, I just think we're making empirical progress in a way that was pretty much impossible before we had good models available to study and I place a lot more value on this.
I have a vague impression—I forget from where and it may well be false—that Nora has read some of my AI alignment research, and that she thinks of it as not entirely pointless. If so, then when I say “pre-2020 MIRI (esp. Abram & Eliezer) deserve some share of the credit for my thinking”, then that’s meaningful, because there is in fact some nonzero credit to be given. Conversely, if you (or anyone) don’t know anything about my AI alignment research, or think it’s dumb, then you should ignore that part of my comment, it’s not offering any evidence, it would just be saying that useless research can sometimes lead to further useless research, which is obvious! :)
I probably think less of current “empirical” research than you, because I don’t think AGI will look and act and be built just like today’s LLMs but better / larger. I expect highly-alignment-relevant differences between here and there, including (among other things) reinforcement learning being involved in a much more central way than it is today (i.e. RLHF fine-tuning). This is a big topic where I think reasonable people disagree and maybe this comment section isn’t a great place to hash it out. ¯\_(ツ)_/¯
My own research d... (read more)
One of the three major threads in this post (I think) is noticing pause downsides: in reality, an "AI pause" would have various predictable downsides.
Part of this is your central overhang concerns, which I discuss in another comment. The rest is:
... (read more)Random aside, but I think this paragraph is unjustified in both its core argument (that the referenced theory-first efforts propagated actively misleading ways of thinking about alignment) and none of the citations provide the claimed support.
The first post (re: evolutionary analogy as evidence for a sharp left turn) sees substantial pushback in the comments, and that pushback seems more correct to me than not, and in any case seems to misunderstand the position it's arguing against.
The second post presents an interesting case for a set of claims that are different from "there is no distinction between inner and outer alignment"; I do not consider it to be a full refutation of that conceptu... (read more)
I agree that alignment research would suffer during a pause, but I've been wondering recently how much of an issue that is. The key point is that capabilities research would also be paused, so it's not like AI capabilities would be racing ahead of our knowledge on how to control ever more powerful systems. You'd simply be delaying both capabilities and alignment progress.
You might then ask - what's the point of a pause if alignment research stops? Isn't the whole point of a pause to figure out alignment?
I'm not sure that's the whole point of a pause. A pause can also give us time to figure out optimal governance structures whether it be standards, regulations etc. These structures can be very important in reducing x-risk. Even if the U.S. is the only country to pause that still gives us more time, because the U.S. is currently in the lead.
I realise you make other points against a pause (which I think might be valid), but I would welcome thoughts on the 'having more time for governance' point specifically.
Thanks very much for writing this very interesting piece!
The "AI safety winter" section argues that pre-2020, AI alignment researchers made little progress because they had no AI to work on aligning. But now that we have GPT-4 etc., I feel like we have a capabilities overhang, and it seems like there is plenty of AI alignment researchers to work on for the next 6 months or so? Then their work could be 'tested' by allowing some more algorithmic progress.
This post has definitely made me more pessimistic on a pause, particularly:
• If we pause, it's not clear on how much extra time we get at the end and how much this costs us in terms of crunch time.
• The implementation details are tricky and actors are incentivised to try to work around the limitations.
On the other hand, I disagree with the following:
• That it is clear that alignment is doing well. There are different possible difficulty levels that alignment could have. I agree that we are in an easier world, where ChatGPT has already achieved a greater amount of outer alignment than we would have expected from some of the old arguments about the impossibility of listing all of our implicit conditions. On the other hand, it's not at all clear that we're anywhere near close to scalable alignment techniques, so there's a pretty decent argument that we're far behind where we need to be.
• Labelling AI's as white box merely because we can see all of the weights. You've got a point. I can see where you're coming from. However, I'm worried that your framing is confusing and will cause people to talk past each other.
• That if there was a pause, alignment research would magically revert bac... (read more)
AI safety currently seems to heavily lean towards empirical and this emphasis only seems to be growing, so I’m rather skeptical that a bit more theoretical work on the margin will be some kind of catastrophe. I’d actually expect it to be a net positive.
One of the three major threads in this post (I think) is feedback loops & takeoff: for safety, causing capabilities to increase more gradually and have more time with more capable systems is important, relative to total time until powerful systems appear. By default, capabilities would increase gradually. A pause would create an "overhang" and would not be sustained forever; when the pause ends, the overhang entails that capabilities increase rapidly.
I kinda agree. I seem to think rapid increase in training compute is less likely, would be smaller, and would be less bad than you do. Some of the larger cruxes:
- Magnitude of overhang: it seems the size of the largest training run largely isn't about the cost of compute. Why hasn't someone done a billion-dollar LLM training run, why did we only recently break $10M? I don't know but I'd guess you can't effectively (i.e. you get sharply diminishing returns for doing more than a couple orders of magnitude more than models that have been around for a while), or it's hard to get a big cluster to parallelize and so the training run would take years, or something. Relevant meme:

- Magnitude of overhang: endogeneity. AI progress impr
... (read more)One of the three major threads in this post (I think) is alignment optimism: AI safety probably isn't super hard.
A possible implication is that a pause is unnecessary. But the difficulty of alignment doesn't seem to imply much about whether slowing is good or bad, or about its priority relative to other goals.
(I disagree that gradient descent entails "we are the innate reward system" and thus safe, or that "full read-write access to [AI systems'] internals" gives safety in the absence of great interpretability. I think likely failure modes include AI playing the training game, influence-seeking behavior dominating, misalignment during capabilities generalization, and catastrophic Goodharting, and that AGI Ruin: A List of Lethalities is largely right. But I think in this debate we should focus on determining optimal behavior as a function of the difficulty of alignment, rather than having intractable arguments about the difficulty of alignment.)
The second link just takes me to Alex Turner's shortform page on LW, where ctrl+f-ing "assistance" doesn't get me any results. I do find this comment when searching for "CIRL", which criticizes the CIRL/assistance games research program, but does not claim that it is irrelevant to modern deep learning. For what it's worth, I think it's plausible that Alex Turner thinks that assistance games is mostly irrelevant to modern deep learning (and plausible that he doesn't think that) - I merely object that the link provided doesn't provide good evidence of that claim.
The first link is to Rohin Shah's reviews of Human Compatible and some assistance games / CIRL research papers. ctrl+f-ing "deep" gets me two irrelevant results, plus one description of a paper "which is inspired by [the CIRL] paper and does a similar thing with deep RL". It would be hard to write such a paper if CIRL (aka assistance games) was mostly irrelevant to modern deep learning. The closest thing I ca... (read more)
Yeah, I don't think it's accurate to say that I see assistance games as mostly irrelevant to modern deep learning, and I especially don't think that it makes sense to cite my review of Human Compatible to support that claim.
The one quote that Daniel mentions about shifting the entire way we do AI is a paraphrase of something Stuart says, and is responding to the paradigm of writing down fixed, programmatic reward functions. And in fact, we have now changed that dramatically through the use of RLHF, for which a lot of early work was done at CHAI, so I think this reflects positively on Stuart.
I'll also note that in addition to the "Learning to Interactively Learn and Assist" paper that does CIRL with deep RL which Daniel cited above, I also wrote a paper with several CHAI colleagues that applied deep RL to solve assistance games.
My position is that you can roughly decompose the overall problem into two subproblems: (1) in theory, what should an AI system do? (2) Given a desire for what the AI system should do, how do we make it do that?
The formalization of assistance games is more about (1), saying that AI systems should behave more like assistants than like autonomous agents (basica... (read more)
Suppose you walk down a street, and unbeknownst to you, you’re walking by a dumpster that has a suitcase full of millions of dollars. There’s a sense in which you “can”, “at essentially no cost”, walk over and take the money. But you don’t know that you should, so you don’t. All the value is in the knowledge.
A trained model is like a computer program with a billion unlabeled parameters and no documentation. Being able to view the code is helpful but doesn’t make it “white box”. Saying it’s “essentially no cost” to “analyze” a trained model is just crazy. I’m pretty sure you have met people doing mechanistic interpretability, right? It’s not trivial. They spend months on their projects. The thing you said is just so crazy that I have to assume I’m misunderstanding you. Can you clarify?
Nora is Head of Interpretability at EleutherAI :)
If you want to say "it's a black box but the box has a "gradient" output channel in addition to the "next-token-probability-distribution" output channel", then I have no objection.
If you want to say "...and those two output channels are sufficient for safe & beneficial AGI", then you can say that too, although I happen to disagree.
If you want to say "we also have interpretability techniques on top of those, and they work well enough to ensure alignment for both current and future AIs", then I'm open-minded and interested in details.
If you want to say "we can't understand how a trained model does what it does in any detail, but if we had to drill into a skull and only measure a few neurons at a time etc. then things sure would be even worse!!", then yeah duh.
But your OP said "They’re just a special type of computer program, and we can analyze and manipulate computer programs however we want at essentially no cost", and used the term "white box". That's the part that strikes me as crazy. To be charitable, I don't think those words are communicating the message that you had intended to communicate.
For example, find a random software engineer on the street, and ask them: "if I give... (read more)
I don’t think “mouldability” is a synonym of “white-boxiness”. In fact, I think they’re hardly related at all:
You wrote “They’re just a special type of computer program, and we can analyze and manipulate computer programs however we want at essentially no cost.” I feel like I keep pressing you on this, and you keep motte-and-bailey'ing into some other claim that does not align with a common-sense reading of what you originally wrote:
- “Well, the cost of analysis could theoretically be even higher—like, if you had to drill into skulls…” OK sure but that’s not the same as “essentially no cost”.
- “Well, the cost of analysis may be astronomically high, but there’s a theorem proving that it’s not theoretically impossible…” OK sur
... (read more)Simple and genuine question from a non-AI guy
I understand the arguments towards encouraging gradual development vs. fast takeoff, but I don't understand this argument I've heard multiple times (not just on this post) that "we need capabilities to increase so that we can stay up to date with alignment research".
First I thought there's still a lot of work we could do with current capabilities - technical alignment is surely limited by time, money and manpower not just by computing power. I'm also guessing less powerful AI could be made during a "pause" specifically for alignment research
Second in a theoretical situation where capabilities research globally stopped overnight, isn't this just free-extra-time for the human race where we aren't moving towards doom? That feels pretty valuable and high EV in and of itself.
It seems to me the argument would have to be that the advantage to the safety work of improving capabilities would outstrip the increasing risk of dangerous GAI, which I find hard to get my head around, but I might be missing something important.
Thanks.
Thanks Aaron that's a good article appreciate it. It still wasn't clear to me they were making an argument that increasing capabilities could be net positive, more that safety people should be working with whatever is the current most powerful model
"But we also cannot let excessive caution make it so that the most safety-conscious research efforts only ever engage with systems that are far behind the frontier."
This makes sense to me, the best safety researchers should have full access to the current most advanced models, preferably in my eyes before they have been (fully) trained.
But then I don't understand their next sentance "Navigating these tradeoffs responsibly is a balancing act, and these concerns are central to how we make strategic decisions as an organization."
I'm clearly missing something, what's the tradeoff? Is working on safety with the most advanced current model while generally slowing everything down not the best approach? This doesn't seem like a tradeoff to me
How is there any net safety advantage in increasing AI capacity?
You could have stopped here. This is our crux.
Eliezer and Nate also both expect discontinuous Takeoff by default. I feel like it's a bit disingenuous to argue that the thinking of Eliezer et al has proven obsolete and misguided, but then also quote them as apparent authority figures in this one case where their arguments align with your essay. It has to be one or the other!
Unfortunately, this post got published under the wrong username. I'm the Nora who wrote this post. I hope it can be fixed soon.
Upvoted. I don't agree with all of these takes but they seem valuable and underappreciated.
I don't think the comparison with human alignment being successful is fair.
If you mean that most people don't go on to be antisocial etc.. which is comparable to non-X AI risk, the yes perhaps simple techniques like a 'good upbringing' are working on humans. A lot of it however is just baked in by evolution regardless. If you mean that most humans don't go on to become X-risks, then that mostly has to do with lack of capability, rather than them being aligned. There are very few people I would trust with 1000x human abilities, assuming everyone else remains a 1x human.
I feel in a number of areas this post relies on the concept of AI being constructed/securitised in a number of ways that seem contradictory to me. (By constructed, I am referring to the way the technology is understood, percieved and anticipated, what narratives it fits into and how we understand it as a social object. By securitised, I mean brought into a limited policy discourse centred around national security that justifies the use of extraordinary measures (eg mass surveillance or conflict) to combat, concerned narrowly with combatting the existential... (read more)
Addressing some of your objections:
Hardware development restriction would be nice, but it’s not necessary for a successful moratorium (at least for the next few years) given already proposed compute governance schemes. There are only a handful of large hardware manufacturers and data centre vendors who would need to be regulated into building in detection and remote kill switches into their products to ensure training runs over a certain threshold of compute aren’t completed. And training FLOP limits could be regularl... (read more)
Thanks for this post Nora :) It's well-written, well-argued, and has certainly provoked some lively discussion. (FWIW I welcome good posts like this that push back against certain parts of the 'EA Orthodoxy')[1]
My only specific comment would be similar to Daniel's, I'm not sure the references to the CIRL paradigm being irrelevant are fully backed-up. Not saying that's wrong, just that I didn't find the links convincing (though I don't work on training/aligning/interpreting LLMs as my day job)
My actual question is that I want there to be more things like th... (read more)
Enjoyed the post, thanks! But it starts with an invalid deduction:
(I added the emphasis)
Instead, it seems more reasonable to simply advocate for such action exactly if, in expectation, the benefits seem to [even just about] outweigh the costs. Of course, we... (read more)
Nora, what is your p(doom|AGI)?
I think this is a crux. GPT-4 is only safe because it is weak. It is so far from being 100% aligned -- see e.g this boast from OpenAI that is very far from being reassuring ("29% more often"), or all the many many jailbreaks -- which is what will be needed for us to survive in the limit of superintelligence!
You go on to talk about robustness (to misuse) and how this (jailbreaks) is is a separate issue, but whilst the distinction may be important from the perspective of ML research (or A... (read more)
I think this post provides some pretty useful arguments about the downsides of pausing AI development. I feel noticeably more pessimistic about a pause going well having read this.
However, I don't agree with some of the arguments about alignment optimism and think they're a fair bit weaker
Sure, we can use RLHF/related techniques to steer AI behavior. Further,
Sure, unlike in most cases in biology, ANN updates do act on the whole model without noise etc... (read more)
Good post.
Small things:
You don't actually discuss concentrating power, I think. (You just say fast takeoff is bad because it makes alignment harder, which is the same as your 1.)
... (read more)Superintelligence describes exploiting hard-coded goals as one failure mode which we would probably now call specification gaming. But the book is quite comprehensive, other failure modes are described and I think the book is still relevant.
For example, the book describes what we would ... (read more)
One of my favorite passages is your remark on AI in some ways being rather more white-boxy, while instead humans are rather black boxy and difficult to align. Some often ignored truth in that (even if, in the end, what really matters, arguably is that we're so familiar with human behavior, that overall, the black boxy-ness of our inner workings may matter less).