This post is a part of Rethink Priorities’ Worldview Investigations Team’s CURVE Sequence: “Causes and Uncertainty: Rethinking Value in Expectation.” The aim of this sequence is twofold: first, to consider alternatives to expected value maximization for cause prioritization; second, to evaluate the claim that a commitment to expected value maximization robustly supports the conclusion that we ought to prioritize existential risk mitigation over all else. This post presents a software tool we're developing to better understand risk and effectiveness.
Executive Summary
The cross-cause cost-effectiveness model (CCM) is a software tool under development by Rethink Priorities to produce cost-effectiveness evaluations in different cause areas.
Video introduction: the CCM in the context of the curve sequence, an overview of CCM functionality
- The CCM enables evaluations of interventions in global health and development, animal welfare, and existential risk mitigation.
- The CCM also includes functionality for evaluating research projects aimed at improving existing interventions or discovering more effective alternatives.
The CCM follows a Monte Carlo approach to assessing probabilities.
- The CCM accepts user-supplied distributions as parameter values.
- Our primary goal with the CCM is to clarify how parameter choices translate into uncertainty about possible results.
The limitations of the CCM make it an inadequate tool for definitive comparisons.
- The model is optimized for certain easily quantifiable effective projects and cannot assess many relevant causes.
- Probability distributions are a questionable way of representing deep uncertainty.
- The model may not adequately handle possible interdependence between parameters.
Building and using the CCM has confirmed some of our expectations. It has also surprised us in other ways.
- Given parameter choices that are plausible to us, existential risk mitigation projects dominate others in expected value in the long term, but the results are too high variance to approximate through Monte Carlo simulations without drawing billions of samples.
- The expected value of existential risk mitigation in the long run is mostly determined by the tail-end possible values for a handful of deeply uncertain parameters.
- The most promising animal welfare interventions have a much higher expected value than the leading global health and development interventions with a somewhat higher level of uncertainty.
- Even with relatively straightforward short-term interventions and research projects, much of the expected value of projects results from the unlikely combination of tail-end parameter values.
We plan to host an online walkthrough and Q&A of the model with the Rethink Priorities Worldview Investigations Team on Giving Tuesday, November 28, 2023, at 9 am PT / noon ET / 5 pm BT / 6 pm CET. If you would like to attend this event, please sign up here.
 Overview
Overview
Rethink Priorities’ cross-cause cost-effectiveness model (CCM) is a software tool we are developing for evaluating the relative effectiveness of projects across three general domains: global health and development, animal welfare, and the mitigation of existential risks. You can play with our initial version at ccm.rethinkpriorities.org and provide us feedback in this post or via this form.
The model produces effectiveness estimates, understood in terms of the effect on the sum of welfare across individuals, for interventions and research projects within these domains. Results are generated by computations on the values of user-supplied parameters. Because of the many controversies and uncertainties around these parameters, it follows a Monte Carlo approach to accommodating our uncertainty: users don’t supply precise values but instead specify distributions of possible values; then, each run of the model generates a large number of samples from these parameter distributions to use as inputs to compute many separate possible results. The aim is for the conclusions to reflect what we should believe about the spread of possible results given our uncertainty about the parameters.
Purpose
The CCM calculates distributions of the relative effectiveness of different charitable interventions and research projects so that they can be compared. Because these distributions depend on so many uncertain parameter values, it is not intended to establish definitive conclusions about the relative effectiveness of different projects. It is difficult to incorporate the vast number of relevant considerations and the full breadth of our uncertainties within a single model.
Instead, the outputs of the CCM provide evidence about relative cost-effectiveness. Users must combine that evidence with both an understanding of the model’s limitations and other sources of evidence to come to their own opinions. The CCM can influence what we believe even if it shouldn’t decide it.
In addition to helping us to understand the implications of parameter values, the CCM is also intended to be used as a tool to better grasp the dynamics of uncertainty. It can be enlightening to see how much very remote possibilities dominate expected value calculations and how small changes to some parameters can make a big difference to the results. The best way to use the model is to interact with it: to see how various parameter distributions affect outputs.
Key Features
We’re not the first to generate cost-effectiveness estimates for diverse projects or the first to make a model to do so. We see the value of the present model in terms of the following features:
We model uncertainty with simulations
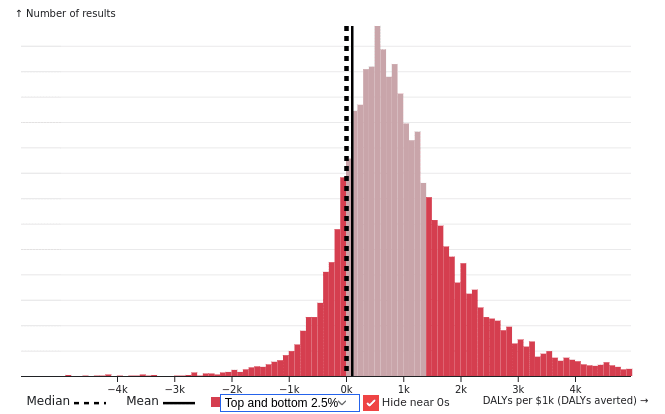
As we’ve said, we’re uncertain about many of the main parameters that go into producing results in the model. To reflect that uncertainty, we run our model with different values for those parameters.
In the current version of the model, we use 150,000 independent samples from each of the parameter distributions to generate results. These samples can be thought of as inputs to independent runs. The runs generate an array of outcomes that reflect our proper subjective probability distribution over results. Given adequate reflection of our uncertainties about the inputs to the model, these results should cover the range of possibilities we should rationally expect.
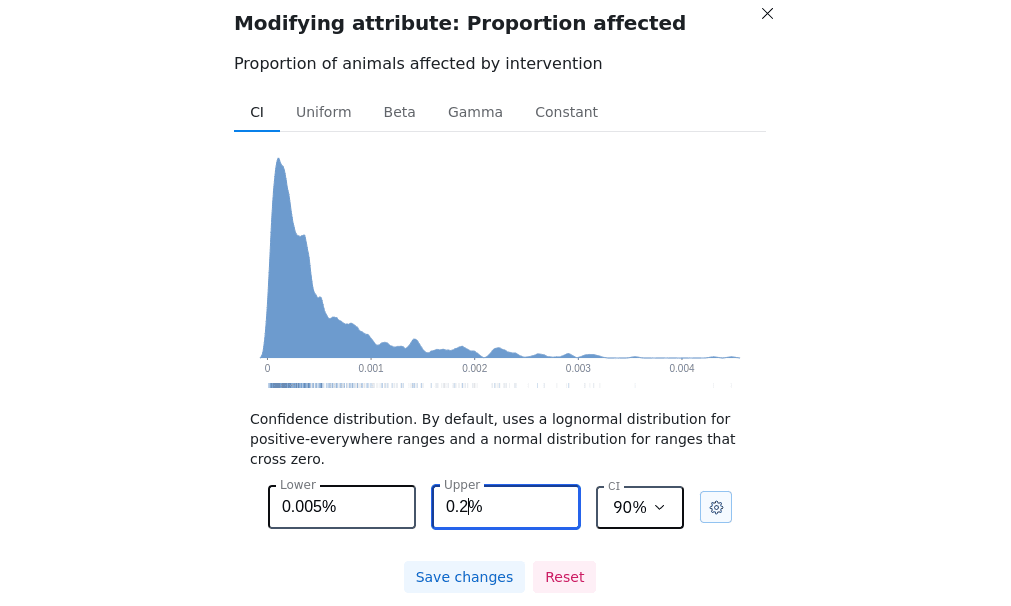
We incorporate user-specified parameter distributions
To reflect uncertainty about parameters, the model generates multiple simulations using different combinations of values. The values for the parameters in each simulation are sampled from distributions over possible numbers. While we supply some default distributions based on what we believe to be reasonable, we also empower users to shape distributions to represent their own uncertainties. We include several types of distributions for users to select among; we also let them set the bounds and a confidence interval for their distribution of choice.
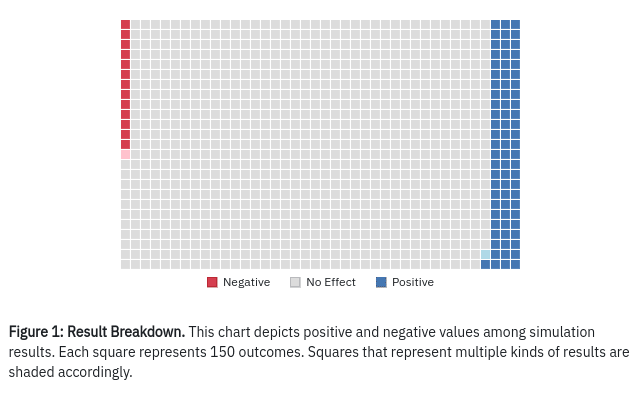
Our results capture outcome ineffectiveness
We are uncertain about the values of parameters that figure into our calculations of the expected value of our projects. We are also uncertain about how worldly events affect their outcomes. Campaigns can fail. Mitigation efforts can backfire. Research projects can be ignored. One might attempt to capture the effect of such random events by applying a discount to the result: if there is a 30% chance that a project will fail, we may simply reduce each sampled value by 30%. Instead, we attempt to capture this latter sort of uncertainty by randomly determining the outcomes of certain critical events in each simulation. If the critical events go well, the simulation receives the full calculated value of the intervention. If the critical events go otherwise, that simulation records no value or negative value.
Many projects stand to make a large positive difference to the world but only are effective under the right conditions. If there is some chance that our project will fail, we can expect the model’s output ranges to include many samples in which the intervention makes no difference.
Including the outcomes of worldly events helps us see how much of a risk there is that our efforts are wasted. This is important for accurately measuring risk under the alternative decision procedures explored elsewhere in this sequence.

We enable users to specify the probability of extinction for different future eras
We put more work into our calculations around the value provided by existential risk mitigation compared with other cause areas. Effectiveness evaluations in this cause area are both sensitive to particularly complex considerations and relatively less well explored.
One critical feature to assessing the effect of existential risk mitigation is the number of our descendants. This depends in part on how long we last before extinction, which in turn depends on the future threats to our species. We make it possible for users to capture their own views about risk by specifying custom risk predictions that include yearly risk assessments for the relevant periods over the coming millennia.
Structure
The tool contains two main modules.
First, the model contains a module for assessing the effectiveness of interventions directly aimed at making a difference. This tool utilizes sub-models for evaluating and comparing interventions addressing global health and development, animal welfare, and existential risk mitigation.
Second, the model contains a module for comparing the effectiveness of research projects intended to improve the effectiveness of money spent on direct interventions. This tool combines parameters concerning the probability of finding and implementing an improvement with the costs incurred by the search.
Intervention module
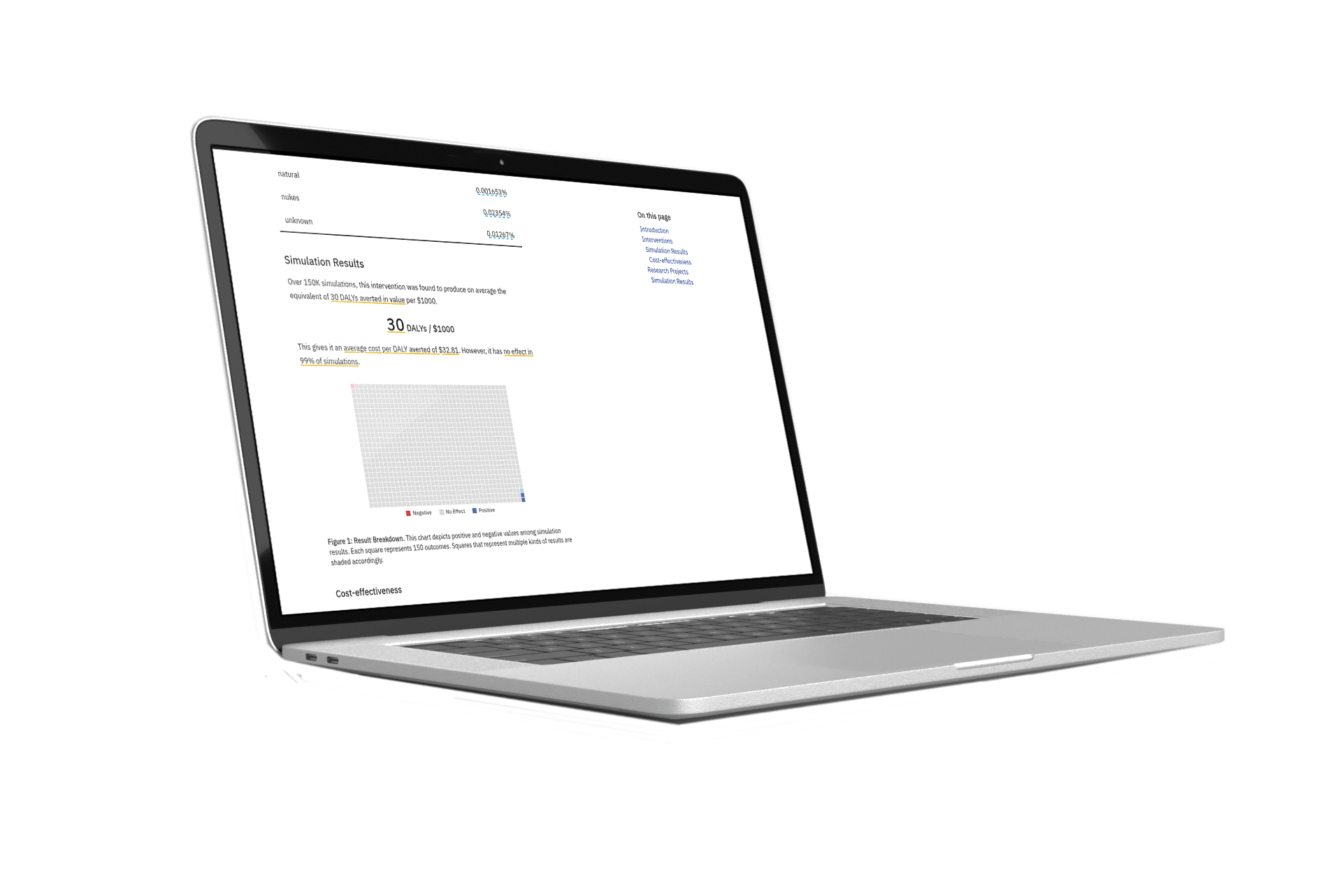
The intervention assessment module provides evaluations of the effectiveness of interventions within three categories: global health and development, animal welfare, and existential risk mitigation. The effectiveness of interventions within each category is reported in DALYs-averted equivalent units per $1000 spent on the current margin.
Given the different requirements of interventions with distinct aims, the CCM relies on several sub-models to calculate intervention effectiveness of different kinds.
Global Health and Development
We include several benchmark estimates of cost-effectiveness for global health and development charities to assess the relative effectiveness of animal welfare and existential risk projects. We draw these estimates from other sources, such as GiveWell, that we expect to be as reliable as anything we could produce ourselves. However, these estimates don’t incorporate uncertainty. To try to account for this and to express our own uncertainties about these estimates, we use distributions centered on the estimates.
Animal Welfare
Our animal welfare model assesses the effects of different interventions on welfare among farmed animal populations. The parameters that go into these calculations include the size of the farmed population, the proportion that will be affected, the degree of improvement in welfare, and the costs of the project (among others.)
Since the common unit of value used to compare interventions is assessed in disability-adjusted human life years, we discount the well-being of non-human animals based on their probability of sentience and capacities for welfare. Our default values are based on the findings of the Moral Weight Project, though they can be changed to reflect a wide range of views about the moral considerations that bear on human/animal and animal/animal tradeoffs.
Existential Risk Mitigation
Our existential risk model estimates the effect that risk mitigation has on both preventing near-term catastrophes and extinction. In both cases, we calculate effectiveness in terms of the difference the intervention makes in years of human life lived.
We assume that existential risk mitigation work may lower (or accidentally raise) the chance of risk of catastrophic or existential events over a few decades, but has no perpetual impact on the level of risk. The primary value of an intervention is in helping us safely make it through this period. In many of the samples, the result of our model’s randomization means that we do not suffer an event in the coming decades regardless of the intervention. If that happens, or if we suffer an event despite the intervention, this means that the intervention provides no benefit for its cost. In some others, the intervention allows our species to survive for thousands of years, gradually colonizing the galaxy and beyond. In yet others, our efforts backfire and we bring about an extinction event that would not otherwise have occurred.
The significance of existential risk depends on future population sizes. In response to the extreme uncertainty of the future, we default to a cutoff point in a thousand years, where the population is limited by the Earth’s capacity. However, we make it possible to expand this time frame to any degree. We assume that, given enough time, humans will eventually expand beyond our solar system, and for simplicity accept a constant and equal rate of colonization in each direction. The future population of our successors will depend on the density of inhabitable systems, the population per system, and the speed at which we colonize them. Given the high growth rate of a volume with constant diameter expansion, we find that the speed of expansion and the time until extinction are the most important factors for deciding effectiveness. Interventions can have an extraordinarily high mean effectiveness even if, the vast majority of the time, they do nothing.
Research projects module
The research projects sub-module provides evaluations of research projects aimed at improving the quality of global health and development and animal welfare intervention work. These research projects make a difference in the cost-effectiveness of money spent on a project if successful. However, they are often speculative and fail to find an improvement; or, they find an improvement that is not adopted. The sub-module lets users specify the effect of moving money from an intervention with a certain effectiveness to another hypothetical intervention of higher effectiveness, then, it creates an assessment of the value of the research due to promoting that change.
If a research project succeeds in finding an improvement in effectiveness, the value produced depends on how much money is influenced as a result. Research isn’t free, and so we count the costs of research in terms of the counterfactual use of that money on interventions themselves.
Limitations
The intervention module has several significant limitations that reduce its usefulness for generating cross-cause comparisons of cost-effectiveness. All results need to be interpreted carefully and used judiciously.
It is geared towards specific kinds of interventions
The sub-models for existential risk mitigation and animal welfare abstract some of the particularities of the interventions within their domain to allow them to represent different interventions following a similar logic. They are far from completely general. The animal welfare model is aimed at interventions reducing the suffering of animals. Interventions aimed at promoting vegetarianism, which have an indirect effect on animal suffering, are not represented. The existential risk mitigation model is aimed at interventions lowering the near-term risk of human extinction. Many other long-termist projects, such as projects aimed at improving institutional decision-making or moral circle expansion, are not represented.
Other interventions would require different parameter choices and different logic to process them. The sorts of interventions we chose to represent are reasonably general, believed to be highly effective in at least some cases, and of particular interest to Rethink Priorities. We have avoided attempting to model many idiosyncratic or difficult-to-assess interventions, but that leaves the model radically incomplete for general evaluative purposes.
Distributions are a questionable way of handling deep uncertainty
We represent our uncertainty about parameters with distributions over possible values. This does a good job of accounting for some forms of uncertainty. To take advantage of this, users must take care to pay attention not just to mean values but also to the variety of results.
However, representing uncertainty with distributions requires knowing which distributions to choose. Often, when faced with questions about which we are truly ignorant, it is hard to know where to place boundaries or how to divide the bulk of the values. Representing uncertainties with distributions can give us a false sense of confidence that our ignorance has been properly incorporated when we have really replaced our uncertainties with a somewhat arbitrary distribution.
The model doesn’t handle model uncertainty
Where feasible, the CCM aims to represent our uncertainty within the model so as to produce results that incorporate that uncertainty. However, not all forms of uncertainty can be represented within a model. While a significant amount of uncertainty may be in the values of parameters, we may also be uncertain about which parameters should be included in the model and how they should relate to each other. If we have chosen the wrong set of parameters, or left out some important parameters, the results will fail to reflect what we should believe. If we have left out considerations that could lower the value of some outcomes, the results will be overly optimistic. If we’re not confident that our choice of parameters is correct, then the model’s estimates will fall into a narrower band than they should.
The model assumes parameter independence
We generate the value of parameters with independent samples from user-supplied distributions. The values chosen for each parameter have no effect on the values chosen for others. It is likely that some parameters should be dependent on each other, either because the underlying factors are interrelated or because our ignorance about them may be correlated. For example, the speed of human expansion throughout may be correlated with the probability of extinction by each year in the far future. Or, the number of shrimp farmed may be correlated with the proportion of shrimp we can expect to affect. Interdependence would suggest that the correct distribution of results will not have the shape that the model actually produces. We mitigate this in some cases by deriving some values from the parameters based on our understanding of their relationship, but we can’t fully capture all the probabilistic relationships between parameter values and we generally don’t try to.
Lessons
Despite the CCM’s limitations, it offers several general lessons.
The expected value of existential risk mitigation interventions depends on future population dynamics
For all we knew at the outset, many factors could have played a significant role in explaining the possible value of existential risk mitigation interventions. Given our interpretation of future value in terms of total welfare-weighted years lived, it turns out that the precise amount of value depends, more than anything, on two factors: the time until our successors go extinct and the speed of population expansion. Other factors, such as the value of individual lives, don’t make much of a difference.
The size of the effect is so tremendous that including a high expansion rate in the model as a possibility will lead existential risk to have extremely high expected cost-effectiveness, practically no matter how unlikely it is. Each of these two factors is radically uncertain. We don’t know what might cause human extinction assuming that we should survive for a thousand years. We have no idea how feasible it will be for us to colonize other systems. Thus, the high expected values produced by a model reflect the fact that we can’t rule out certain scenarios.
The value of existential risk mitigation is extremely variable
Several factors combine to make existential risk mitigation work particularly high variance.
We measure mitigation effectiveness by the proportional reduction of yearly risk. In setting the defaults, we’ve also assumed that even if the per-century risk is high, the yearly risk is fairly low. It also seemed implausible to us that any single project, even a massive billion-dollar megaproject, would remove a significant portion of the risk of any given threat. Furthermore, for certain kinds of interventions, it seems like any project that might reduce risk might also raise it. For AI, we give this a nontrivial chance by default. Finally, in each simulation, the approximate value of extinction caused or prevented is highly dependent on the precise values of certain parameters.
The result of all this is that even with 150k simulations, the expected value calculations on any given run of the model (allowing a long future) will swing back and forth between positive and negative values. This is not to say that expected value is unknowable. Our model does even out once we’ve included billions of simulations. But the fact that it takes so many demonstrates that outcome results have extremely high variance and we have little ability to predict the actual value produced by any single intervention.
Tail-end results can capture a huge amount of expected value
One surprising result of the model was how much of the expected value of even less speculative projects and interventions comes from rare combinations of tail-end samples of parameter values. We found that some of the results that could not fit into our charts because the values were too rare and extreme could nevertheless account for a large percentage of the expected value.
This suggests that the boundaries we draw around our uncertainty can be very significant. If those boundaries are somewhat arbitrary, then the model is likely to be inaccurate. However, it also means that clarifying our uncertainty around extreme parameter values may be particularly important and neglected.
Unrepresented correlations may be decisive
Finally, for simplicity, we have chosen to make parameters independent of each other. As noted above, this is potentially problematic: even if we represent the right parameters with the right distributions, we may overlook correlations between those distributions. The previous lessons also suggest that our uncertainty around correlations in high-variance events might upend the results.
If we had reason to think that there was a positive relationship between how likely existential risk mitigation projects were to backfire and how fast humanity might colonize space, the expected value of mitigation work might turn out to be massively negative. If there were some reason to expect a certain correlation between the moral weight of shrimp and the populations per inhabitable solar system, for instance, if a high moral weight led us to believe digital minds were possible, the relative value the model assigns to shrimp welfare and risks from runaway AI work might look quite different.
This is interesting in part because of how under-explored these correlations are. It is not entirely obvious to us that there are critical correlations that we haven’t modeled, but the fact that such correlations could reverse our relative assessments should leave us hesitant to casually accept the results of the model. Still, absent any particular proposed correlations, it may be the best we’ve got.
Future Plans
We have learned a lot from the process of planning and developing the CCM. It has forced us to clarify our assumptions and to quantify our uncertainty. Where it has produced surprising results, it has helped us to understand where they come from. In other places, it has helped to confirm our prior expectations.
We will continue to use and develop it at Rethink Priorities. The research projects module was built to help assess potential research projects at Rethink Priorities and we will use it for this purpose. We will test our parameter choices, refine its verdicts, and incorporate other considerations into the model. We also hope to be able to expand our interventions module to incorporate different kinds of interventions.
In the meantime, we hope that others will find it a valuable tool to explore their own assumptions. If you have thoughts about what works well in our model or ideas about significant considerations that we’ve overlooked, we’d love to hear about it via this form, in the comments below, or at dshiller@rethinkpriorities.org.
Acknowledgements

The CCM was designed and written by Bernardo Baron, Chase Carter, Agustín Covarrubias, Marcus Davis, Michael Dickens, Laura Duffy, Derek Shiller, and Peter Wildeford. The codebase makes extensive use of Peter Wildeford's squigglepy and incorporates componentry from quri's squiggle library.
This overview was written by Derek Shiller. Conceptual guidance on this project was provided by David Rhys Bernard, Hayley Clatterbuck, Laura Duffy, Bob Fischer, and Arvo Muñoz Morán. Thanks also to everyone who reported bugs or made suggestions for improvement. The post is a project of Rethink Priorities, a global priority think-and-do tank, aiming to do good at scale. We research and implement pressing opportunities to make the world better. We act upon these opportunities by developing and implementing strategies, projects, and solutions to key issues. We do this work in close partnership with foundations and impact-focused non-profits or other entities. If you're interested in Rethink Priorities' work, please consider subscribing to our newsletter. You can explore our completed public work here.
Excellent work. I've run out of good words to say about this Sequence. Hats off to the RP team.
I really like the ambitious aims of this model, and I like the way you present it. I'm curating this post.
I would like to take the chance to remind readers about the walkthrough and Q&A on Giving Tuesday a ~week from now.
I agree with JWS. There isn't enough of this. If we're supposed to be a cause neutral community, then sometimes we need to actually attempt to scale this mountain. Thank for doing so!
Thanks for doing this!
Some questions and comments:
- How did you decide what to set for "moderate" levels of (difference-making) risk aversion? Would you consider setting this based on surveys?
- Is there a way to increase the sample size? It's 150,000 by default, and you say it takes billions of samples to see the dominance of x-risk work.
- Only going 1000 years into the future seems extremely short for x-risk interventions by default if we’re seriously entertaining expectational total utilitarianism and longtermism. It also seems several times too long for the "common-sense" case for x-risk reduction.
- I'm surprised the chicken welfare interventions beat the other animal welfare interventions on risk neutral EV maximization, and do so significantly. Is this a result you'd endorse? This seems to be the case even if I assign moral weights of 1 to black soldier flies, conditional on their sentience (without touching sentience probabilities). If I do the same for shrimp ammonia interventions and chicken welfare interventions, then the two end up with similar cost-effectiveness, but chicken welfare still beats the other animal interventions several times, including all of the animal welfar
... (read more)Hi Michael! Some answers:
There will be! We hope to release an update in the following days, implementing the ability to change the sample size, and allowing billions of samples. This was tricky because it required some optimizations on our end.
We were divided on selecting a reasonable default here, and I agree that a shorter default might be more reasonable for the latter case. This was more of a compromise solution, but I think we could pick either perspective and stick with it for the defaults.
... (read more)That said, I want to emphasize that all default assumptions in CCM should be taken lightly, as we were focused on making a general tool, instead of refining (or agreeing upon) our own particular assumptions.
Hi Michael, here are some additional answers to your questions:
1. I roughly calibrated the reasonable risk aversion levels based on my own intuition and using a Twitter poll I did a few months ago: https://x.com/Laura_k_Duffy/status/1696180330997141710?s=20. A significant number (about a third of those who are risk averse) of people would only take the bet to save 1000 lives vs. 10 for certain if the chance of saving 1000 was over 5%. I judged this a reasonable cut-off for the moderate risk aversion level.
4. The reason the hen welfare interventions are much better than the shrimp stunning intervention is that shrimp harvest and slaughter don't last very long. So, the chronic welfare threats that ammonia concentrations battery cages impose on shrimp and hens, respectively, outweigh the shorter-duration welfare threats of harvest and slaughter.
The number of animals for black soldier flies is low, I agree. We are currently using estimates of current populations, and this estimate is probably much lower than population sizes in the future. We're only somewhat confident in the shrimp and hens estimates, and pretty uncertain about the others. Thus, I think one should fee... (read more)
Thanks for this!
In a separate comment I describe lots of minor quibbles and possible errors.
(1) Unfortunately, we didn't record any predictions beforehand. It would be interesting to compare. That said, the process of constructing the model is instructive in thinking about how to frame the main cruxes, and I'm not sure what questions we would have thought were most important in advance.
(2) Monte Carlo methods have the advantage of flexibility. A direct analytic approach will work until it doesn't, and then it won't work at all. Running a lot of simulations is slower and has more variance, but it doesn't constrain the kind of models you can develop. Models change over time, and we didn't want to limit ourselves at the outset.
As for whether such an approach would work with the model we ended up with: perhaps, but I think it would have been very complicated. There are some aspects of the model that seem to me like they would be difficult to assess analytically -- such as the breakdown of time until extinction across risk eras with and without the intervention, or the distinction between catastrophic and extinction-level risks.
We are currently working on incorporating some more direct approaches into our model where possible in order to make it more efficient.
I haven't engaged with this. But if I did, I think my big disagreement would be with how you deal with the value of the long-term future. My guess is your defaults dramatically underestimate the upside of technological maturity (near-lightspeed von neumann probes, hedonium, tearing apart stars, etc.) [edit: alternate frame: underestimate accessible resources and efficiency of converting resources to value], and the model is set up in a way that makes it hard for users to fix this by substituting different parameters.
Again, I think your default param... (read more)
I think you're right that we don't provide a really detailed model of the far future and we underestimate* expected value as a result. It's hard to know how to model the hypothetical technologies we've thought of, let alone the technologies that we haven't. These are the kinds of things you have to take into consideration when applying the model, and we don't endorse the outputs as definitive, even once you've tailored the parameters to your own views.
That said, I do think the model has a greater flexibility than you suggest. Some of these options are hidden by default, because they aren't relevant given the cutoff year of 3023 we default to. You can see them by extending that year far out. Our model uses parameters for expansion speed and population per star. It also lets you set the density of stars. If you think that we'll expand and near the speed of light and colonize every brown dwarf, you can set that. If you think each star will host a quintillion minds, you can set that too. We don't try to handle relative welfare levels for future beings; we just assume their welfare is the same as ours. This is probably pessimistic. We considered changing this, but it actually doesn't ma... (read more)
Thanks. I respect that the model is flexible and that it doesn't attempt to answer all questions. But at the end of the day, the model will be used to "help assess potential research projects at Rethink Priorities" and I fear it will undervalue longterm-focused stuff by a factor of >10^20.
I believe Marcus and Peter will release something before long discussing how they actually think about prioritization decisions.
AFAICT, the model also doesn't consider far future effects of animal welfare and GHD interventions. And against relative ratios like >10^20 between x-risk and neartermist interventions, see:
I have high credence in basically zero x-risk after [the time of perils / achieving technological maturity and then stabilizing / 2050]. Even if it was pretty low, "pretty low" * 10^70 ≈ 10^70. Most value comes from the worlds with extremely low longterm rate of x-risk, even if you think they're unlikely.
(I expect an effective population much much larger than 10^10 humans, but I'm not sure "population size" will be a useful concept (e.g. maybe we'll decide to wait billions of years before converting resources to value), but that's not the crux here.)
Hi Vasco,
What do you think about these considerations for expecting the time of perils to be very short in the grand scheme of things? It just doesn't seem like the probability of possible future scenarios decays nearly fast enough to offset their greater value in expectation.
Hello,
Rethink Priorities has noted CCM's estimates are not resilient. However, just for reference, here they are in descending order in DALY/k$[1]:
- Global health and development:
- Good GHD Intervention: 39.
- GiveWell Bar: 21.
- Open Philanthropy Bar: 21.
- Best HIV Intervention: 5.
- Direct Cash Transfers: 2.
- Standard HIV Intervention: 1.
- US Gov GHD Intervention: 1.
- Weak GHD Intervention: 1.
- Ineffective GHD Intervention: 0.
- Very Ineffective GHD Intervention: 0.
- Animal Welfare:
- Cage-free Chicken Campaign: 714.
- Generic Chicken Campaign: 714.
- Shrimp Ammonia Intervention: 397.
- Generic Black Soldier Fly Intervention: 46.
- Generic Carp Intervention: 37.
- Shrimp Slaughter Intervention: 10.
- Generic Shrimp Intervention: 9.
- Existential risk (the results change from run to run, but I think the values below represent the right order of magnitude):
- Small-scale AI Misuse Project: 269 k.
- Small-scale Nuclear Safety Project: 48 k.
- Small-scale Nanotech Safety Project: 16 k.
- Small-scale Biorisk Project: 8,915.
- Portfolio of Biorisk Projects: 5,919.
- Nanotech Safety Megaproject: 3,199.
- Small-scale AI Misalignment Project: 1,718.
- AI Misalignment Megaproject: 1,611.
- Small-scale Natural Disaster Prevention Project: 1,558.
- Exploratory Research in
... (read more)This is fantastic
Bentham would be proud
Here are some very brief takes on the CCM web app now that RP has had a chance to iron out any initial bugs. I'm happy to elaborate more on any of these comments.
- Some praise
- This is an extremely ambitious project, and it's very surprising that this is the first unified model of this type I've seen (though I'm sure various people have their own private models).
- I have a bunch of quantitative models on cause prio sub-questions, but I don't like to share these publicly because of the amount of context that's required to interpret them (and because the methodology is often pretty unrefined) - props to RP for sharing theirs!
- I could see this product being pretty useful to new funders who have a lot of flexibility over where donations go.
- I think the intra-worldview models (e.g. comparing animal welfare interventions) seem reasonable to me (though I only gave these a quick glance)
- I see this as a solid contribution to cause prioritisation efforts and I admire the focus on trying to do work that people might actually use - rather than just producing a paper with no accompanying tool.
- Some critiques
- I think RP underrates the extent to which their default values will end up being the defaults for
... (read more)Hi Derek,
CCM says the following for the shrimp slaughter intervention:
Does this mean the time in suffering one has to input after "The intervention addresses a form of suffering which lasts for" is supposed to be as intense as the happiness of a fully healthy shrimp? If yes, I would be confused by your default range of "between 0.00000082 hours and 0.000071 hours". RP estimated ice slurry slaughter respects 3.05 h of disabling-equiv... (read more)
Several (hopefully) minor issues:
- I consistently get an error message when I try to set the CI to 50% in the OpenPhil bar (and the URL is crazy long!)
- Why do we have probability distributions over values that are themselves probabilities? I feel like this still just boils down to a single probability in the end.
- Why do we sometimes use $/DALY and sometimes DALYs/$? It seems unnecessarily confusing. Eg:

- "Three days of suffering represented here is the equivalent of three days of such suffering as to render life not worth living."
- "The intervention is assumed to produce between 160 and 3.6K suffering-years per dollar (unweighted) condition on chickens being sentient." This input seems unhelpfully coarse-grained, as it seems to hide a lot of the interesting steps and doesn't tell me anything about how these number
... (read more)If you really want both maybe have a button users can toggle? Otherwise just sticking with one seems best.
OK, but what if life is worse than 0, surely we need a way to represent this as well? My vague memory from the moral weights series was that you assumed valence is symmetric about 0, so perhaps the more sensible unit would be the negative of the value of a fully content life.
Thanks for your engagement and these insightful questions.
That sounds like a bug. Thanks for reporting!
(The URL packs in all the settings, so you can send it to someone else -- though I'm not sure this is working on the main page. To do this, it needs to be quite long.)
You're right, it does. Generally, the aim here is just conceptual clarity. It can be harder to assess the combination of two probability assignments than those assignments individually.
Yeah. It has been a point of confusion within the team too. The reason for cost per DALY is that is a metric that is often used by people making allocation decisions. However, it isn't a great representation for Monte Carlo simulations where a lot of outcomes involve no effect, because the cost per DALY is effectively infinite. This has some odd implications. For our pur... (read more)
Great start, I'm looking forward to seeing how this software develops!
I noticed that the model estimates of cost-effectiveness for GHD/animal welfare and x-risk interventions are not directly comparable. Whereas the x-risk interventions are modeled as a stream of benefits that could be realized over the next 1,000 years (barring extinction), the distribution of cost-effectiveness for a GHD or animal welfare is taken as given. Indeed:
... (read more)Thanks. D'you have all the CURVE posts published as some sort of ebook somewhere? That would be helpful
Nice work! Are there plans to share the source code of the model?
Yes! We plan to release the source code soon.
Some ~first impressions on the writeup and implementation here. I think you have recognized these issue to an extent, but I hope another impression is useful. I hope to dig in more.
(Note, I'm particularly interested in this because I'm thinking about how to prioritize research for Unjournal.org to commission for evaluation.)
I generally agree with this approach and it seems to be really going in the right direction. The calculations here seem great as a start, mostly following what I imagine is best practive, and they seem very well docum... (read more)
Hi Derek,
I would be curious to know which organisations have been using CCM.
If I understand correctly, all the variables are simulated freshly for each model. In particular, that applies to some underlying assumptions that are logically shared or correlated between models (say, sentience probabilities or x-risks).
I think this may cause some issues when comparing between different causes. At the very least, it seems likely to understate the certainty by which one intervention may be better than another. I think it may also affect the ordering, particularly if we take some kind of risk aversion or other non-linear utility into accou... (read more)
Hi Derek,
For the animal welfare interventions, I think it would be nice to have the chance to:
Hi,
I have noticed the CCM and this post of the CURVE sequence mention extinction risk in some places, and extinction risk in others (emphasis mine):
Did you intend to use the 2 terms i... (read more)
Hi there,
Do you have distributions in th... (read more)
Hi,
Would it make sense to have Docs or pages where you explain how you got all your default parameters (which could then be linked in the CCM)?
Hi,
According to the CCM, the cost-effectiveness of direct cash transfers is 2 DALY/k$. However, you calculated a significantly lower cost-effectiveness of 1.20 DALY/k$ (or 836 $/DALY) based on GiveWell's estimates. The upper bound of the 90 % CI you use in the CCM actually matches the point estimate of 836 $/DALY you inferred from GiveWell's estimates. Do you have reasons to believe GiveWell's estimate is pessimistic?
I agree the distribu... (read more)
Hi there,
You model existential risk interventions as having a probability of being neutral, positive and negative. However, I think the effects of the intervention are continuous, and 0 effect is just a point, so I would say it has probability 0. I assume you do not consider 0 to be the default probability of the intervention having no effect because you are thinking about a negligible (positive/negative) effect. If one wanted to set the probability of the intervention having no effect to 0 while maintaining the original expected value, one could set:
- The n
... (read more)Hi, apologies if this is based on a silly misreading of outputs, but I was just trying out the CCM and choosing 'Direct Cash Transfers' gives:
How can the median ($1.54) be over 2 OOMs below the lower bar for 90% of simulations ($406.38)?
Similarly, the '... (read more)
Thank you so much for doing this! I guess I will end up using the model for my own cause prioritisation and analyses.
I agree with your conclusion that it is unclear which interventions are more cost-effective among ones decreasing extinction risk and improving animal welfare. However, you also say that:
... (read more)